
|
Yang Cai (蔡炀) Master Student Robotics Institute School of Computer Science Carnegie Mellon University Email: caiyang AT cs.cmu.edu Office: 4522 Newell-Simon Hall Phone: 412-268-2029 |
Greeting! I'm a second year master student of Robotics Institute at Carnegie Mellon University. I'm working with my advisor Dr. Alexander G. Hauptmann. I received my B.E. degree in computer science from Zhejiang University in 2011 under the supervision of Prof. Qunsheng Peng. From Jul. 2010 to Sep. 2011, mentored by Mr. Linjun Yang, I enjoyed over one year internship at Media Computing Group, Microsoft Research Asia (MSRA), conducting research on content-based image/video retrieval. My research interests span conputer vision, information retrieval and machine learning. Particularly, I'm interested in developing practical and effective methods to better organize, access and utilize the ever-increasing multimedia data. Here is my CV.
Publications: Journal Papers:
1. Linjun Yang, Bo Geng, Yang Cai, Alan Hanjalic, Xian-Sheng Hua, “Object Retrieval using Visual Query Context”, IEEE Transactions on Multimedia, 2011. [Paper] 2. Yang Cai, Linjun Yang, "Large-scale Near-duplicate Web Video Retrieval - Challenges and Approaches", IEEE Multimedia, 2012, [Paper] 3. Linjun Yang, Yang Cai, Alan Hanjalic, Xian-Sheng Hua, Shipeng Li, “Searching for images by video”, International Journal of Multimedia Information Retrieval, 2012. [Paper]
Conference Papers:1. Yang Cai, Linjun Yang, Wei Ping, Fwei Wang, Tao Mei, Xian-Sheng Hua, Shipeng Li, “Million-scale Near-duplicate Video Retrieval System”, ACM International Conference on Multimedia (ACM MM), Arizona, USA, 2011. [Paper] 2. Linjun Yang, Yang Cai, Alan Hanjalic, Xian-Sheng Hua, Shipeng Li, “Video-based Image Retrieval”, ACM International Conference on Multimedia (ACM MM), Arizona, USA, 2011. [Paper] 3. Yang Cai, Wei Tong, Linjun Yang, Alexander Hauptmann, “Constrained Keypoint Quantization: Towards Better Bag-of-Words Model for Large-scale Multimedia Retrieval”, ACM International Conference on Multimedia Retrieval, Hong Kong, China, 2012.[Paper] 4. Zhigang Ma, Yi Yang, Yang Cai, Nicu Sebe, Alexander Hauptmann, “Knowledge Adaptation for Ad Hoc Multimedia Event Detection with Few Examplars”, ACM International Conference on Multimedia (ACM MM), Nara, Japan, 2012. [Paper] 5. Yang Cai, Qiang Chen, Lisa Brown, Ankur Datta, Quanfu Fan, Rogerio Feris, Shuicheng Yan, Alex Hauptmann, Sharath Pankanti, "CMU-IBM-NUS@TRECVID 2012:Surveillance Event Detection", TRECVID Video Retrieval Evaluation Workshop, NIST, Gaitherburg, MD, USA, 2012. (Rank 1st in Retrospective Surveillance Event Detection Task). [Paper] [Slides] 6. Qiang Chen, Yang Cai, Lisa Brown, Ankur Datta, Quanfu Fan, Rogerio Feris, Shuicheng Yan, Alex Hauptmann and Sharathchandra Pankanti, "Spatio-Temporal Fisher Vector Coding for Surveillance Event Detection", ACM International Conference on Multimedia (ACM MM), Barcelona, Spain, 2013. Accepted, to appear. 7. Yang Cai, Yi Yang, Alexander Hauptmann, Howard Wactlar, "A Cognitive Assistive System for Monitoring the Use of Home Medical Devices", ACM Multimedia Workshop (ACM MM MIIRH),Barcelona, Spain, 2013. Accepted, to appear.
Research Projects:
|
Multimedia Event Detection (MED) Prototype System |

|
|
Abstract: The goal of MED task is to detect videos with the pre-specified events (e.g. birthday party) which are defined by text descriptions and video examples in a large collection of videos. Our team regularly participates the competition and ranked 1st in pre-specified MED of TRECVID 2012. Based on the technologies developed by us, I have been building an integrated web-based prototype of MED system. Different from traditional tag-based retrieval system, it is a purely content-based system where videos are represented by automatically extracted semantic features (e.g. detected concepts, recognized text, etc.) and non-semantic features (e.g. low level visual features). In addition, the detection is done by leveraging both (1) information retrieval techniques (e.g. text indexing/retrieval, content-based image retrieval) and (2) machine learning techniques (e.g. classification using discriminative classifiers). |
|
TRECVID Surveillance Event Detection (SED) Task In TRECVID2012 Workshop [Paper][Slides] In ACM Multimedia 2013 [To appear] |

|
|
Abstract: The goal of SED task is to detect pre-specified events (e.g. person runs, embrace, cell to ear, etc.) in long surveillance video streams. We developed a generic event detection system evaluated in the SED task of TRECVID 2012. It consists of two parts: the retrospective system and the interactive system. The retrospective system uses MoSIFT as low level feature, Fisher Vector encoding to represent samples generated by sliding window approach and linear SVM for event classification. For interactive system, we introduce event-specific visualization schemes for efficient interaction and temporal locality based search method for user feedback utilization. In terms of actual DCR, among the primary runs of all teams our retrospective system ranked 1st and our interactive system ranked 2nd. |
|
Recovering Ground Depth From Single Surveillance Video For Feature Scale Normalization Course Project for Geometry-based Computer Vision [report][slides] |

|
|
Abstract: This is a course project I did for class “Geometry-based Computer Vision” taught by Prof. Martial Hebert (very interesting class taught by a fantastic lecturer: strongly recommended!). The primary goal of this project is to recover depth information from a single surveillance video captured by a fixed RGB camera and to utilize the recovered depth to normalize the scale of motion features which have been pervasively used for surveillance event detection. Most of state-of-art approaches for surveillance event detection are based on local spatial-temporal features (e.g. STIP), where event motion is usually characterized by histogram of flow (HoF). Even though HoF is usually calculated in image pyramid with different scales to achieve scale-invariance, two same motions’ HoF still can be very different if their distances to camera are different (e.g. imagine two people running at the same speed but with different distances to the camera). Because the depth of the motion is the key reason causing the problem, in this project I studied how to recover the ground plane depth from single surveillance camera. |
|
Million-scale Near-duplicate Video Retrieval System In ACM Multimedia 2011 [Paper] In IEEE Multimedia 2012 [Paper] |

|
|
Abstract: Near-duplicate video retrieval has been a hot research topic for the past decades, since it is highly useful for automatic video indexing, management, retrieval, rights protection, etc. The recent rapid growth of the web videos, evidenced by the fact that on YouTube there are over 48 hours videos being uploaded every minute, imposes an urgent need for a practical large-scale near-duplicate video retrieval system, to facilitate users’ consumption of the ever-increasing web videos. In this work, we develop a very large scale near-duplicate video retrieval system, which serves a database comprising one million web videos. To implement such a system, a visual word based approach is proposed, which quantizes each video frame into a word and represents the whole video as a bag of words. Due to the very compact video representation, the system can respond a query in 41ms with 78.4% mean average precision (MAP) on average. To the best of our knowledge, this is the first million-scale near-duplicate video retrieval system. |
|
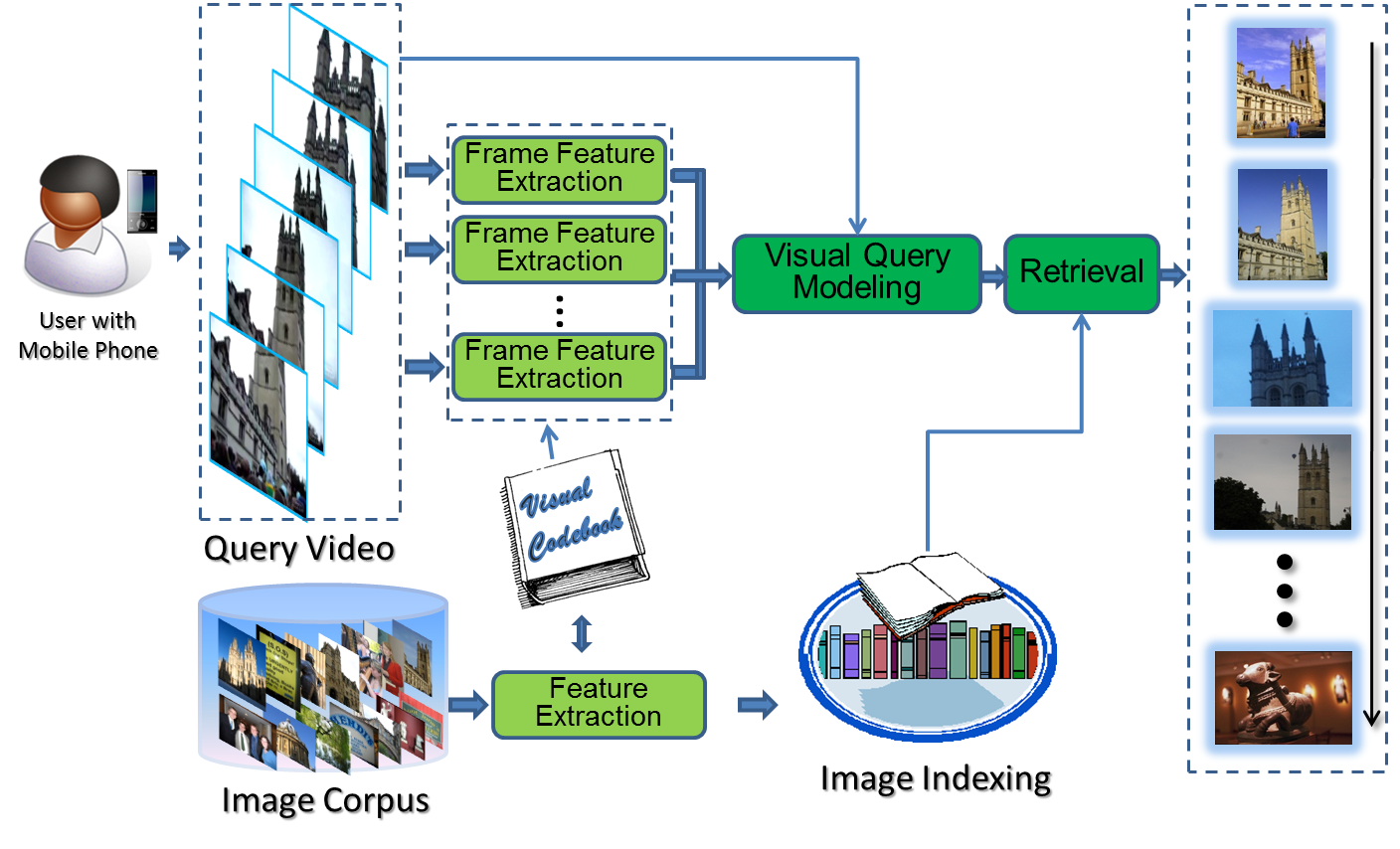
Video-based Image Retrieval In ACM Multimedia 2011 [Paper] In International Journal of Multimedia Information Retrieval [Paper] |

|
|
Abstract: Likely variations in the capture conditions (e.g. light, blur, scale, occlusion) and in the viewpoint between the query image and the images in the collection are the factors due to which image retrieval based on the Query-by-Example (QBE) principle is still not reliable enough (As illustrated by the left figure whose X axis records the indices of a sequence of single frame queries and Y axis is the corresponding average precision). In this project, we develop a novel QBE-based image retrieval system where users are allowed to submit a short video clip as a query to improve the retrieval reliability. Improvement is achieved by integrating the information about different viewpoints and conditions under which object and scene appearances can be captured across different video frames. Rich information extracted from a video can be exploited to generate a more complete query representation than in the case of a single image query and to improve the relevance of the retrieved results. Our experimental results show that video-based image retrieval (VBIR) is significantly more reliable than the retrieval using a single image as a query. |
|
Object Retrieval using Visual Query Context In IEEE Transactions on Multimedia [Paper] |

|
|
Abstract: Object retrieval aims at retrieving images containing objects similar to the query object captured in the region of interest (ROI) of the query image. Boosted by the invention and wide popularity of SIFT image features and bag-of-visual-words image representation, object retrieval has progressed significantly in the past years and has already found deployment in real life applications and products. While existing object retrieval methods perform well in many cases, they may fail to return satisfactory results if the ROI specified by the user is inaccurate or if the object captured there is too small to be represented using discriminative features and consequently to be matched with similar objects in the image collection. In order to improve the object retrieval performance also in these difficult cases, we propose in this work an object retrieval method that exploits the information about the visual context of the query object and employ it to compensate for possible uncertainty in feature-based query object representation. Contextual information is drawn from the visual elements surrounding the query object in the query image. We consider the ROI as an uncertain observation of the latent search intent and the saliency map detected for the query image as a prior. Then a language modeling approach is employed to devise a contextual object retrieval (COR) model. There, the relevance score is determined based on the search intent scores that are inferred from the uncertain ROI and the saliency prior. |