Transactions
Transactions are sequences of actions such that all of the operations within the transaction succeed (on all recipients) and their effects are permanantly visible, or none of none of the operations suceed anywhere and they have no visible effects; this might be because of failure (unintentional) or an abort (intentional).Characterisitically, transactions have a commit point. This is the point of no return. Before this point, we can undo a transaction. After this point, all changes are permanant. If problems occur after the commit point, we can take compensating or corrective action, but we can't wave a magic wand and undo it.
Banking Example:
Plan: A) Transfer $100 from savings to checking
B)Transfer $300 from money market to checking
C) Dispense $350Transaction:
8. dispense 350
1. savings -= 100
2. checking += 100
3. moneymkt -= 300
4. checking += 300
5. verify: checking > 350
6. checking -= 350
7.
Notice that if a failure occurs after points 1 & 3 the customer loses money.
If a failure occurs after points 2, 4, or 5, no money is lost, but the collectiopn of operations cannot be repeated and the result in not correct.
An explicit abort might be useful at point 6, if the test fails (a negative balance before the operations?)
Point 7 is the commit point. Noticve that if a failure occurs after point 7 (the ATM machine jams), only corrective action can be taken. The problems can't be fixed by undoing the transaction.
Properties of Transactions
Acid
Consistency (serializability)
Isolation
Durability
- Acid - "All or nothing"
- Consistency -- Perhaps better described as "Serializability". Transactions begin with the system in a valid state and should leave things that way once completed.
- Isolation - Regardless of the level of concurrency, transactions must yields the same results as if they were executed one at a time (but any one of perhaps several orderings).
- Durability - permanance. Changes persist over crashes, &c.
Distributed Transactions and Atomic Commit Protocols
Often times a transaction will be distributed across several systems. This might be the case if several replicas of a database must remain uniform. To achieve this we need some way of ensuring that the distributed transaction will be valid on all of the systems or none of them. To achieve this, we will need an atomic commit protocol. Or a set of rules, that if followed, will esnure that the transaction commits everywhere or aborts everwhere.
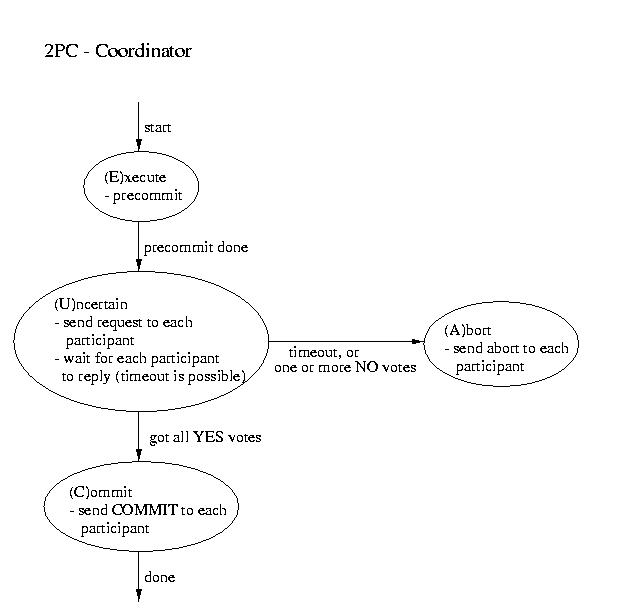
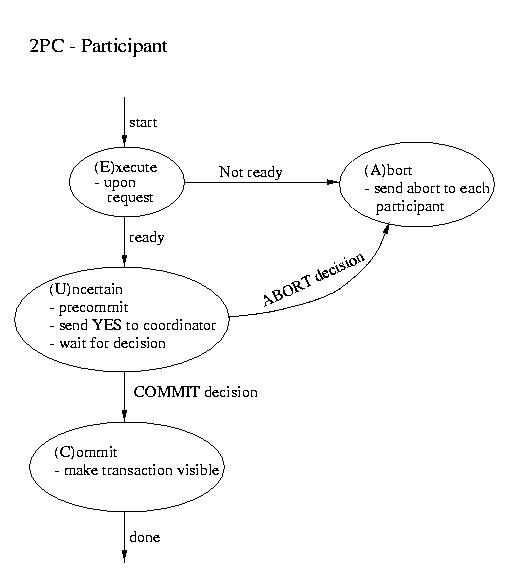
Two Phase Commit (2PC)
The most commonly used atomic commit protocol is two-phase commit. You may notice that is is very similar to the protocol that we used for total order multicast. Whereas the multicast protocol used a two-phase approach to allow the coordinator to select a commit time based on information from the participants, two-phase commit lets the coordinator select whether or not a transaction will be committed or aborted based on information from the participants.
Coordinator Participant ----------------------- Phase 1 -----------------------
- Precommit (write to log and.or atomic storage)
- Send request to all participants
- Wait for request
- Upon request, if ready:
- Precommit
- Send coordinator YES
- Upon request, if not ready:
- Send coordinator NO
Coordinator blocks waiting for ALL replies
(A time out is possible -- that would mandate an ABORT)----------------------- Phase 2 ----------------------- This is the point of no return!
- If all participants voted YES then send commit to each participant
- Otherwise send ABORT to each participant
Wait for "the word" from the coordinator
- If COMMIT, then COMMIT (transaction becomes visible)
- If ABORT, then ABORT (gone for good)
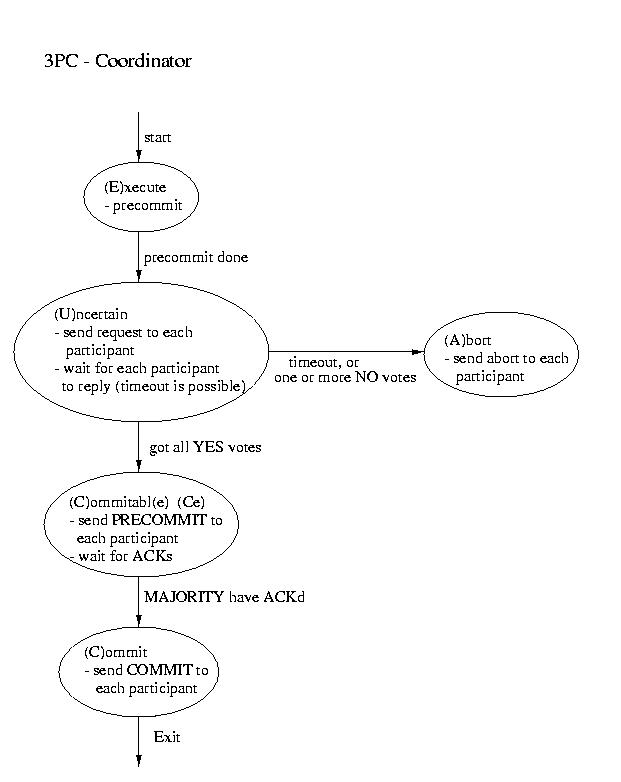
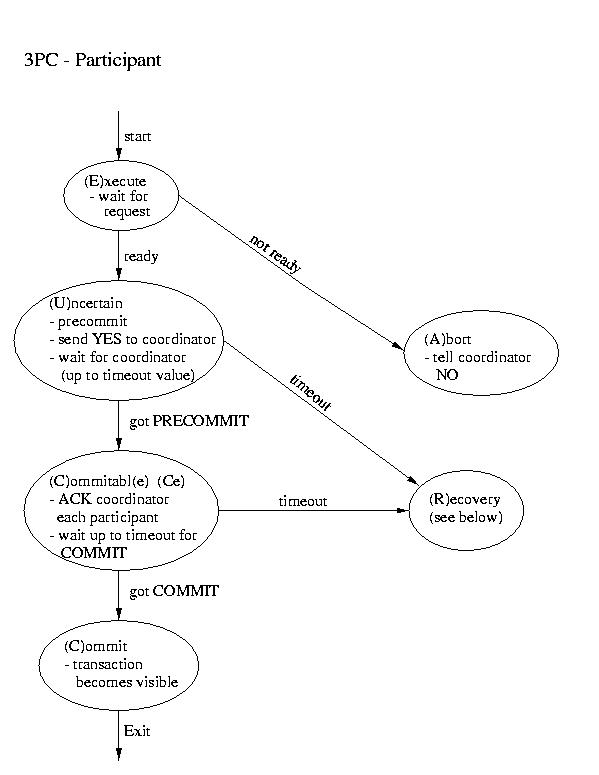
Three-phase Commit
Another real-world atomic commit protocol is three-pahse commit (3PC). This protocol can reduce the amount of blocking and provide for more flexible recovery in the event of failure. Although it is a better choice in unusually failure-prone enviornments, its complexity makes 2PC the more popular choice.
Recovery in 3PC
If the participant finds itself in the (R)ecovery state, it assumes that the coordinator did not respond, because it failed. Although this isn't a good thing, it may not prove to be fatal. If a majority of the participants are in the uncertain and/or commitable states, it may be possible to elect a new coordinator and continue.We'll discuss how to elect a new coordinator in a few classes. So, for now, let's just assume that this happens auto-magically. Once we have a new coordinator, it polls the participants and acts accordingly:
- If any participant has aborted, it sends ABORTs to all (This action is mandatory -- remember "all or none").
- If any participant has committed, it sends COMMIT to all. (This action is mandatory -- remember "all or none").
- If at least one participant is in the commitable state and a majority of the participants are commitable or uncertain, send PRECOMMIT to each participant and proceed with "the standard plan" to commit.
- If there are no committable participants, but more than half are uncertain, send a PREABORT to all participants. Then follow this up with a full-fledged ABORT when more than half of the processes are in the abortable state. PRECOMMIT and abortable are not shown above, but they are complimentary to COMMIT and commitable. This action is necessary, because an abort is the only safe action -- some process may have aborted.
- If none of the above are true, block until more responses are available.
Two-Phase Locking
Transaction, by their nature, play with many different, independent resources. It is easy to imagine that, in our quest for a high throughput, we process two transactions in parallel that share resources.This can generate an obvious problem for "Isolation". We need to ensure that the results are consistent with the two (or more) concurrent transactions being commited in some order. So we can't allow them to make uncoordinated use of the resources.
So, let's asusme that, while any transaction is writing to a resource, it is locked, preventing any other transaction from writing to it. Now, a transaction can acquire all of the locks it needs, complete the mutation, and release the locks. This scheme prevents the corruption of the resources -- but opens us up to another problem: deadlock.
Let's imagine that one transaction wants to access resource A, then C, then B. And, other concurrent transaction wants to access resource B, then A, then C. We've got a problem if the one of the transactions grabs resources A and C, and the other grabs resources B. Neither transaction can complete. One is hold A and C, waiting for the other to release B. And, the other is holding B, while waiting for C and A. What we have here is known as circular wait, which is one of the four "necessary and sufficient" conditions for deadlock, usually captured as:
- Non-sharable resource, e.g. mutual exclusion
- Non-preemptable (no police, or even big sticks, to settle disputes)
- Hold and wait usage (holding a resource while needing another)
- Circular wait (hold and wait + a circular dependency chain)
Fortunately, circular-wait is often very easy to attack. If the resources are enumerated in a consistent way across users, e.g. A, B, C, D, ...Z, and each user requests resources only in increasing order (without wrap-around), circular wait is not possible. One can't wait on a lower resource than one already holds, so the depednency chain can't be circular.
This observation is the basis of a two-phase lock. In the first phase, a transaction acquires -all- of the locks it needs in strictly -increasing- order. It then uses the resources. In the last phase, it shrinks, or releases locks. This universal ordering in which all users acquire resources prevents deadlock.
In practice, transactions often are said to begin phase-1 (growing) when they start and end phase-1 when they are done processing and are ready to commit. Phase-2 begins (and ends) upon the commit. So, the essential part of 2PL is, as you might guess, the serial order in which the locks are acquired. The two phases are, in practice, mostly imaginary.