Thus, armed with a cluster tree from a database, we can now use it to find the optimal set of utterances to cover the acoustic space. This algorithm works in three stages:
As this is a bootstrap process, we have not yet been able to investigate different types of databases from which to build the initial cluster tree. What is important, though. is to have a fairly general databases with good phonetic coverage and a diversity. In our experiments, described below, we choose the largest databases we had from one of our key speakers, but we are in the process of investigating this further.
Once the initial tree is created, we take a much larger example of text from the domain. We have experimented with place names (for all zip codes in the U.S.), and people's names from movies (as in, for example, the Internet Movie Database at imdb.org) - though no results are presented from those databases here. Our main experiment has concentrated on simple stories, as general text reading is still a common application for speech synthesis. The details of that experiment are presented below.
We take the database and synthesize it with respect to the basic cluster tree and count how often each cluster is used in the synthesis of the large amount of text. As unit selection databases - even our current ones - tend to have unnatural distributions, using some real data allows the frequencies of the clusters to be better estimated.
The third stage is to greedily select the utterances which have optimal coverage with respect to the frequency-weighted cluster tree.
If we score an utterance only by the number of uses of each of the units needed to synthesis it, we would continually select only utterances containing very high frequency units, and never provide examples of less frequent units. Thus, we want an iterative selection process that notes instances that have already been selected and appropriate gives new examples of existing items a lower score.
The basic selection algorithm is
todo\_list = all sentences
while todo\_list
score all utterances in todo\_list
remove all utterances with
score 0 from todo\_list
select best utterances
mark its items in the cluster tree
remove best utterance from todo\_list
The score mechanism deserves further explanation. For each phone item in a candidate utterance we recursively step down the cluster tree, asking each question until we reach a node already marked with an item from a previous selected sentence. We then ask the question at that node to see if the existing item and the candidate item can be distinguished (i.e., one answers ``yes'' to the question and the other ``no''). If they can be distinguished, the candidate item is given a score of sum of the frequencies on all leafs subordinate to its answer node.
If they cannot be distinguished by the current question, the candidate item is given a score of zero, which is slightly pessimistic, but justified given the objective function. If the node is a leaf node the candidate item is also given the score of zero (as we already have an example). We score all sentences in the corpus and find the one whose sum its item's score the highest.
Selecting that utterance, we then add its items to the cluster trees. We again recursively follow the cluster tree questions for each item until the distinguishing node is found. The currently selected item is then moved down one level to mark the appropriate yes/no node below and the newly selected item is used to mark the other node.
Thus, as sentences are selected, we fill out the coverage of the trees, and as we fill in the high frequency parts of the cluster tree, the less frequent ones become more important.
An example may help illustrate this. If we had the following
condition where item ![]() was selected on a node with question
``f(I,p.name) == sil'' (the previous item to
was selected on a node with question
``f(I,p.name) == sil'' (the previous item to ![]() is a silence).
We have a candidate item
is a silence).
We have a candidate item ![]() . If the answer to
``f(
. If the answer to
``f(![]() ,p.name) == sil'' is ``yes,'' and ``f(
,p.name) == sil'' is ``yes,'' and ``f(![]() ,p.name) == sil'' is ``no'' (i.e. these can be distinguished) then the
score for
,p.name) == sil'' is ``no'' (i.e. these can be distinguished) then the
score for ![]() is the sum of the frequencies below the node. In
the case 42.
is the sum of the frequencies below the node. In
the case 42.
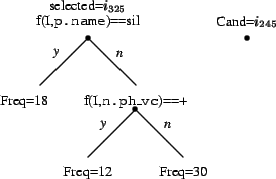
If the sentence contains ![]() is eventually selected,
the tree is modified as follows
is eventually selected,
the tree is modified as follows
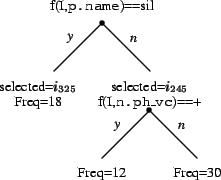
A special condition is needed at the start, as no units have been selected to check if potential new ones can be distinguished. In this case, the score is defined to be the number of occurrences of that phone; that is, the sum of the frequencies of every cluster in the tree.
There are various strategies possible for this scoring. We are looking for the incrementally best addition each time. Some sentences may contain some good units in general but their items are not distinguished immediately from the currently selected items and hence will be scored with 0 even though that sentence my ultimately have been a good example.
The exhaustive search for the best set of items is of course computational very expensive so some compromise is necessary, though we have not investigated if this current strategy is the most reasonable given that constraint. But this method does seem at least partially adequate. Also, this greedy selection technique is not dependent on the order of the sentences in the corpus.
It is important to note that, despite using a greedy algorithm to select utterances, the resulting coverage is still complete, and covers all necessary distinctions - and thus is optimal, given the objective function.