| |
Verbs with
subject omitted |
Verbs with subject not omitted |
| |
1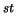 |
P(%) |
2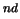 |
P(%) |
3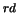 |
P(%) |
1 |
P(%) |
2 |
P(%) |
3 |
P(%) |
| LX |
240 |
96.7 |
54 |
98.1 |
1,227 |
97.1 |
31 |
71 |
17 |
94.1 |
1,085 |
83.3 |
| |
PRECISION = 97.1% |
PRECISION = 83.1% |
| BB |
0 |
0 |
0 |
0 |
121 |
97.5 |
0 |
0 |
0 |
0 |
351 |
82 |
| |
PRECISION = 97.5% |
PRECISION = 82.0% |
| GLOBAL PRECISION = 90.4% |
|