Clearly, FLTL and PLTLSTR(A) have great potential for exploiting
domain-specific heuristics and control-knowledge; PLTLMIN less
so. To avoid obscuring the results, we therefore refrained from
incorporating these features in the experiments. When running LAO*,
the heuristic value of a state was the crudest possible (the sum of
all reward values in the problem). Performance results should be
interpreted in this light - they do not necessarily reflect the
practical abilities of the methods that are able to exploit these
features.
We begin with some general observations. One question raised above was
whether the gain during the PLTL expansion phase is worth the
expensive preprocessing performed by PLTLMIN, i.e. whether PLTLMIN typically outperforms PLTLSIM. We can definitively answer this
question: up to pathological exceptions, preprocessing pays. We found
that expansion was the bottleneck, and that post-hoc minimisation of
the MDP produced by PLTLSIM did not help much. PLTLSIM is
therefore of little or no practical interest, and we decided not to
report results on its performance, as it is often an order of
magnitude worse than that of PLTLMIN.
Unsurprisingly, we also found that PLTLSTR would typically scale
to larger state spaces, inevitably leading it to outperform
state-based methods. However, this effect is not uniform: structured
solution methods sometimes impose excessive memory requirements which
makes them uncompetitive in certain cases, for example where
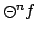 , for large
, for large  , features as a reward formula.
Sylvie Thiebaux
2006-01-20
, features as a reward formula.
Sylvie Thiebaux
2006-01-20