
| Reconfigurable Computing Seminar | 2/4/98 |
Slide 1: PipeRench February 4, 1998
 Slide 2: Lab2
Slide 2: Lab2
 Slide 3: Reconfigurable Computing Today
Slide 3: Reconfigurable Computing Today
 Slide 4: PipeRench Goals
Slide 4: PipeRench Goals
 Slide 5: Virtualization
Slide 5: Virtualization
 Slide 6: Component Reconfiguration
Slide 6: Component Reconfiguration
 Slide 7: Pipeline Stage Reconfiguration
Slide 7: Pipeline Stage Reconfiguration
 Slide 8: Pipeline Stage Reconfiguration
Slide 8: Pipeline Stage Reconfiguration
 Slide 9: Pipelined Reconfiguration
Slide 9: Pipelined Reconfiguration
 Slide 10: Hardware Virtualization
Slide 10: Hardware Virtualization
 Slide 11: Benefits
Slide 11: Benefits
 Slide 12: Challenges
Slide 12: Challenges
 Slide 13: Abstract PR Fabric
Slide 13: Abstract PR Fabric
 Slide 14: Making It More Concrete
Slide 14: Making It More Concrete
 Slide 15: PE Based PR Fabric
Slide 15: PE Based PR Fabric
 Slide 16: The PE
Slide 16: The PE
 Slide 17: Virtualizing the Wires
Slide 17: Virtualizing the Wires
 Slide 18: Adding Pass Registers
Slide 18: Adding Pass Registers
 Slide 19: Further Reducing Interconnect
Slide 19: Further Reducing Interconnect
 Slide 20: What is left to specify?
Slide 20: What is left to specify?
 Slide 21: PipeRench
Slide 21: PipeRench
 Slide 22: Pipeline Reconfiguration
Slide 22: Pipeline Reconfiguration
 Slide 23: Fabric Architecture
Slide 23: Fabric Architecture
 Slide 24: Stripe Configuration
Slide 24: Stripe Configuration
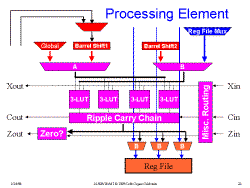 Slide 25: Processing Element
Slide 25: Processing Element
 Slide 26: Save and Restore
Slide 26: Save and Restore
 Slide 27: Save and Restore
Slide 27: Save and Restore
 Slide 28: Configuration Controller
Slide 28: Configuration Controller
 Slide 29: Memory Access Control
Slide 29: Memory Access Control
 Slide 30: Implementation
Slide 30: Implementation
 Slide 31: Architectural Summary
Slide 31: Architectural Summary
 Slide 32: Pass Registers: DCT
Slide 32: Pass Registers: DCT
 Slide 33: Assembly Language
Slide 33: Assembly Language
 Slide 34: Assembly Language Features
Slide 34: Assembly Language Features
 Slide 35: Simple Example
Slide 35: Simple Example
 Slide 36: Using Symbolic Names
Slide 36: Using Symbolic Names