Introducing Structured Data Types into Internet-scale
Information Systems
Introduction and Overview
Managing the increasingly large volume of information on computer
networks is rapidly becoming an important problem in computing.
The Internet, the largest wide-area computer network, is growing
exponentially in terms of hosts, users, and traffic. The NSFNet
backbone carried 14 Terabytes of data in March 1994; about half
of that was due to information services, such as FTP, Gopher, and WWW.
It is clear that a large supply and demand of information exists.
The form in which information is disseminated on the Internet, however,
leaves much to be desired. Most information has some sort of semantic
structure to it. It could be a text broken up into chapters and paragraphs,
a bus schedule showing routes and times, a city map displaying streets
and elevations, or a complex medical database. But while Internet
information systems may be able to transmit the data involved with
these pieces of information, they give little assistance in telling
how the data is structured.
The semantic structure of information makes a large body of information
much more manageable. Knowing the meaning of a type of
information helps one extract, derive, compile, and condense useful
information from a larger set of raw data. It helps in searching
for relevant information, and in intelligently filtering out irrelevant
information to a query. In these tasks, it is not enough to simply
know that a piece of information is composed of several components; ideally,
one wants to be able to know the meaning of the components, and what one
can do with the parts. A search of card catalog entries, for instance,
may need to know how to extract the author of an entry, and compare
the author's name against a search term.
In the Internet, there is little support for semantically structured
information. A particular application, such as a library catalog, may
define a certain format for their book entries, which may be semantically
rich, but only meaningful to programs specifically written to understand
that format. A client program written to read University A's card
catalog may be able to make no sense of University B's card catalog,
even though both are available on the Internet.
In contrast, applications that want to share their information widely are
generally forced to use a lowest common denominator approach. The most
common such denominator is plain unstructured text. Frequently used
applications may, over a long period of time, settle on higher-level common
denominators, such as RFC-822 mail messages, or GIF image formats, or
documents formatted with TeX or HTML. But these higher-level formats
still lack much of the semantic structure many applications need; and the
process of finding a usable common standard even for these formats can
take years. (Then, in a few years more, these formats are often replaced
by other, incompatible formats.) The rate at which new data types
can be introduced and used in an Internet context is far too slow, and
cannot be made much faster with current standards procedures.
How can information be provided on the Internet at a higher semantic
level, while remaining usable by a large number of information clients?
Two observations are relevant here:
- The concept of abstract data types, or of "objects",
provides a solution to many of the complexities of data formats
and operations. Abstract data types provide a well-defined
interface of operations and attributes, so that a client can
use a complex datum without having to know how it is formatted,
or how operations are implemented. Indeed, a number of systems,
such as CORBA, [OMG92]
already attempt to implement an object-oriented
system distributed over the network. None have yet, however,
been able to cope with the scale and heterogeneity of the Internet.
This is in part because they are designed for general-purpose
computing, which includes both reads and writes. They therefore
have to worry about issues like consistency of data updates,
fault tolerance, and a fairly uniform semantic model for
references and meta-data. These problems are much less
relevant (and sometimes impossible to solve) in a system designed
for disseminating information widely, rather than mutating it.
- A very large body of knowledge and computing power is already
available in the information agents (clients, servers, and mediators)
that exist on the Internet. At present, most agents dealing
with information are set up in a few standard ways; most commonly,
a client operated by a user will contact a server maintaining a
database, and fetch a datum from the database directly. In occasional
variations, a "server" may act as a gateway to a database another
server maintains; or a fixed data type conversion program may be
run off-line by a client or a server. These types of interactions
are useful but limited. Human "agents" commonly use richer techniques
to discover information: they collaborate with "experts" in a particular
domain in order to find relevant initial information in a domain, and
for assistance in gathering and understanding that information.
Similar techniques for computerized agents could be quite useful as
well, in particular "mediators", third-party experts suggested by
Wiederhold in [Wie92].
I propose to make an explicit object-based level of abstract data usable
in Internet information systems. Widespread use of such abstract data
requires that new types be definable anywhere on the network, and not
simply by some central standards authority. Furthermore, in order for these
types to be used, information about these new types, and operations on those
types, must be available to other agents which request it. This requires
not only support specifically for abstract types, but also a well-defined
interface for agents to talk to each other about types and operations; and
some standard method to provide information about types, their
operations, and their relations.
I claim that these requirements can be satisfied with a two-level
software architecture. The upper level focuses on the data being shared,
and the abstract operations being carried out on it. At this level,
methods are invoked; object references are resolved; new data types
and operations are defined. (See figure 1b.) The lower level focuses on the agents
supporting these operations. Here, agents request other agents for
data objects or references, carry out abstract data operations on
behalf of other agents, and encode and decode concrete representations
of abstract objects so that they can be passed through the network.
(See figure 1a.)
This level abstractly describes what is already carried out (in
a domain-specific manner) by the protocols of many existing Internet agents,
such as HTTP [BL93]
servers, Domain Name Service [Moc87] resolvers,
or WAIS [Kah91] indexes.
(Information from these existing systems
can also be incorporated into the higher-level information
system through the use of "wrapper" or "gateway" agents, which provide
explicit abstract types for the implicit data abstractions these systems
support.)
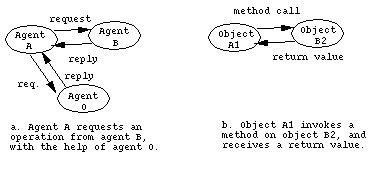
Figure 1. The two levels of abstraction in an information system.
To bridge these two levels of abstraction, the agents need to know
about the types of objects they are manipulating. For this purpose,
I propose a special mediator agent that can give information
about types of information in the network. A client or a server can
contact this agent (which I call a type oracle) to find an agent
to carry out a defined operation
on a data type, or to find out how information of one type or encoding can
be converted into another type or encoding. Someone who wishes to
define a new data type or encoding can register it (and its operations)
with a type oracle, which can then share this information with other
agents, including other type oracles. Oracles can also use their
knowledge of the lattice of types and encodings to derive new transformations
not provided by any single agent (such as a conversion from type A to type C
that uses a converter from A to B followed by a converter from B to C).
A few questions arise at this point: Can a coherent information system be
built to this design? Will the design really give widely-distributed
information systems more semantic power? Will it be useful for real
applications, or will it introduce too much
overhead (either in response time to queries, or in the amount of work
a client or provider is expected to do) to be feasible? Will it be able
to interoperate with existing information systems?
I propose the
following course of action to answer these questions:
- First, I will analyze existing information systems that are
already in use over the Internet, such as Gopher, World Wide Web,
and the Domain Name System. The objective of the analysis will be
to show the common features of these systems, show how their data
and agent abstractions can be interpreted (at least implicitly)
in terms of the architectural model given above, explain why
they have gained frequent use in the large-scale, heterogeneous
environment of the Internet, and discuss problems and limitations
of these systems. Some analogs in distributed systems and
object-oriented databases will be considered as well.
- Second, I will make a detailed design of an information system
based on the architecture I proposed, and build a prototype
implementation. This will include a number of information
agents using a common toolkit; a type oracle; a collection of
data types and encodings supported by the agents and the oracle;
and protocols to allow the agents to work together and operate
on the types. This will demonstrate that the design is feasible,
and that it can handle a reasonable-sized repertiore of common types.
- Third, I will test the implementation. This will involve
one or more case studies, where I choose a particular information
gathering problem (such as a distributed library research problem,
or a software engineering information search) and show how
my system makes it significantly easier for agents to be built
to allow clients to find useful information than existing systems do.
It will also involve observation of a less controlled test: releasing
the design and implementation to users on the Internet. This will
allow me to see if disinterested users find value added in my
approach, and also find where difficulties arise in practice with
the system.
Recap: Key Concepts
The key concepts of the thesis, then, are these:
- An information system architecture using typed, replicating objects
to model information, with an underlying agent communication protocol.
- Use of mediator agents ("type oracles") to maintain information
about an ever-growing lattice of types, and to assist agents that
want to use these types.
- Encapsulating existing data on the Internet with structured types
and encodings, allowing it to be used in higher-level architectures.
Of these, the type oracle should be the primary contribution of the thesis.
In the remainder of this proposal, I describe in more detail
the rationale for my research. I will explain my work's relation to the
current state of the practice in Internet information gathering,
and to distributed computing concepts.
I will outline the basic abstractions of my architecture, and
explain the problems they address and some of the problems involved
in using them. I will describe some relevant related work by others.
I will describe my plan of research, tell how long I expect my activities
to take, and describe what contributions I expect these activities to make.
Internet Information Systems: Uses and Problems
As noted in the introduction, the Internet is rapidly becoming
a widely-used medium for exchanging information. Many
applications proposed for networked information systems imply a
rich structure to this information.
For example, a medical researcher may want to examine blood pressure
readings from a clinical sampling and correlate them to heart attack
occurrences, using the structure of patient medical histories. A
scientist may want to find books in several libraries about plate tectonics,
using catalog entries and search indexes. A software engineer may wish
to find and examine C++ modules for processing SQL queries, using
the structure of program archives and descriptions.
In an ideal world, such tasks would be simple to carry out effectively.
But they remain difficult or infeasible in today's Internet,
due in part to limitations of the net's current model of information
space. Among these limitations:
-
The conceptual structure of information space is hazy:
Experienced users often have
trouble not only with finding information they are interested in, but even
with finding out what information exists on a subject they
are interested in. The software engineer in the previous
example, for instance, may not know where to search for C++ modules
in the first place, let alone ones that have anything to do with SQL.
Various indexing schemes have been proposed to make a better
conceptual map of cyberspace, but there is no clear consensus yet
on what kinds of indexes to use. With no common formats,
common semantic bases for indexing, or general mechanisms for
relating one indexing scheme to another, indexing
schemes will remain primitive and incomplete.
-
The structure and encoding of information objects is
often inappropriate for applications:
A large corpus of information, even an explicitly structured one,
may still be useless to someone who lacks the knowledge
or computing power to sift through the information to find relevant
facts or derive or synthesize needed knowledge. Theoretically, one
form of information may have information content equal to (or even
greater than) another, but still be much less useful in a practical
sense. If, for instance, the only interface to medical records returns
plain text in various formats, it can be prohibitively difficult
to extract appropriate information about blood pressure and heart attacks.
Current practices encourage information providers to provide information
either in a lowest-common-denominator form, or in a form specifically
tuned for a single application. Both of these inhibit useful information
sharing.
-
Maintaining useful information sources is difficult:
It is relatively easy in many cases to put some information on-line
and offer it to the world. It is much more difficult to keep the
data current and the format relevant. Part of this problem is related
to the previous one: it is extremely difficult to define new formats
and types of data without having client applications explicitly reprogrammed,
or maintaining a number of gateways or alternate repositories for
different formats understood by clients. Mediators can conceivably be used
to update data automatically and provide gateway services, but they
require well-understood interfaces to work in a general context.
Computation models: The need for abstract types: A number
of the problems above can be solved in part by better computation models
for internet information systems, in particular, abstract types. Some
benefits of abstract type systems:
- They provide an appropriate level of abstraction for data manipulation.
Client programs can be written
in data-driven terms like 'search this index using these attributes'
or 'retrieve the object referred to by this attribute', without
needing to know the full details of the data implementation.
- They provide a useful model for taking advantage of the expertise
of a network of agents. In today's information systems,
the burden of computation and type decoding falls entirely on
the client, or on the server providing data.
But in models using abstract data objects,
operations manipulating information are associated with the data types,
rather than any particular agent. Knowledge
about how to operate on the types can be delegated to sites that
define the type, or have been told the type definition.
- They provide a vocabulary for information about
new data types and formats that is independent of representation or
implementation concerns. Thus, information systems do not have to settle
for a lowest-common-denominator approach for information exchange, nor
do they need to settle for a fixed repertoire of types and operations.
The structure and semantics of different search indexes, for instance,
can be described and related via different abstract types.
In the next section, I will look briefly at two communities working
towards usable wide-area data types: the distributed computing community
and the community of developers of existing Internet information systems.
By examining the strengths and weaknesses of their approaches, I will
lay the groundwork for an architecture combining features from both
communities.
Distributed computing perspectives
The distributed computing community has already proposed or implemented
a number of systems for distributed objects. If abstract
data types are so useful for distributed information systems, then,
why hasn't one of these object systems taken over cyberspace? While
immaturity of these systems may be one possible reason, another
important reason is that the applications these systems are designed
for are different in important ways from information dissemination
applications.
Why existing distributed computing models aren't sufficient:
Distributed computing researchers have long been aware that
computing over multiple machines introduces many new problems
not present in a single address space:
- Data-related problems. An arbitrary distributed
process may need to have strong guarantees about the consistency of the
data it manipulates. But in a large-scale heterogeneous system, it can
be very difficult to keep data consistent without locking up
arbitrary servers for unacceptable durations. This is unacceptable
in a wide-area information system.
- Operation-related problems. In an undistributed
application, a request for an operation can be made with a simple
procedure call.
In a small-scale distributed application, the operation may involve a remote
procedure call, with some conventions for encoding parameters, carrying out
the operation, and returning results. In a large-scale
distributed world, not all agents are known, and communication channels
and agents, and their semantics, are out of the control of any one
person or project. So even more complications arise.
It may now be relevant,
for instance, for a server to know who invokes an operation,
or for a client to know the cost of an operation.
New modes of failure and recovery strategies may be called for (since
permission to carry out an operation may be denied, a remote
server is not available, or the return type is unexpected).
The role of meta-data to evaluate the results of an operation
becomes more critical.
These are symptoms of
the greater level of heterogeneity introduced by scaling up a
distributed application to the Internet world. Languages, operating
systems, data types, and ways of organizing data and software vary
(both over different servers and over time)
more widely than most distributed systems are designed to handle.
How existing Internet infosystems are different
Fortunately, because their application domain is limited, Internet
information applications do not have to solve all the problems inherent
in distributed computing. In particular,
the information delivery task can be simplified by the following
domain assumptions:
- The predominant flow of
information is one-way. Information is
originally provided by certain sources acting in server roles,
and then retrieved, transformed, and used by other agents acting
in client roles.
Read access to information is widely available, but write
access is not available, or severely limited. (Clients can transform
the values they receive, but cannot mutate the source data themselves.
Some information systems allow clients to send back requests to
change or add to the data a server provides, but these changes, if
made at all, are done locally by the server, outside the scope of
the information retrieval application.)
This assumption avoids many of the complications of general-purpose wide-area
database systems.
- Also, in many Internet applications, changes in
information do not have to be propagated immediately.
Conventional database systems take great pains to make sure
that query responses use the latest available version of a set
of data, and that the set of data given is internally consistent.
In many wide-area information applications, these kinds of guarantees
are either prohibitively costly, or flatly impossible. Fortunately,
many applications do not need these sorts of guarantees; or can
make do with simply knowing roughly the consistency or currency
of information. And in many systems, mutations of information occur
significantly less frequently than accesses to information. (And
with some types of meta-information, such as information about
types and resources, information tends to accumulate but not mutate.)
Relaxing currency and consistency requirements gives
third-party agents a useful role in an Internet information system.
An agent can provide information originally supplied by another agent
without necessarily having to verify that the original agent's information
has not changed. It can synthesize information based on data from several
agents. It can derive or transform the information for a client in ways
the original server might not be able or willing to do.
How existing Internet infosystems handle datatypes.
Many Internet information systems have found it useful to define
their own semantic types. Gopher, for instance, uses menus and
bookmarks to let users navigate. The World Wide Web (WWW) [BL+92] uses
simple structured hypertext documents to navigate through the system,
and defines a data type (HTML) for these documents.
While these types are more useful than the simple ASCII text used
to encode them, users of these systems soon want more structured types.
For example, a number of WWW sites have "What's New" pages in HTML, which
invariably consist of a list of dates, resource descriptions,
and links to the resources, in reverse date order (and sometimes
spread out over several documents). This format convention reflects
a new 'abstract type' to the human client. But this type cannot be
easily used by programs (though it might be convenient for some of them)
because the information system provides no way to describe the new type
in a well-defined way. A standards body might incorporate it into
a later revision of the information system, but if this occurs at all,
it will take a very long time.
An example.
Even with a relatively small, simple set of types, agents may have
difficulty exchanging information, as shown in the following example.
Suppose that a client program on a Macintosh has a reference to an image
it wishes to display.
Retrieval of the image is simple enough in many Internet infosystems:
The client examines the reference to see what server it should contact,
talks to the server with the appropriate protocol, and gets the image
shipped to it for display. The World Wide Web, Gopher, and even
anonymous FTP are all capable of doing this.
But can the client do anything with the information it retrieves?
Suppose that the image is stored on a Unix-based server at a remote
university. The image is saved there in X bitmap format (xbm),
and has been compressed with GNU-zip to make it easier to store,
and quicker to ship. This format and encoding makes sense for
the Unix environment where the picture is stored, but may not be useful
to the client. The Mac client, for instance, may know how
to display GIF images, for instance, but not know anything about
XBM images (a similar type, but with a different color model and encoding).
And the GNU uncompressor may not be available on the Macintosh.
The conflict in data types must be resolved if the
two agents are going to interact meaningfully. First of all, at
least one agent must realize the nature of the conflict.
(A naive client program might
blithely assume everything is going well, and display the unknown-format
image as gibberish-- or worse, crash when it tries to display the
image.) If the client can tell what kind of information
the server is sending it, it can detect a problem, and possibly
convert the data to a form it can operate on. Or, the client may
tell the server up front what data formats it can deal with, and the
server can convert the data appropriately.
Existing systems have these capabilities, but only to a limited extent.
When Gopher and WWW servers ship data, they also send meta-data
identifying the type of the data they ship. The World Wide Web's HTTP
servers also allow a client to send a list of types it will accept. The
vocabulary of types one can talk about is limited; in Gopher's case, to
a set of single-character codes set by the Gopher developers; and in
the Web's case, to the MIME type set. MIME's type repertoire
(described in [BF92]) is richer
than Gopher's, and allows people to use their own 'experimental' type
names outside the standard type repertoire, but all parties in a transaction
must have a common understanding of the experimental types used. Also,
MIME's encoding repertoire is small and fixed, so that 'GIF' and
'compressed GIF' need to be expressed as two different types in the
MIME system. (Web developers stretched the MIME convention to add new
encoding types, so as to avoid the combinatorial type-expansion problem
arising with different data types having different compressions. But
the problem resurfaces with two or more levels of encoding, which is not
uncommon.)
Why third party agents are useful.
But there is a more fundamental problem to these systems than
limited vocabularies for types and encodings. Even if the client
knows the kind of data it gets, and the server knows what kind of
data the client wants, one of the agents has to know how to adapt
to the other. In the image-fetching example,
one of the parties has to know how to convert the data from
the server's format to the client's format.
If they don't have enough knowledge among themselves to do the conversion,
the agents are stuck-- even though
an agent somewhere else in the network may be able to supply this missing knowledge, or do the required conversion.
Third parties can be useful not only for type conversion, but also
for abstract operations on types. For instance, if for some reason
the client wanted the image not for display, but simply to get
some information from it (such as its dimensions, or a string corresponding
to text characters embedded in the image), a mediator
could be enlisted to carry out the operation and return the results to
the client. Conversion might not be necessary at all.
Basis of a more powerful architecture
To some up, then, there are two basic requirements for an interet-wide
system to handle structured types, that are not adequately addressed
in existing information systems. These are:
- 1.
- Ways to define and describe inter-agent operation at a higher level
than simple client-server interaction with a fixed protocol. One should
be able to publicize the servives an agent provides
for data and operations, and the agents should be able to negotiate
with clients to carry out
these services. There needs to be a way of discovering particular
agents for a needed task.
- 2.
- Ways of talking about the data types, encodings, and associated
operations that these agents handle. In a large, distributed
internet, new types, encodings and operations will be
introduced all the time. But this is not an unfamiliar problem.
The universe of information objects on the Internet is large
enough that the futility of central administration of the objects is
obvious. Instead, infosystems designers have come up with decentralized
ways to distribute and refer to the objects. The
solutions (such as the Web's URL scheme, which specifies the access
method of a particular Net object) are not perfect, but do currently
provide a workable way to find objects in many cases.
Likewise, with rich enough conventions for talking about types, new
abstract types and operations can be brought into the Internet and used,
without having to wait for some centralized standards body to act.
Statement of thesis. These two architectural concepts
are related very closely. A well-defined system for talking
about types and operations provides a rich framework in which agents
can interact. And an agent that is an expert in cataloging and handing out
type information allows new operations (and types) to be defined
in a distributed manner.
This agent, the type oracle, has a protocol that
allows agents to request services and discover information
about new abstract data types. (It can, for instance, identify new types
in relation to known types, and can find other agents to carry out
needed operations or conversions on unknown types.)
My thesis, then, is this:
A model of distributed information systems allowing
individual information providers to define and share their own
abstract structured types is feasible, and will make Internet information
systems significantly more powerful.
A distributed network of type oracles,
combined with a flexible naming, subtyping, encoding, and inheritance scheme,
will allow these structured types to be introduced and used by
a variety of information agents.
In the sections to follow, I will describe how I plan to investigate
and test this statement. First, I describe some of the details of
a design which supports this model, to demonstrate how such a
system could be designed and built. Then, I will describe how the
system relates to other work in similar fields. Finally, I will discuss
the specific activities I will undertake to complete the thesis, and
the contributions that I expect to result.
The design of an Internet information object system
In this section, I will discuss the key abstractions
in a design for such an Internet information object system,
explain how and why they would be used, and discuss how they
should be implemented in a workable system.
The major abstractions discussed here are
objects, agents (and their computation model),
and type oracles. References and meta-data will also be addressed.
Since one goal of my system is to interoperate (at least to some extent) with
these systems, I will also discuss, where appropriate, how some of
these abstractions relate to existing information systems.
Objects: Abstract types, encodings, and operations
What objects are.
The system I propose represents information in the Internet as
objects, which are instances of
abstract types.
Each type is identified by one or more well-defined names.
Objects are used through operations or methods, whose
names and signatures are available in the type declaration, as with
many object-oriented languages.
Objects may also have a set of attributes, which may be
retrieved, or sometimes set, via an operation. Types may also have
expected semantics; for instance, one type's "angle" attribute
may be expected to always be a number between 0 and 360.
Objects are used by invoking operations or reading attributes in
the manner of a procedure-call (or remote-procedure call).
A type
may have one or more supertypes.
Objects of one type support the operations of the type's supertypes,
and can 'stand in' for the objects of the supertype if necessary.
Inheritance is not implied by subtyping, though, for reasons to be shown later.
Objects in a heterogeneous wide-area infosystem.
So far the object model should look quite similar to traditional
programming conventions. There are two important additional
aspects of the model, though. One is that objects can have
meta-data associated
with them, showing their origin, type, or other run-time
information. This sort of information is usually handled transparently by
the environment in traditional programming languages, but is made
more explicit here, for reasons we will see later.
Another important aspect of objects in this system is that they may have
encodings. Encodings are used to transmit object instances from
one agent to another.
They may also be used in the implementation of an object operation.
Encodings are similar to the representations of object-oriented
programming languages, but they are not opaque: agents with a copy
of the object can work directly with its encoding, if they know how.
An encoding specification
includes a lower-level type used to represent the object,
and a named scheme used for translating to and from this type.
For example, a HTML document may be encoded as a sequence of characters,
using its standard SGML representation as its encoding scheme. An encoding
itself may be encoded, since it too is an instance of an abstract type.
A given object
type may have several encodings associated with it, and subtype
encodings need not have anything to do with supertype encodings. (This
is one reason why subtyping does not imply inheritance.)
An object will eventually be encoded in a 'primitive' type, which
could be as simple as a sequence of bytes. (At some level, all
Internet information gets transmitted in this form; though agents
might treat higher-level types as primitives as well.)
Objects in existing infosystems. If one considers
a byte stream to be a simple object (with operations like 'next-byte'),
all Internet information systems can be modeled with objects, but this
model is degenerate and uninteresting. But the formats of the data
types used in information systems can be treated as encodings of
abstract types. They can thus be incorporated into an object-based
information system via an agent that provides an object wrapper around
the encodings. (Rufus [Sho+93] essentially
does this for its "semi-structured files".)
An HTML document in the World Wide Web, for instance,
could be viewed as an encoding of a "Web-hypertext" object, with methods
like "follow the first link" or "fetch the title".
Information agents
Information agents are programs that operate on information objects.
They can talk to other agents in the Internet, operating
in a client or a server role (and sometimes in both roles).
In my design, agents know of a certain set of types, as well as a
set of definitions of operations on these types. These definitions
might include one or more of the following:
- Code for the operation (for at least some encodings)
- Reference to another agent that can do the operation
- Knowledge of the operation's existence and implementation.
(A type oracle is then queried to find an agent that
can carry out the operation)
A particular agent might only implement an operation for
certain encodings of a type. The same code may be used
by several implementations. This allows for a certain degree of code
inheritance, if desired.
Agents have a repository
of objects they have direct access to,
without having to talk to other agents.
The 'same' object may be in several agent repositories at once,
since when a server 'transmits an object' to a client, it actually
transmits a copy of its encoding.
If clients are particularly concerned about
consistency, meta-data can be used to identify the agent originating
an object.
Interoperation with other agents: the computation model.
In my design, agents speak a common protocol about objects, types,
and operations. To carry out an operation on an object, an agent may
make requests to one or more servers that have knowledge of the object,
its type, or its operations.
Agents may also know special-purpose protocols to talk
to databases and clients that don't talk the common protocol directly,
such as HTTP servers or SQL databases. There may be multiple
protocols used to carry out similar operations, depending on the
performance requirements of an application, but my thesis will concentrate
on a single protocol that's robust enough to be usable in case studies
in the later part of my thesis. In any case, changes in the required
protocol should be much less frequent than changes in the set of
data types.
In my basic protocol, agents use a request-reply interaction similar to that
of remote procedure calls. (While a simple agent might
actually implement the request and reply as a procedure call, nothing prevents
an agent from having requests pending on multiple agents at once, if
that is desires for efficiency.) Client agents can make multiple requests
in the same session, but state (other than that inherent in the information
repository) need not be preserved between different sessions, and should
be kept to a minimum within a session. This has helped keep the interactions
of existing infosystems simple. Mutation of the repository is not a part
of the protocol, so concerns like serializability are not an issue.
The type oracle and its services
What type oracles do.
A type oracle is a mediator agent that provides information about
structured types to information agents, and to application programmers.
Given the name of a type, a type oracle can find its description,
its supertypes, operations, methods, and encodings. It can refer
clients to agents that can carry out requested operations or conversions
between types, or between encodings. It can take advantage of its
knowledge of the type lattice to perform conversions and substitutions
that are not explicitly coded by any single agent. (For example, if
a client has type encoding A, and needs to convert it to B, it can find
a converter from A to C, and another converter from C to B. See figure 2c
below.) Earlier research (such as the data translation work of
[Mam+89]) has revealed algorithms for some
of these tasks, but there are still a number of open algorithm questions that
can be studied in the thesis.
Why type oracles?
Type oracles simplify the problem of managing large numbers of abstract types.
Their ability to locate third-party expert agents for a type allows
information clients to use many more types (and operations) than those
they were explicitly coded for. They also avoid the requirement in
many distributed systems that there be a single agreed-on form for all types
(figure 2a below), without requiring explicit conversions from every
type to every other (figure 2b below).
Type oracles can use meta-data associated with conversion operations to
direct type conversions or operations that preserves as much
information as is necessary and feasible. Some types of conversion require
no information to be lost; others require that certain operations or
expectations are possible, even if this means the loss of extraneous
information.
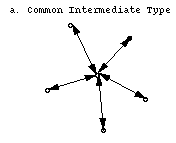
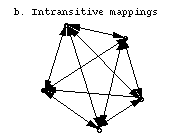
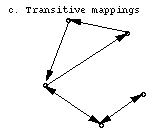
Figure 2. Different models of type conversion
Multiple type oracles.
A full-blown Internet information system will have multiple type
oracles. Oracles can query other oracles to find out about new types.
(Conversion and substitution strategies will work best if
a given oracle knows about as many types and mappings as possible.)
A given type can be kept private (as one might wish to do while
developing and testing it) by registering it with a local oracle,
but instructing the oracle not to give information about it to outside
oracles or agents.
How types can be used with meta-data and references
Meta-data and references are both essential parts of
a wide-area information system. In a system where structured information
is passed between agents that may not know each other, data
may need to be accompanied by tags identifying the type of data.
Type tags, however, are not the only kind of meta-data which may
be needed: information about the source, currency, and cost of
information, for instance, may be desired as well. References are
required whenever a piece of information wishes to name or point to
another piece of information. They may also be required for
efficiency, when it is not practical to ship a large block of data
from one site to another.
Meta-data and references as abstract types.
There is, however, no universally adopted mechanism to name
objects in information systems. (Finding adequate naming schemes
in heterogeneous distributed systems is in fact an open problem,
one that this thesis will not attempt to solve in the general case.)
There are, however, a number of naming schemes with varying semantics
(such as the URLs of the Web, the semantic filenames of Prospero
[Neu92],
the domain naming scheme of the Internet, and the Message-IDs of Usenet).
The abstract types model I propose can be used to distinguish and
classify the various naming schemes in use on the Internet. Similarly,
as new forms of meta-data become necessary, new abstract types can be
used to model them. Thus, a wide variety of data, from both existing
infosystems and new infosystems, can be used in this framework.
Minimal meta-data and reference requirements. While
I do not intend to investigate all of the possible types of meta-data
and references in my thesis, I will have to design a few required for
the system to operate. For instance, basic forms of reference to
other agents must be supported. Meta-data containing type tags will
be needed to effectively use type oracles. And the names of types
themselves are references that require certain semantics (particularly
persistence, unique identification, and resolvability) and namespace
management. My thesis will include provisions for these basic types
in the protocol or in the basic type lattice.
Image example revisited
How will these abstractions work together in actual use? We return
to the image example from the previous section for an illustration.
The client starts out with a reference for an image it wishes to display.
It resolves the reference (perhaps with the help of another agent), and
contacts a server that holds the image in its repository.
The server passes the client meta-data indicating that the picture is of
type X-Window-Dump (a subtype of Image), and encoded in the standard XWD
format, further encoded with GNU compression. Since the client does
not know to implement the Display operation for this format,
it asks a type oracle for help in displaying it as an Image.
The Display operation cannot
be executed remotely, so conversion is required. The oracle
tells the client that the image can also be converted to other subtypes,
one of which is the GIF type the client understands. The client
can display GIFs, so it uses the type oracle to find agents that will
do a conversion out of GNU compression, and then from XWD to GIF. An
uncompressed
GIF-format image is finally sent to the client, which it then displays.
The example above elides a number of details that need to be tuned
carefully in an actual implementation. The strategy for negotiation
between agents is left unspecified, as is the strategy for when to
send data, and to whom. (Bandwidth may be saved, for instance, if the
initial client request to the server returns meta-data but not
the actual image data, assuming the image is large.) While I suspect
that different strategies may be appropriate for different applications,
I hope to discover useful general strategies for agent interaction
in my thesis.
Having completed an overview of my design, I now discuss the relationship
of my work to work in related areas.
Related work
Research projects in a number of areas have direct relevance
to my thesis. A detailed analysis of this work belongs in the
thesis proper rather than in the proposal, but the following categories
of related work (some already mentioned) are worth noting:
- Distributed objects: A number of groups
have extended the ideas of remote procedure calls and proposed or
created systems where object methods can be invoked from arbitrary
machines over a network. The CORBA proposal [OMG92]
of the Object Management
Group is probably the best-known instance; its core Object
Request Broker standard is available today. CORBA's goals are in
some ways more ambitious than the object system I propose, since
the system is meant for general-purpose distributed programming.
Certain essential features of the proposed Internet infosystems
architecture may be hard to implement in this system: in particular
the migration and replication of objects is not part of the CORBA model.
CORBA's proposed "interface repositories" may contain some of the same
information that a type oracle would, but the repositories are passive
and not designed for global use. Nevertheless, this system is worth
watching, since it has many similar goals, and is supported by numerous
manufacturers.
- Systems with type expertise: Some other
information systems have agents that are
knowledgeable about new types. Rufus [Sho+93], a system developed at IBM
Almaden to manage semi-structured information on a site-wide basis,
includes a type expert called a classifier, which constructs structured
objects as proxies for unstructured data files. The classifier analyzes
the file contents to select a type to use for constructing the object.
A Rufus followup paper [SS94] describes an algorithm that allows the
classifier to learn to classify a possibly arbitrary number of new types.
A Rufus classifer, then, can be thought of as
a particular kind of 'type oracle' whose expertise is converting a
type encoding (a semi-structured file) to a particular abstract type.
Rufus, however, is designed for a single site, and in its current
form does not scale up to Internet-wide information systems.
- Extendable types: Most distributed programming
systems, such as distributed object systems, allow a theoretically unlimited
number of structured data types. They typically lack general run-time
services to assist in using with new data types, though, so it is difficult
for applications to use types other than ones known about at the time of
program creation.
A number of systems, however, give more support. Rufus's classifier
has already been cited; its type conformance and revision model, where
an arbitrary number of implementations can exist for a known type, also
provide support for new types. SGML, a well-known text markup
convention described in [AAP86] and elsewhere,
allows syntactic descriptions of new data types (known as DTDs)
to be passed along with data objects, so that arbitrary applications can
parse them, as long as the object format follows certain basic markup
conventions. The DTDs do not, however, give semantic support for the types.
- Agent Cooperation: Information systems involving
cooperative agents have existed for a long time. The modern Internet
depends heavily on one such system: the Internet Domain Name System servers
which manage information on a hierarchical name-space of hosts. Many
research systems also have agents cooperate for a specific purpose.
One example in a particularly relevant domain is Indie
[Dan+92], which
consists of a network of index agents dispatching
requests and trading new search index records based on the published
specialties of each agent.
While the ways in which agents cooperate is
application-specific in many systems, systems have also been built to
handle more general cooperation strategies. ISIS
[Bir92], for instance,
provides fault-tolerance guarantees for agents organized in "process groups",
though it says relatively little about the data model the agents use.
- Heterogeneous information retrieval:
In designing a new information architecture, one cannot overlook one
reason that systems like Gopher and WWW have gained so much acceptance:
they allow a wide variety of popular information formats to be served
via several common protocols. The World Wide Web can theoretically
include an arbitrary number of types, but since the only generally understood
way to refer to types at the moment is through the MIME typing system,
its adaptability is limited. Some research systems, such
as Rufus, also allow data in many different formats to be exchanged
intelligently, due to the classifier mechanisms mentioned earlier.
- Software architecture:
Software architecture research provides
useful frameworks for understanding and designing distributed information
systems. In [Abo+93], Abowd, Allen and Garlan
describe a useful language for
discussing software architectures in terms of components and connectors,
and in terms of particular "styles" of component types and connector
interactions that characterize particular kinds of architecture.
(This description is refined further in [AG94].)
The description of Internet information systems as agents (components)
interacting via a common protocol of abstract data operations (the connectors)
fits well into this
language. The particular data abstractions described in the previous
section could be thought in a general way to describe the style of Internet
information system architecture, though most of Garlan and Allen's
work on style has concentrated more on protocols and computations than
on data abstractions.
The notion of a reference architecture is also a useful one
for building and analyzing information systems. Reference architectures often
have several purposes: they can describe the basic abstractions and
building blocks that are used in a particular application domain, and
provide a basis for comparing different systems in the domain; or they
can try to describe a basic "common demoninator" that should characterize
all useful systems in a particular domain. These goals, while related,
should be recognized as often having cross purposes. My thesis will
contribute towards both goals, but in separate sections.
The Plan of the Thesis
The following questions are key to my thesis:
- Are abstract structured types usable in a distributed
Internet information system, with scale and data heterogeneity on
the order of Gopher or WWW?
- Will type oracles allow useful structured types to be
defined in a decentralized, continuously updated manner?
Once defined, can the right types be found for a given job?
- Will this system give wide-area information systems more semantic
power in real applications? Will people find the ideas worth
adopting for their applications? Why or why not?
- Can the system interoperate with existing information outside the
world of agents specifically constructed for this model?
- What are the limitations of the design? How would different
designs of the object/type system or the agent protocol change
the system's performance or capabilities?
The following questions are ones I wish to address in my thesis,
but they may not necessarily be completely answered:
- What are the best ways for type oracles to determine optimal
conversions to related types?
- What are the best ways to handle the introduction and revision
of new types in this system? To what extent can shared types
and implementations be evolved without breaking earlier type guarantees?
- What is the best way to express semantic constraints on types
and operations, in a widely heterogeneous world?
(I propose no formalism for such constraints, but plan to
include a slot in definitions to place either textual or formal
semantic requirements. Interpretation and enforcement is left to
agent implementors.)
In order to answer these and other questions, I will do the following:
- Analyze the state of the practice: I claim that
my architectural approach to Internet information systems will
bring more order and more transformational and operational power
to the world of Internet information systems. To help justify
this claim, I will analyze existing information systems that are
already in use over the Internet, such as Gopher, World Wide Web,
and the Domain Name System.
I will describe their architectural concepts, explicit
and implicit, compare the design decisions that were made in
their data structures, computations models, and protocols, and
describe analogs in distributed and object-oriented systems.
The analysis will
show the common features of these systems (largely in terms of
the abstractions described earlier), show how their data
and agent abstractions can be interpreted in terms of my
architectural model, and highlight problems and limitations
of these system's designs. (This type of analysis contrasts with
the more user-oriented analysis of surveys like
[Sch+92].)
I do not expect this part of the
thesis to take an especially long time, but it will help
demonstrate how my design takes advantage of known assets
of existing infosystems, and how it improves on those systems.
It will also help provide a sound basis for informing and
justifying my design.
A complete and thorough analysis of Internet information systems
could probably make a thesis in itself, similar to Tom Lane's work
in user interface architectures. My analysis is not so ambitious;
it's simply meant to
help lay the foundations for the specific architecture I will develop.
The analysis should, however, help information agent and system
developers better understand their design task, even if they
do not adopt the specific model I propose in the thesis.
- Produce a detailed architectural design of information agents
and type oracles: With the design analysis as a foundation,
I will go on to describe in detail a design for Internet agents,
and specifically for type oracles, that will allow structured types
to be defined in a distributed fashion and used over a wide-area
network. Basic agent services, data models, and the protocols
used to request services from agents will be described. Distributed
type oracle mechanisms will be shown, as well as the basic procedures
used to define new types, and to handle type conversion and substitution.
Various sophisticated enhancements could be made to
the basic system, such as handling of type evolution, and complex
use of meta-data and graph analysis to maximize information conversion.
While I hope to explore these issues to some extent in the thesis,
my first priority will be providing a basis for the basic type
and agent services. If those are general and flexible enough,
others can build more sophisticated type and method services on
top of the basic architecture.
- Produce a prototype to implement and demonstrate the
architecture, and test its application to actual information systems:
To demonstrate that my architectural design is workable, I will
implement a prototype system that supports replicated abstract
information objects over the Internet, and includes type oracles allowing
new types to be defined and used. Implementing the prototype
will show basic proof of concept. To show its ability to make
use of existing information, I will also construct basic agents that
act as 'gateways' (in both directions) to existing information systems
such as the World Wide Web. Furthermore, I will carry out a case
study showing how my system's use of structured types makes certain
information gathering applications significantly easier to carry out than
the current (ad hoc) state of the practice. (The exact domain of my
case study is not specified yet; it might, for example. be one of the
software engineering, library research, or medical applications
mentioned earlier in the paper.) Case studies should examine
how types are created, publicized, found, and changed.
Here are some possible ways a case study can be evaluated:
- Using myself: Comparing code size or development of application
implementations in my system with already-built applications of
the same functionality. Comparing ease of adding new functionality
in both cases (assuming source is available for both).
- Using other local people: Comparing types of applications people
find worth building with the system to types of applications people
build without it. Collaborating with selected local projects
and studying how the system helps or does not help their tasks,
and how structured types are defined and used in practice.
- Using people on the net: Analyzing the growth of type lattice, and
the reuse of types (either directly by other projects, or
indirectly through subtyping). Analyzing the quality of answers
provided by the type oracle. Measuring frequency and types of
cross-system use between my system and other existing infosystems.
(Instrumentation code in the type oracle should be quite useful here.)
If time permits, I
may also put together and document an agent toolkit to help people
construct their own agents in my system. Through experience with
the case studies, I will get a better sense of the strengths and
weaknesses of my architecture, and be able to suggest improvements.
A successful design and implementation of the system, combined with
tests of the system on sample applications, and an observance of the
use of the system (or related systems) in the Internet, should provide
the necessary material to answer the key questions identified above.
The additional questions can be answered to a certain extent as I
consider different design possibilities and observe the use of the system
by myself and others. The thesis will include a report of the
alternatives I considered and implemented, and the strengths and
weaknesses I observed in practice.
Timeline.
I would like to work on all three activities simultaneously in the course
of my thesis, but the relative emphasis will change over time. The infosystems
analysis and architecture specification will predominate in the first phase;
the implementation in the next phase; and the testing in the third phase.
Writing will mostly take place during the first and last phases of the work.
I will be taking an incremental approach to the implementation. I will
be experimenting with different protocols on my own early in the thesis work,
but eventually want to have outside users try out the system as well
to see how well the system scales up. Partly in order to attract
outside users,
I will need to make my system interoperable (in both directions) with existing
infosystems like WWW. In this way, users can take advantage of the added value
of my system without losing access to the information resources they
already have. In addition, WWW browsers like TkWWW and Mosaic with their
fill-out forms capabilities are
general enough that I can probably use them, or slight variants on them,
as the initial user interfaces to my agents, instead of having to build my own.
My thesis has a number of milestones that can serve as good
indicators of progress. Here are the major ones, with estimates
of probable time to completion:
- Thesis Proposal (May 1994)
- Analysis of existing systems (Aug/Sep 1994)
- Detailed design (Nov/Dec 1994)
- Release basic prototype, with agent protocol, oracles, basic types
(Dec 1994/Jan 1995)
- Case studies (Spring 1995)
- Finish writing document (Fall 1995)
I expect to complete the thesis in the fall of 1995, if all goes smoothly.
Expected Contributions
These are the key contributions that I expect to come from my thesis:
- For researchers: a better understanding of the requirements and
architecture of Internet-scale information systems, and how structured
information types can be used in a widely distributed environment.
This will come through my analysis of existing systems, the design
of the system I describe, and the comparison to other existing or
possible systems through analysis and experimentation. The type oracle
will also provide a useful example of the well-known
"mediator" concept in information systems.
- For information agent builders: a working prototype of a
type oracle service, and an understanding of the strengths and
weaknesses of various design choices involved in its construction.
Case studies will show its applicability to various domains.
- For information providers: a lattice of useful structured types
for common forms of information. I'll need to build the beginnings
of the lattice in order to test my design; and users in case studies
will enlarge it further. A repertoire of data types will be useful not
only to people using a system of my design, but also to people
wanting to incorporate structured data into their own systems.
There are certain questions relevant to my information system
that I do not expect
to make major contributions towards, though I hope to use the
research and experience of others in these areas in my design.
These include questions of
security, privacy, and cost accounting, naming syntax and semantics,
and human interfaces to information systems.
Other problems, such as search and filtering, will probably not be addressed
directly in the thesis, but I hope that the work of the thesis
will enable better solutions to these problems.
While the world of Internet information systems is changing
extremely rapidly, I expect these contributions to have staying power.
A well-constructed design, analysis and experience report on
type oracles and their datatypes should remain useful
as a guide to designers of many distributed information systems
beyond the particular system I design.
Notes
- [AAP86]
- Association of American Publishers.
Standard for Electronic Manuscript Preparation and Markup.
Washington, D.C.: Association of American Publishers, 1986.
- [AG94]
- Robert Allen and David Garlan.
"Formal Connectors".
Technical Report, CMU-CS-94-115, Carnegie Mellon University, Pittsburgh, PA.
A copy is available on-line.
- [Ank+93]
- F. Anklesaria,
M. McCahill, P. Lindner, D. Johnson, D. Torrey, and B. Alberti.
"The Internet Gopher Protocol." Internet RFC
1436, March 1993.
- [Abo+93]
- Gregory Abowd, Robert Allen, and David Garlan.
"Using Style to Understand Descriptions of Software Architecture".
In Proceedings of the ACM SIGSOFT '93 Symposium on the
Foundations of Software Engineering, December 1993, p. 9-20.
- [BC90]
- Kenneth P. Birman and Robert Cooper,
"The ISIS Project: Real
Experience with a Fault Tolerant Programming Systems".
Technical Report TR 90-1138, Cornell University Department of Computer
Science, July 1990.
- [BF92]
- N. Borenstein and N. Freed.
"MIME (Multipurpose Internet Mail Extensions): Mechanisms for Specifying
and Describing the Format of Internet Message Bodies." Internet RFC
1341, June 1992.
- [BL+92]
-
T.J. Berners-Lee, R. Cailliau, J-F Groff, B. Pollermann. "World-Wide Web: The
Information Universe". In "Electronic Networking: Research, Applications
and Policy", Vol. 2 No 1, pp. 52-58 Spring 1992, Meckler Publishing,
Westport, CT, USA. (A preprint is available on-line.)
- [BL93]
-
T,J. Berners-Lee, "Hypertext Transfer Protocol". Internet draft, CERN,
November 1993. Work in progress.
- [Bir92]
- Kenneth P. Birman, "The Process Group Approach to
Reliable Distributed Computing". Technical Report TR 91-1216, Cornell University Department of Computer Science, July 1991, revised September 1992.
- [Dan+92]
- Peter B. Danzig, Shih-Hao Li, and Katia Obrazacka,
"Distributed Indexing of Autonomous Internet Services".
Computing Systems, 5(4):433-459, Fall 1992.
(A preprint is available on-line.)
- [Kah91]
- Brewster Kahle. "An Information System for Corporate Users:
Wide Area Information Servers". Technical Report TMC-199, Thinking
Machines Corporation, Cambridge, MA, 1991.
- [Mam+89]
- Sandra A. Mamrak,
Michael J. Kaelbling, C. K. Nicholas, and M. Share. "Chameleon:
A System for Solving the Data-Translation Problem." IEEE
Transactions on Software Engineering 15(9): 1090-1108, September 1989.
- [Moc87]
- P. Mockapetris,
"Domain Names - Concepts and Facilities." Internet RFC
1034, November 1987.
- [Neu92]
- B. C. Neuman,
"The Virtual System Model: A Scalable Approach to Organizing Large Systems".
Technical Report 92-06-04, University of Washington Computer Science
Department, Seattle, WA, June 1992. A copy is
available on-line.
- [OMG92]
- Object Management Group.
The Common Object Request Broker: Architecture and Specification.
OMG Document Number 91.12.1, Revision 1.1. Wellesley, MA: QED Publishing Group,
1992.
- [Sho+93]
- K. Shoens, A. Luniewski, P. Schwarz, and J. Thomas.
"The Rufus System: Information Organization for Semi-Structured Data".
In Proceedings of the 19th VLDB Conference, Dublin,
Ireland, 1993.
- [Sch+92]
- Michael F. Schwartz, Alan Emtage, Brewster Kahle, and B. Clifford
Newman. "A Comparison of Internet Resource Discovery Approaches."
Computing Systems 5(4):461-493, Fall 1992.
A preprint is
available on-line.
- [SS94]
- Peter Schwarz and Kurt Shoens.
"Managing Change in the Rufus System".
In Proceedings of the 1994 International Conference on Data Engineering,
Houston, Texas, February 1994.
- [Wie92]
- Gio Wiederhold.
"Mediators in the Architecture of Future Information Systems".
IEEE Computer 25(3):38-49, March 1992.
spok@cs.cmu.edu (Written 17-May-94)