KNOWLEDGE TRANSFER FROM WEAKLY LABELED AUDIO USING CONVOLUTIONAL NEURAL NETWORK FOR SOUND EVENTS AND SCENES. pdf
Authors: Anurag Kumar, Maksim Khadkevich, Christian Fügen
ESC-50 Dataset
ESC-50 [4] is a sound event dataset. It consists of a total of 50 sound events. The list of sound events can be found here.
The dataset consists of a total of 2,000 recordings each of 5 seconds durations.
It comes pre-divided into 5 folds.
The training set consists of 4 out of 5 folds and the remaining 5th fold is used for testing. This is done all 5 ways and average accuracies are reported.
The training set is used for network adaptation as well as for training linear SVMs.
ESC-50 Results
Comparison of our proposed method with state of art methods is shown is paper
Our method not only outperforms previous methods by a considerable margin but also outperforms human accuracy on this dataset
Even direct representation obtained from NS, that is without any task adaptive training, we obtain an average accuracy of 82.8%
, compared to 81.3% human accuracy on this dataset.
Best accuracy of 83.5% is obtained using F1 representations (with max() mapping), from NIT and NIIT
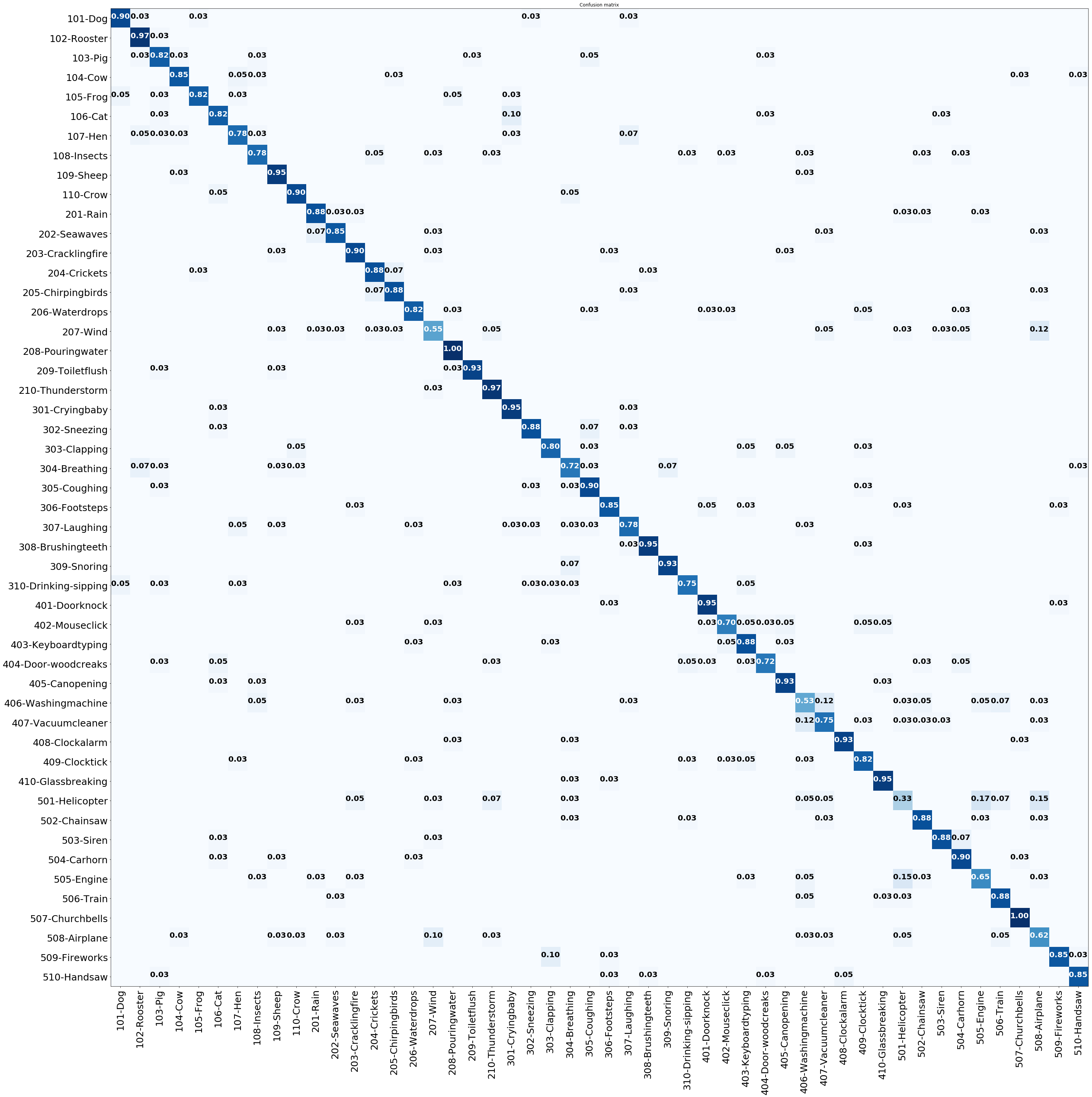
Class-wise results - Below we show confusion matrix for two cases. Classwise confusion matrix for all cases are available here. The file name clarifies the representation used, e.g esc50.NT_III.F1.max.png means NIIIT network, F1 representations and max() function to map segment level representations to full recording level representations. The figure files here, might be visually more pleasing. All numbers have been rounded to 2 decimal places.
Fig 1. Confusion matrix for F1 representations (max() mapping) from NS Fig 2. Confusion matrix for F1 representations (max() mapping) from NIIT