
Will it roll ?
Learning environment property through action
Francois Chu
 |
 |
The idea for this project is to study what a robot can learn by itself when it only relies on its own senses and motor system. What kind of property can it learn, if it is limited by a black and white camera and a single arm ? Would it develop the same approach of spatiality if experienced through the sense of touch or through a stereoscopic vision system. In this project, we focused specifically on the property of rollability. We want to study if the robot can differentiate a rollable object from a non rollable one, not only by watching at them but also by interacting with them, since the rollability property is intrinsically a movement property than cannot be observed on still images (human can do it because they have several years experience with cubes and balls!).
This page present my project results for 15-494 Cognitive Robotics, taught by Dave Touretzky, by giving a brief description of the model I wanted to implement, the actual implementation, and some results and additional ideas.
Theoretical model
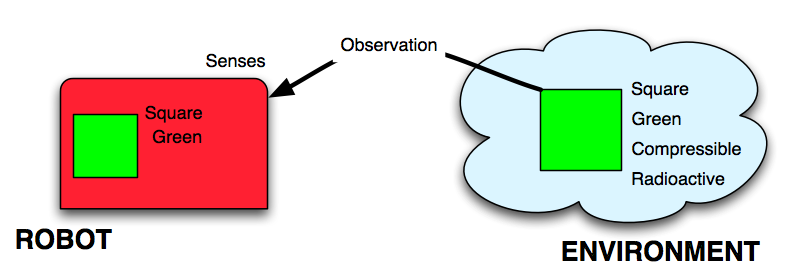
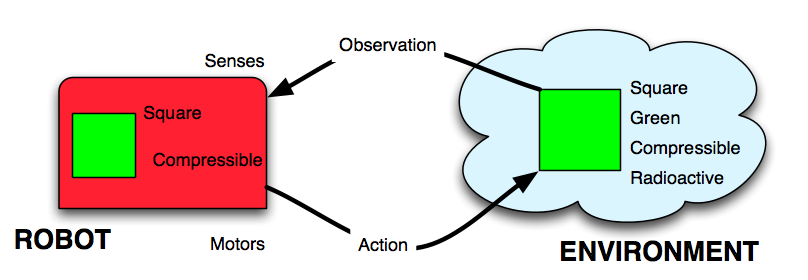
This problem can be expressed with the following model: we want to describe how a robot can attribute a property to what he describes as an object by interacting with the environment.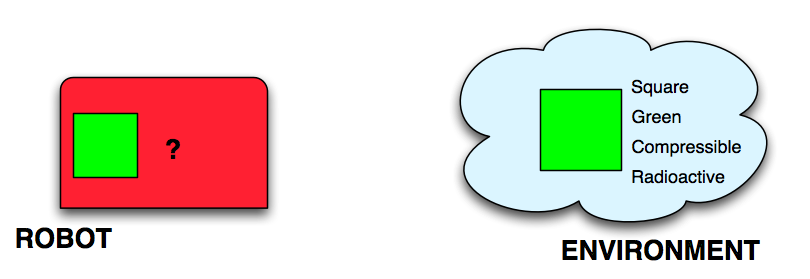
Implementation
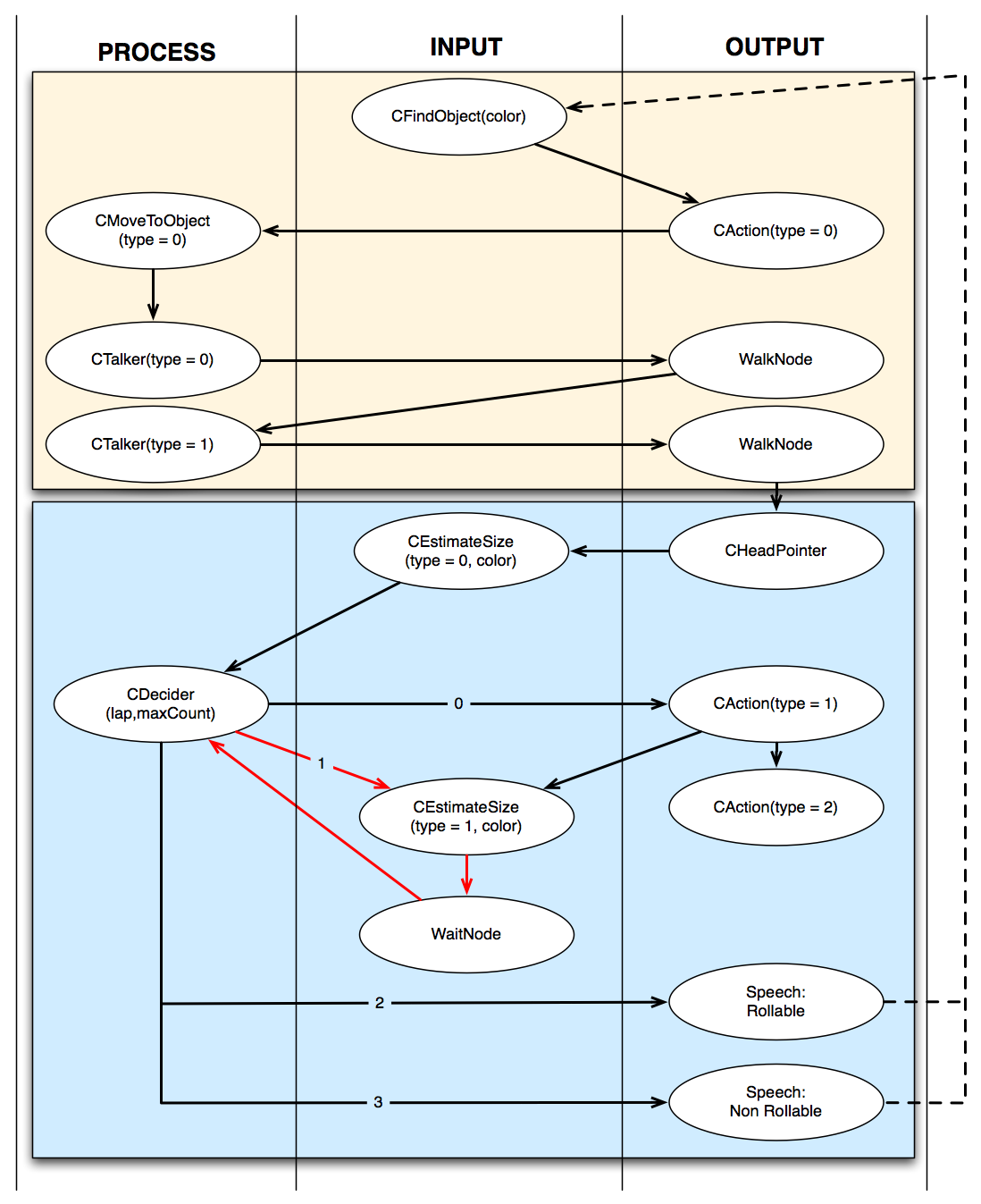
- Search and alignment: the Chiara robot is looking for the object to test, and move toward its target to align its body and its arm properly in order to perform the action.
- Action, feedback and decision: when the alignement condition is met, the action is performed, and a sequence of frame are recorded. Then, based on the variation of the object blob area, the Decider concludes if the object can roll or not. To increase the classification accuracy, the Behavior can loop a certain number of time and average the results.
Results
Here we can see the (slightly) difference of reaction between a rollable and a non rollable object:
| Rollable |  |
 |
 |
 |
 |
 |
| Non Rollable |  |
 |
 |
 |
 |
 |
The following video show a run of the Behavior against a rollable and a non rollable object, each focused on the robot or on the Sketch camera:
- Chiara detects a rollable object
- Chiara detects a non-rollable object
- Sketch space sequence for a rollable object
- Sketch space sequence for a non-rollable object
Interpretation
Although the classification is usually correct in good environment conditions, the accuracy drops significantly when these conditions are not met. There are multiple reasons for the behavior to fail classifying correctly :- Camera noise: since the behavior is based on the areas (in pixel) that are observed, noisy images can result in inaccurate input data for the Decider to operate correctly. In particular, light exposure can
- Lack of precision: for the Behavior to classify correctly, the arm should be positioned precisely relatively to the target object. Since the robot doesn't have 3D vision, the object position (in the local Shape Space) is an approximation that is not precise enough to get identical object reactions. The Walk mechanism of the robot
- Non included parameters: inclinaison and adherence of the floor. The robot is unaware of these parameters which certainly influences the object feedback
Conclusion & Future work
Different aspects could benefit from further improvement :- Input processing: in our example, the algorithm that predict if an object is rollable is quite simple, and was hand generated. In order to match the idea of robot learning by himself, we could change this algorithm by a clustering algorithm, which would take more features (such as SIFT descriptors, motion histogram, etc.) With time, categories of objets would maybe naturally appear.
- Actions: we have so far implemented the straight push, but to increase the choice of possible tests to perform on an object, future work could try to implement different actions, such as an arm swap, or a front right leg push (which is higher than the arm push and allows torque push around the y axis). For each of these actions, we can also try different velocities.
- Input sensors: with Chiara, we were limited to the camera, and to some extend to the IR sensor. What if the robot could have a touch sense, and build a sensorial representation of its environment ?
- What are the sensors and the motors that enable the most expressivity for a robot to learn ?
- How can the robot understand the possible actions it can do ?