Earlier we claimed that one advantage of PLTLSTR and FLTL over
PLTLMIN and PLTLSIM is that the former perform a dynamic analysis
of rewards capable of detecting irrelevance of variables to particular
policies, e.g. to the optimal policy. Our experiments confirm this
claim. However, as for reachability, whether the goal or the
triggering condition in a response formula becomes irrelevant plays an
important role in determining whether a PLTLSTR or FLTL approach should be taken: PLTLSTR is able to dynamically ignore
the goal, while FLTL is able to dynamically ignore the trigger.
This is illustrated in Figures 17 and 18. In both figures, the domain
considered is ON/OFF with 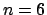 propositions, the response formula is
propositions, the response formula is
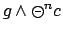 as before, here with both
as before, here with both  and
and  achievable. This response formula is assigned a fixed reward. To
study the effect of dynamic irrelevance of the goal, in
Figure 17, achievement of
achievable. This response formula is assigned a fixed reward. To
study the effect of dynamic irrelevance of the goal, in
Figure 17, achievement of 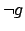 is rewarded
by the value
is rewarded
by the value  (i.e. we have
(i.e. we have 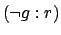 in PLTL). In
Figure 18, on the other hand, we study the
effect of dynamic irrelevance of the trigger and achievement of
in PLTL). In
Figure 18, on the other hand, we study the
effect of dynamic irrelevance of the trigger and achievement of 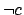 is rewarded by the value . Both figures show the runtime of the
methods as increases.
Achieving the goal, resp. the trigger, is made less attractive as
increases up to the point where the response formula becomes
irrelevant under the optimal policy. When this happens, the run-time
of PLTLSTR resp. FLTL, exhibits an abrupt but durable
improvement. The figures show that FLTL is able to pick up
irrelevance of the trigger, while PLTLSTR is able to exploit
irrelevance of the goal. As expected, PLTLMIN whose analysis is
static does not pick up either and performs consistently badly. Note
that in both figures, PLTLSTR progressively takes longer to
compute as increases because value iteration requires additional
iterations to converge.
is rewarded by the value . Both figures show the runtime of the
methods as increases.
Achieving the goal, resp. the trigger, is made less attractive as
increases up to the point where the response formula becomes
irrelevant under the optimal policy. When this happens, the run-time
of PLTLSTR resp. FLTL, exhibits an abrupt but durable
improvement. The figures show that FLTL is able to pick up
irrelevance of the trigger, while PLTLSTR is able to exploit
irrelevance of the goal. As expected, PLTLMIN whose analysis is
static does not pick up either and performs consistently badly. Note
that in both figures, PLTLSTR progressively takes longer to
compute as increases because value iteration requires additional
iterations to converge.
Figure 17:
Response Formula with Unrewarding Goal
|
![\includegraphics[width=0.65\textwidth]{figures/unrewardinggoal}](img424.png) |
Figure 18:
Response Formula with Unrewarding Trigger
|
![\includegraphics[width=0.65\textwidth]{figures/unrewardingcondition}](img425.png) |
Sylvie Thiebaux
2006-01-20