The first choice we have to make is to find a criterion for determining which rules should be added to the final theory, and which rules should be further improved. A straight-forward idea is to use some sort of significance test in order to determine whether a rule that has been learned from the current window is significant on the entire set of training examples. We have experimented with a variety of criteria known from the literature, but found that they are insufficient for our purposes. For example, it turned out that, at higher training set sizes, CN2's likelihood ratio significance test [13], which accepts a rule when the distribution of positive and negative examples covered by the rule differs significantly from the class distribution in the entire set, will deem any rule learned from the window as significant.
Eventually, we have settled for the following criterion: For each rule r learned from the current window we compute two accuracy estimates, AccWin(r) which is determined using only examples from the current window and AccTot(r) which is estimated on the entire training set. The criterion we use for detecting good rules consists of two parts:
where DA is the default accuracy,
and
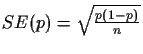 is the
standard error of classification [7].
is the
standard error of classification [7].
![]() is a user-settable parameter that can be used
to adjust the width of this range.
is a user-settable parameter that can be used
to adjust the width of this range.
The parameter ![]() determines the degree to which the estimates
AccWin(r) and AccTot(r) have to correspond. A setting of
determines the degree to which the estimates
AccWin(r) and AccTot(r) have to correspond. A setting of
![]() requires that
AccWin(r) = AccTot(r), which in general will only
be happen if r is consistent or has been learned from the entire
training set. This is the recommended setting in noise-free domains.
In noisy domains, values of
requires that
AccWin(r) = AccTot(r), which in general will only
be happen if r is consistent or has been learned from the entire
training set. This is the recommended setting in noise-free domains.
In noisy domains, values of
![]() have to be used because the
rules returned from the learning algorithm will typically be
inconsistent on the training set. Note, however, that a setting of
have to be used because the
rules returned from the learning algorithm will typically be
inconsistent on the training set. Note, however, that a setting of
![]() in a noisy domain will not lead to over-fitting
and a decrease in predictive accuracy because over-fitting is caused
by too optimistic estimates of a rule's accuracy. The chance of
accepting such rules decreases with the value of
in a noisy domain will not lead to over-fitting
and a decrease in predictive accuracy because over-fitting is caused
by too optimistic estimates of a rule's accuracy. The chance of
accepting such rules decreases with the value of ![]() .
Clearly, if
the chance of a rule being accepted decreases, the run-time of
algorithm increases because windowing has to perform more
iterations. The extreme case,
.
Clearly, if
the chance of a rule being accepted decreases, the run-time of
algorithm increases because windowing has to perform more
iterations. The extreme case,
![]() ,
causes the window to grow
until it contains all examples. Then the rule is accepted by the
second criterion because the examples used for estimating AccWin(r)and AccTot(r) are basically the same. Typical settings in noisy
domains are
,
causes the window to grow
until it contains all examples. Then the rule is accepted by the
second criterion because the examples used for estimating AccWin(r)and AccTot(r) are basically the same. Typical settings in noisy
domains are
![]() or
or
![]() .
.
![]() will
move all rules that have survived the first criterion into the final
rule set. In as much as the learner is sufficiently noise-tolerant and
the initial example size is sufficiently large, the algorithm
implements learning from a random subsample if
will
move all rules that have survived the first criterion into the final
rule set. In as much as the learner is sufficiently noise-tolerant and
the initial example size is sufficiently large, the algorithm
implements learning from a random subsample if
![]() .
.