Linear Algebra III
In this problem we will perform basic matrix calculus.
We begin by stating a few rules we will use. Everywhere the notation xi refers to the ith component of a vector x and xi,j refers to the (i,j)th component of a matrix X.
- The derivative of a scalar z with respect to an N×1 vector x is an N×1 vector. The ith component of this vector is dzdxi.
- The derivative of a scalar z with respect to an N×M matrix X is an N×M matrix, whose (i,j)th component is dzdxi,j.
- The derivative of an N×1 vector y with respect to an M×1 vector x is an N×M matrix, whose (i,j)th component is dyidxj.
Note the order of the indices in the following
- The derivative of an N×1 vector y with respect to an M×L matrix X is an N×L×M tensor (note the reversal of the order of L and M), whose (i,j,k)th component is dyidxk,j (again, note the reversal of the order of indices in the denominator -- to get the derivative in the i,j,k location, we differentiate w.r.t to the variable in the k,j location of X.
- The derivative of an N×K matrix Y with respect to an M×L matrix Y is an N×K×L×M tensor, whose (i,j,k,l)th component is dyi,jdxl,k.
- The derivative of an N1×N2×⋯×NL tensor Y with respect to an M1×M2×⋯×MK tensor is an N1×N2×⋯×NL×MK×MK−1×⋯×M1 tensor.
The transpose of any N1×N2 matrix is an N2×N1 matrix. We will represent the transposition operation by the superscript ⊤. Let Y=X⊤. Then yi,j=xj,i ({\em i.e.} the (i,j)-th component of Y is the (j,i)-th component of X.
For the purposes of the computation here, we will expand the notion of transposes to tensors. Let Y be any N1×N2×⋯×NK tensor. By our definition X=Y⊤ is an NK×NK−1×⋯×N1 tensor, whose components are given by xi1,i2,⋯,iK=yiK,iK−1,⋯,ii.
Using the above definitions, we can also write the following chain rule.
- Let X be any matrix (noting that a vector is also a one-column matrix, so the same rule also applies to vectors, or tensors in general). Let g(∙) and h(∙) be two functions. The functions may have scalar, vector or tensor outputs. Let y=g(h(X)) Then dydX=(dh(X)dX)⊤dgdh where dg is shorthand for d(g(h(X))) and dh stands for d(h(X)). Note the order of multplication.
- In general, if f1(∙), f2(∙), f3(∙)⋯ are functions, then if y=f1(f2(f3(⋯fK(X)))) then dydX=(dfK(X)dX)⊤(dfK−1dfK)⊤(dfK−2dfK−1)⊤⋯(df2df1)⊤df1df2 Once again, note the order of computation.
- Let X be an N×M×L tensor. It can only left multiply L×1 vectors. Let y be an L×1 vector. Then Z=Xy is an N×M matrix whose components are given by zi,j=∑kxi,j,kyk
- Let X be an N×M×L tensor. It can only left multiply L×M matrices. Let Y be an L×M matrix. Then Z=XY is an N×1 vector whose components are given by zi=∑j∑kxi,j,kyk,j
A. Derivative of scalar function w.r.t. vector argument
Let x and y be N×1 vectors. Let e=‖ Show that \frac{de}{d{\mathbf x}} = -2\left(z - {\mathbf y}^\top{\mathbf x}\right) {\mathbf y} The derivation is simple, based on rule number 1.B. Derivative of scalar function w.r.t. matrix argument
Let {\mathbf X} be an N\times M matrix, {\mathbf z} be an N \times 1 vector, {\mathbf y} be M\times 1 vectors. Let e = \| {\mathbf z} - {\mathbf X}{\mathbf y}\|^2 Show that \frac{de}{d{\mathbf X}} = -2\left({\mathbf z} - {\mathbf X}{\mathbf y}\right) {\mathbf y}^\topHINT:
For part B., the chain rule gives us: \frac{de}{d{\mathbf X}} = \left(\frac{d{\mathbf X}{\mathbf y}}{d{\mathbf X}}\right)^\top \frac {d \| {\mathbf z} - {\mathbf X}{\mathbf y}\|^2} {d{\mathbf X}{\mathbf y}} Note that {\mathbf X}{\mathbf y} is an N \times 1 vector whose i^{\rm th} component is given by \sum_j x_{i,j}y_j. Therefore, representing {\mathbf u} = {\mathbf X}{\mathbf y}, \frac {d u_i}{d x_{j,k}} = \begin{cases} y_k~~~~if~~j=i\\ 0~~~~~otherwise \end{cases} Thus, although \frac{d{\mathbf u}}{\mathbf X} is an N \times M \times N tensor, only the entries along the diagonal plane i=j are non-zero, and all other terms are zero. That is, if we let {\mathbf V} = \frac{d{\mathbf u}}{{\mathbf X}}, using rule 4 we get v_{i,k,j} = \begin{cases} y_k~~~~if~~i=j\\ 0~~~~~otherwise \end{cases} The resulting Tensor has the structure shown below. Only the diagonal plane shown in the figure has non-zero values. All the remaining values are 0. Each row in the diagonal plane is the vector {\mathbf y}^\top.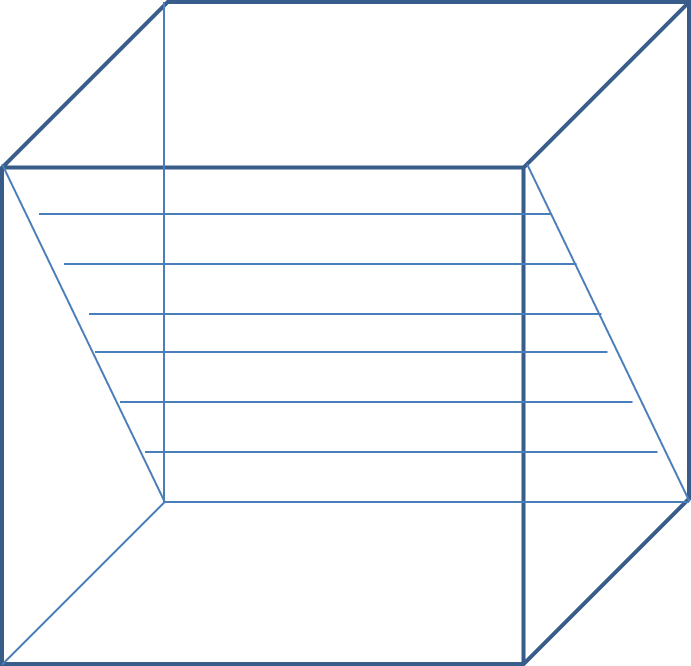
Because of the zero-valued off diagonal elements, tensor transposition has no effect on the tensor. Multiplying this tensor with any M\times 1 vector {\mathbf t} has the following geometric interpretation. The figure below illustrates the operations.

Clearly, since only the diagonal elements have non-zero values, only one of the component-wise products has a non-zero value, and the sum takes this value.
This has the effect that for any M \times 1 vector {\mathbf t}, the matrix {\mathbf S} = {\mathbf V}^\top{\mathbf t} is an M \times N matrix whose components (according to rule 9) are given by s_{k,j} = \sum_{i} v_{i,j,k}t_i = t_ky_j The indices can be verified by referring to the illustration above.