Gigabit Nectar Host Interfaces
The Gigabit Nectar network is built around a HIPPI interconnect. HIPPI
networks are based on switches and have a link speed of 800 Mbit/second.
Since this rate is close to the internal bus speed of many computer systems,
inefficiencies in the data flow (e.g. unnecessary copying of the data)
reduces the throughput observed by applications. The Nectar
group develop a network interface architecture built around the "Communication
Acceleration Block (CAB)". It is a single-copy architecture: the CAB uses
DMA to transfer the data directly from appliation buffers to buffers on
the host interface, calculating the IP checksum on the fly, thus minimizing
the load on the system memory bus. The figure below compares the dataflow
through a traditional interface (a) with a single-copy interface (b).
Two network interfaces based on the CAB
architecture were built by Network Systems Corporation: a Turbochannel
interface for DEC workstations, and an interface for the iWarp distributed
memory system.

Gigabit Nectar Workstation Interface
In the case of the workstation interface, the CAB transfers the data
directly from the application's address space to the buffers on the network
interface. This can be done both for applications that use the socket
interface, which as copy semantics, and for applications that use more
optimized interfaces based on shared buffers. The architecture of the
workstation interface is shown below. The main components are outboard
"network" memory, DMA engines, and support for IP checksumming.

In order for the CAB features to pay off, it is necessary to modify the
protocol stack on the host: the copy operations and checksum calculation
that are performed in a traditional protocol stack have to be eliminated
since these functions are now performed by the CAB hardware. We modified
protocol stack in DEC OSF/1 for the Alpha 3K/400 workstation to support
single-copy communication. The main idea is that instead of passing the
data through the stack in kernel buffers, we pass descriptors of the data
through the stack; the network device driver then implements the single copy
using the DMA engines on the stack. The following graphs show the impact of
using a single-copy communication architecture.

The first graph (above) shows the application-level throughput as a function
of the write size measured using ttcp using both the original (unmodified)
protocol stack and the single-copy (modified) stack. We see that the
modified stack can send data at 170 Mbit/second, which is the maximum the
device can sustain, as is shown by the "raw HIPPI" throughput numbers.
Throughput with the unmodified is limited to about 110 Mbit/second. The
next graph (below) explains the performance difference. It shows what
fraction of the CPU is used to support the communication throughput shown in
the first graph. With the unmodified stack, almost the entire CPU is used
for communication (specifically data copying and checksumming), so
performance is limited by the host. With the single-copy stack, only a
quarter of the CPU is used, even though a higher throughput is achieved,
i.e. by eliminating the data copy and checksumming, we improved the communication
efficiency significantly.
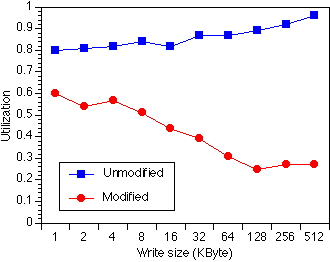
The final graph shows the efficiency of the communication for different
write sizes. We define the efficiency as the ratio of the throughput over
the utilization, i.e. it is the communication throughput the host can
support given a sufficiently fast network and network interface. The
results show that for large writes, the single-copy stack is about 5 times
as efficient as the unmodified stack.

Gigabit Nectar iWarp Interface
Network I/O on a distributed-memory system such as iWarp is more complicated
since the data is distributed across the private memories of the compute
nodes. Moreover, protocol processing cannot be parallelized easily. We use
an approach where the distributed-memory system creates large blocks of data
that can be handled efficiently by the network interface. The network
interface performs protocol processing, using the CAB to perform the most
expensive in hardware (data movement and checksumming). The architecture of
the network interface is shown below. The interface connects to the
internal interconnect of iWarp through the links on the left, and the green blocks correspond to the CAB. We have observed rates of 450 Mbit/second from a
simple iWarp application sending to a HIPPI framebuffer, and rates of 320
Mbit/second from iWarp to the Cray C90 in heterogeneous distributed
computing applications (medical MRI image processing).

The host interface effort and networking results are described in more detail
in papers.