Graduate school affords one the luxury to have only a short-term vision on where your research is going; the farthest I could think out during my time was at most two papers. But now that I have to write grants to raise scrilla for my students, I find myself thinking about more long-term projects and trying to predict where the research field is going.
These next three posts are my thoughts of where I think there are still interesting unsolved problems in OLTP database systems research. The first is up non-volatile memory (NVM).
Main Memory Systems
Way back in 2007, H-Store was the vanguard for a new era of main memory-oriented database systems. It wasn't the first transactional, in-memory DBMS (TimesTen and DataBlitz are earlier examples from the 1990s), but it was one of the first systems created after the NoSQL crowd started bleating that the only way to scale is to give up ACID.
It wasn't obvious right away to some that a memory-oriented architecture was the way to go for scalable OLTP applications. In the early days of VoltDB, customers were uncomfortable with the idea of storing your entire database in volatile DRAM. I visited PayPal with Stonebraker in 2009 when he went to talk to them about VoltDB and I remember that the senior management were unnerved by the idea of a DBMS that did not store all physical changes to tuples immediately on disk. The prevailing conventional wisdom has obviously changed and now VoltDB is being used in many mission-critical applications. Since then, several other memory-oriented systems are now available, including MemSQL, SAP HANA, and Microsoft Hekaton (technically Hekaton is an extension for SQL Server, but the rumor is that it was originally a standalone system that management killed because it would cannibalize sales). One could argue (and I have) that MongoDB is essentially a memory-oriented DBMS because they use MMAP, but they don't get all of the advantages because they use coarse-grained locking. Other notable in-memory research systems that came along after H-Store include Shore-MT, HyPer, and Silo. In particular, the HyPer team has amassed an impressive corpus of research publications that I wish we had achieved with the H-Store project.
In my opinion, main memory DBMS research is played out. There are of course more papers that we are working on for H-Store and there are still engineering problems that still need to be solved for customers in the commercial world. But the next systems that we are going to build at CMU will not focus on fast transaction processing in a DRAM-based DBMS using today's CPU architectures. This is mostly a solved problem from a research point-of-view.
A more interesting topic is how the advent of NVM will overturn the traditional storage hierarchy in computing systems. DBMSs are uniquely positioned to utilize this technology for a wide variety of application domains.
NVM+DRAM Systems
The first incarnations of NVM devices will be as block-addressable storage on PCI-e cards. Based on my discussions with hardware vendors, these devices are less than five years away. I refer to this as the NVM+DRAM storage hierarchy. Memory-oriented DBMSs will still be the best performing architecture for this hierarchy because they do not use legacy architectural components from the 1970s that are designed to mask the latency of slow disks (e.g., heavyweight concurrency control).
Since a DBMS on the NVM+DRAM hierarchy still uses DRAM for ephemeral storage, it will need to flush out changes to stable storage for recovery and durability. This logging will be the major bottleneck for all DBMSs, even if it has fast NVM. We did some initial experiments testing MySQL and H-Store (with anti-caching) on Intel Lab's NVM emulator as part of the ISTC for Big Data. The emulator was configured so that all reads/writes to NVM were ~180ns compared to a ~90ns read/write to DRAM. We used three variants of the YCSB workload: (1) read-only with 100% reads, (2) read-heavy with 90% reads + 10% updates, and (3) write-heavy with 50% reads + 50% updates. We also control the amount of skew that determines how often a tuple is accessed by transactions using YCSB's Zipfian distribution to model temporal skew in the workload.
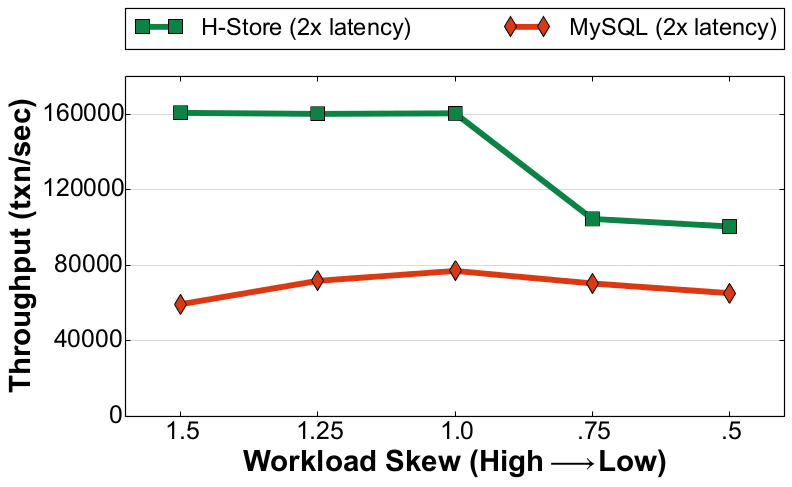 Read-Only Workload (YCSB) |
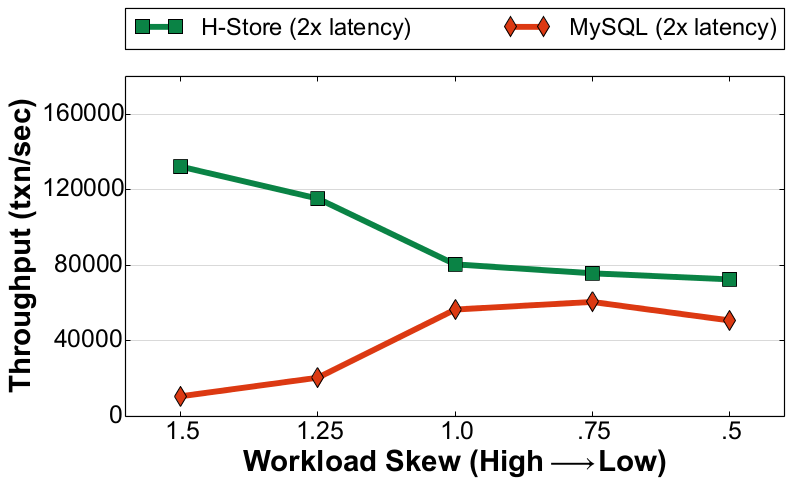 Read-Heavy Workload (YCSB) |
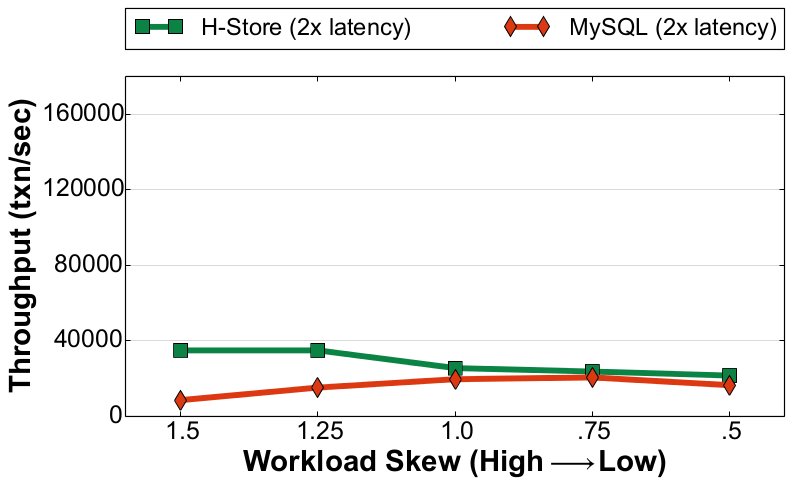 Write-Heavy Workload (YCSB) |
| Figure 1: H-Store and MySQL running on a NVM+DRAM system with Intel Lab's hardware emulator. | ||
As shown in Figure 1, our experiments show that there is a significant decrease in throughput as the number of update transactions in the workload increases. H-Store exhibits a ~77% drop in its peak performance for the read-only workload compared to its best performance in the write-heavy workload. For MySQL, this difference is nearly 75%. This is due to the overhead of preparing and writing the log records out to durable storage to overcome DRAM's volatility. We also see that for the read-heavy workload H-Store achieves 13x better throughput over MySQL when skew is high, but only a 1.3x improvement when skew is low. This is because H-Store performs best when there is high skew since it needs to fetch fewer blocks from the NVM anti-cache and restart fewer transactions. In contrast, the disk-oriented system performs worse on the highly skewed workloads due to lock contention. But this performance difference is nearly non-existent for the write-heavy workload. We attribute this to the overhead of logging.
NVM-only Systems
A more interesting scenario is when the system does not have any volatile DRAM and only has byte-addressable NVM. Using a NVM-only hierarchy has implications for how a DBMS manages data because now all memory writes are potentially persistent.
One approach is to designate half of the NVM's address space for temporary data that is deleted after a restart and then use the other half for durable storage. This would require minimum source code changes to existing systems, but I believe that this does not exploit the full potential of NVM and could unnecessarily wear out the device more quickly. For example, a disk-oriented DBMS using this hierarchy is not "aware" that modifications to data stored in its buffer pool are persistent. As such, many aspects of their architecture are unnecessary. In the case of MySQL, it uses a doublewrite mechanism to flush data to durable storage by first writing out the pages to a contiguous buffer on disk before writing them out to the data file. This means that on a NVM-only system every modification to a tuple in MySQL will cause four writes to the storage device: (1) to the record in the buffer pool, (2) to the write-ahead log, (3) to the doublewrite buffer, and (4) to the primary storage. Likewise, a system like H-Store does not have any way to ensure that a change to the database has been completely flushed from the CPU's last-level cache. Thus, when a transaction commits, any changes that it made might still be in volatile caches could be lost before the processor writes them out to the NVM. This means that it also still needs to write to a log for recovery.
Using the same workload described above, we tested MySQL and H-Store again using Intel Lab's emulator as an NVM-only system. All memory allocations (e.g., malloc) were slowed down using a special CPU mode, and all permanent data was stored on the emulator's NVM-optimized filesystem.
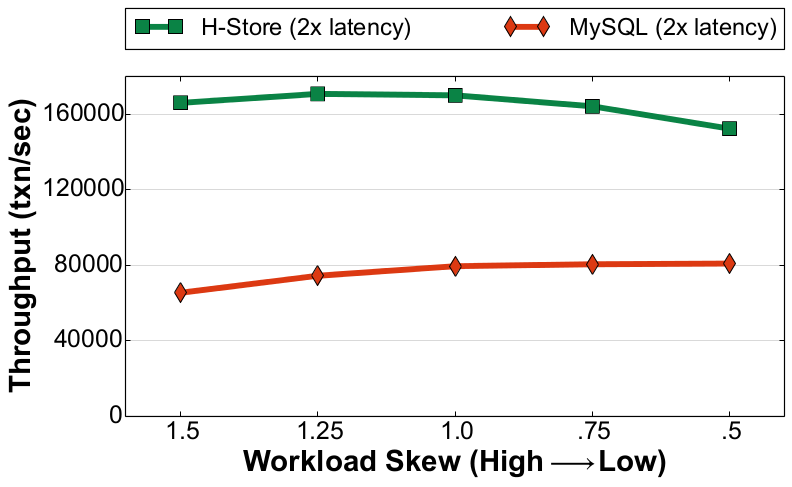 Read-Only Workload (YCSB) |
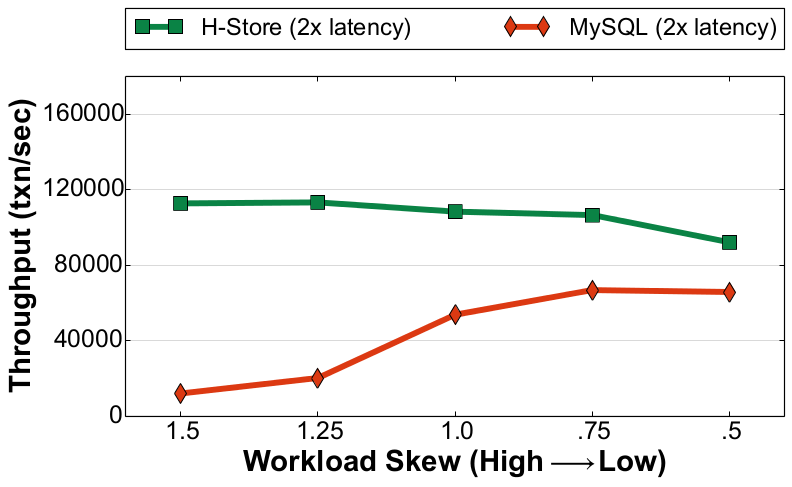 Read-Heavy Workload (YCSB) |
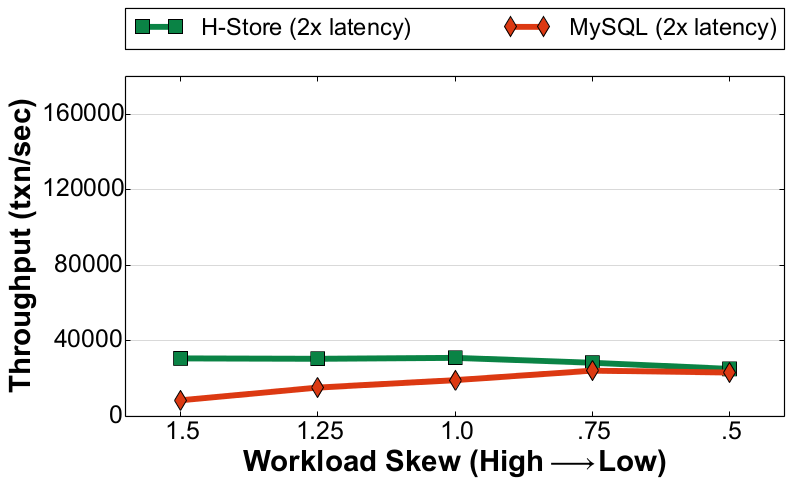 Write-Heavy Workload (YCSB) |
| Figure 2: H-Store and MySQL running on a NVM-only system with Intel Lab's hardware emulator. | ||
Like with the NVM+DRAM configuration, the DBMSs' throughputs are greatly affected by the number of update transactions in the workload. This is because each system still writes log entries for each transaction to durable storage even though all updates to NVM-resident data are potentially persistent. When comparing the systems' peak performance in the read-only workload with the write-heavy workload, we see that H-Store's throughput drops by ~81% while MySQL's drops by ~72%. Since the write-heavy workload has more transactions that update the database, each DBMS has to write more log entries and thus there is more contention on the logging manager.
N-Store
Rather than try to retrofit an existing system, my student Joy "The Champ" Arulraj and I are developing a new DBMS that is designed specifically for the NVM-only hierarchy. We are going develop the fundamental principles of how to use byte-addressable NVM to support data-intensive applications in a way that is not possible with today's DBMSs. The culmination of this work will be embodied in a new open-source DBMS that we have dubbed N-Store (i.e., the "non-volatile store"). I have some thoughts on what it takes to build a new DBMS from scratch in academia that I hope to write about in the future.
There are two goals for the N-Store project. First, we want to develop hybrid DBMS technologies for NVM that support simultaneous high-velocity OLTP transactions with full ACID guarantees and real-time OLAP analytical queries. The second goal is to develop storage methods that allow a DBMS to recover (almost) instantaneously after a crash without needing a ARIES-style log. We contend that both of these are not possible with current systems nor the NVM+DRAM hierarchy. There are also bunch of OS-level problems that need to be solved first before this is possible (e.g., how to restore a process with the same address space and registers after it crashes), but these are orthogonal to this project.
I think that hybrid systems like HANA and HyPer are the way forward for OLTP DBMSs, but they will not completely replace data warehouses (e.g., Vertica). These DBMSs ingest data from multiple front-end applications using an ETL process to convert them into a uniform schema, whereas in a hybrid system the schema does not change. But a system like N-Store allows application developers to implement analytical functionality directly in their OLTP application more easily, rather than it being an afterthought. This will open up new possibilities because now developers can use powerful analytical operations immediately as data is created. This is better than waiting to transfer the data to the data warehouse and then finding out that there is a key piece of data that they could have collected but did not.
Although our research thus far only uses Intel Lab's NVM emulator, we are reaching out to other industrial partners that are also coming out with NVM devices, including HP Labs and Diablo Storage. We plan to evaluate our work using different NVM technologies to ensure that our research is not dependent on the characteristics of a single device. Our hope is that just like the C-Store and H-Store projects before it, N-Store will influence on the design of future DBMSs.