KNOWLEDGE TRANSFER FROM WEAKLY LABELED AUDIO USING CONVOLUTIONAL NEURAL NETWORK FOR SOUND EVENTS AND SCENES. pdf
Authors: Anurag Kumar, Maksim Khadkevich, Christian Fügen
Audioset Dataset
Audioset is a large scale weakly labeled [2] dataset for sound events, Audioset. It contains a total of 527 sound events for which labeled videos from Youtube are provided. The maximum duration of the recordings is 10 seconds and a large portion of the example recordings are of 10 seconds duration. However, there are a considerable number of recordings with smaller duration.
In this paper, we worked with the balanced train for training the models and Eval set for evaluation.
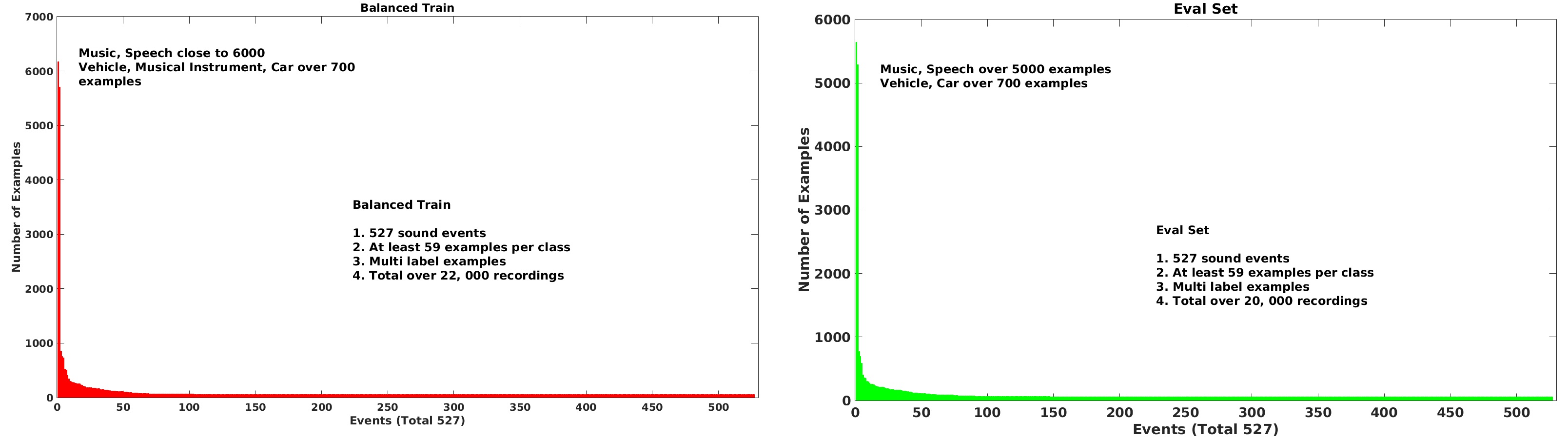
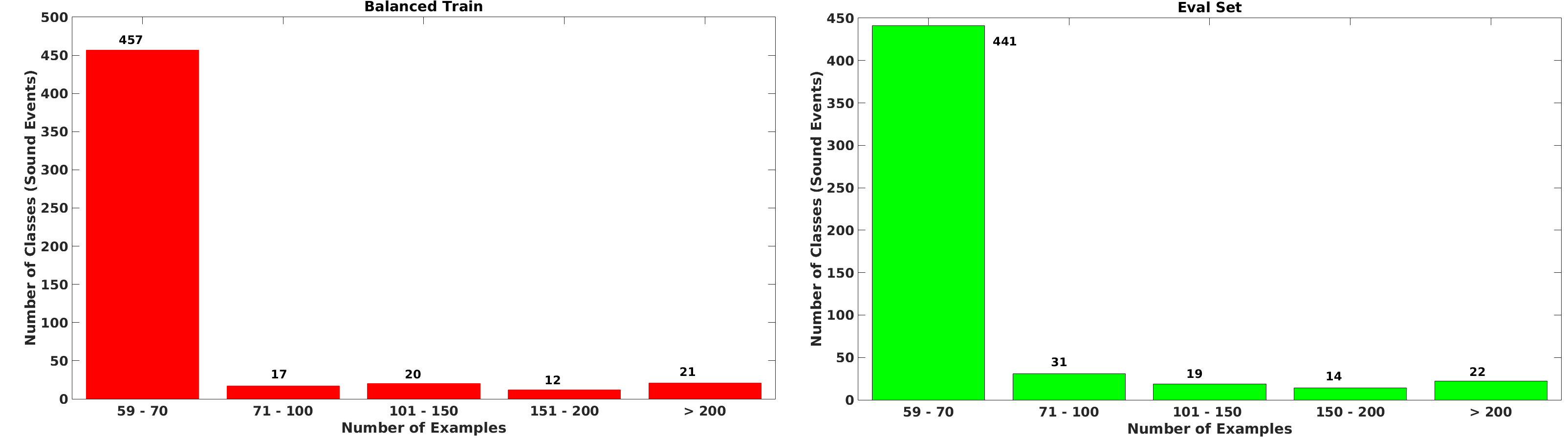
Balanced train set provides at least 59 examples for each sound event. It has a total of around 22, 000 recordings.
Eval set is the full evaluation set of Audioset. It consist of a total of around 20, 000 example recordings, again with at least 59 examples per class
Audioset is Multi-label dataset. On an average each recording example contains 2.7 classes [1].
Due to multi-label nature of recordings, the actual number of examples for several classes is higher. The class wise distribution of labels for both balanced train and eval set is shown in the figures below.
Fig 1. - Number of examples for different sound events in balanced ( Red ) and eval (Green) sets Fig 1. - Number of Events vs Number of Examples (Distribution of examples and events) ( Red ) and eval (Green) sets
Audioset Results
As shown in paper, the proposed weak label CNN approach (NS) outperforms a network trained under strong label assumption (NslatS). Moreover, NS works smoothly with recordings of variable lengths and is computationally more efficient by over 30 % during training as well as test (See paper for comparison).
Here we provide, additional results and analysis. We also show some analysis on temporal localization of events within the recording.
Mean AUC improves by an absolute 1.2 (from 0.915 to 0.927, 1.3 % relative)
Each figure shows comparison for 50 sound events. The order of appearance is available here. First 50 in AP1, next 50 in AP2 and so on.
Localization of Sound Events: Our proposed network can perform localization of sound events. The network output at each segment can be used to perform localization of sound events. Some examples of these localizations are provided here. Note that Audiosetdoes not provide time stamps of location of sound events and hence we cannot produce any quantative results on sound event localization.