
| Fig 1: Performance degradation under different power budgets when thread motion is done every 500 cycles |
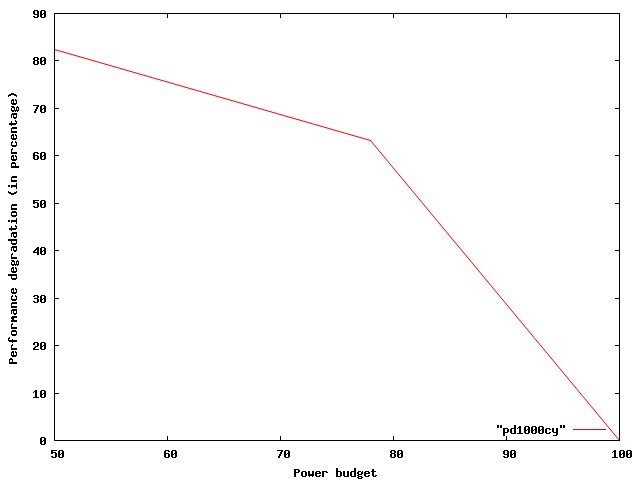
| Fig 2: Performance degradation under different power budgets when thread motion is done every 1000 cycles |
What have we accomplished so far?
We are using the BLESS simulator for simulating the Chip Multiprocessor.
| Fig 1: Performance degradation under different power budgets when thread motion is done every 500 cycles |
| Fig 2: Performance degradation under different power budgets when thread motion is done every 1000 cycles |
Meeting the milestone
We had set our milestone as implementing thread motion on the bless simulator and getting some preliminary results. And we have been successful in meeting this milestone.
Surprises
As far as the implementation is concerned, we did not have any major surprises since we were aware of the capabilities/limitations of the simulator from the start of the project. As a preliminary result, we expected to see that performing thread migration at fine grained intervals would lead to huge performance degradation. The preliminary results indicate this as well.
Revised Schedule
We need to perform extensive simulation studies. In particular,
Resources Needed
The Bless simulator is our main resource. This simulator is a trace-based simulator and does not model instruction addresses or the L1 Instruction Cache. So, we do not account for the Instruction Cache going cold, following a migration. However, we model the effects due to the Data cache going cold and the loss of architectural state. These would constitute a major part of the performance degradation and as the preliminary results indicate, are representative.