Unsurprisingly, we find that the syntax used to express rewards, which
affects the length of the formula, has a major influence on the run
time. A typical example of this effect is captured in
Figure 12. This graph demonstrates how re-expressing
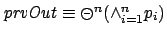 as
as
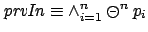 , thereby
creating
, thereby
creating  times more temporal subformulae, alters the running time
of all PLTL methods. FLTL is affected too as $FLTL progression
requires two iterations through the reward formula. The graph
represents the averages of the running times over all the methods, for
the COMPLETE domain.
times more temporal subformulae, alters the running time
of all PLTL methods. FLTL is affected too as $FLTL progression
requires two iterations through the reward formula. The graph
represents the averages of the running times over all the methods, for
the COMPLETE domain.
Figure 13:
Effect of Multiple Rewards on MDP size
|
![\includegraphics[width=0.65\textwidth]{figures/multiplesize}](img404.png) |
Figure 14:
Effect of Multiple Rewards on Run Time
|
![\includegraphics[width=0.65\textwidth]{figures/multipletime}](img405.png) |
Our most serious concern in relation to the PLTL approaches is their
handling of reward specifications containing multiple reward elements.
Most notably we found that PLTLMIN does not necessarily produce the
minimal equivalent MDP in this situation. To demonstrate, we consider
the set of reward formulae
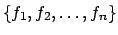 , each
associated with the same real value
, each
associated with the same real value  . Given this, PLTL approaches
will distinguish unnecessarily between past behaviours which lead to
identical future rewards. This may occur when the reward at an e-state
is determined by the truth value of
. Given this, PLTL approaches
will distinguish unnecessarily between past behaviours which lead to
identical future rewards. This may occur when the reward at an e-state
is determined by the truth value of  . This formula
does not necessarily require e-states that distinguish between the
cases in which
. This formula
does not necessarily require e-states that distinguish between the
cases in which
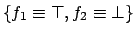 and
and
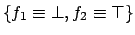 hold; however, given the
above specification, PLTLMIN makes this distinction. For
example, taking
hold; however, given the
above specification, PLTLMIN makes this distinction. For
example, taking
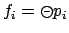 , Figure 13 shows that FLTL leads to an MDP whose size is at most 3 times that
of the NMRDP. In contrast, the relative size of the MDP produced by
PLTLMIN is linear in , the number of rewards and
propositions. These results are obtained with all hand-coded domains
except SPUDD-EXPON. Figure 14 shows the run-times
as a function of for COMPLETE. FLTL dominates and is only
overtaken by PLTLSTR(A) for large values of , when the MDP
becomes too large for explicit exploration to be practical. To obtain
the minimal equivalent MDP using PLTLMIN, a bloated reward
specification of the form
, Figure 13 shows that FLTL leads to an MDP whose size is at most 3 times that
of the NMRDP. In contrast, the relative size of the MDP produced by
PLTLMIN is linear in , the number of rewards and
propositions. These results are obtained with all hand-coded domains
except SPUDD-EXPON. Figure 14 shows the run-times
as a function of for COMPLETE. FLTL dominates and is only
overtaken by PLTLSTR(A) for large values of , when the MDP
becomes too large for explicit exploration to be practical. To obtain
the minimal equivalent MDP using PLTLMIN, a bloated reward
specification of the form
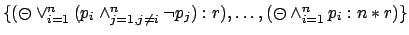 is necessary, which, by virtue of its exponential length,
is not an adequate solution.
Sylvie Thiebaux
2006-01-20
is necessary, which, by virtue of its exponential length,
is not an adequate solution.
Sylvie Thiebaux
2006-01-20