Fast Block
Copy in DRAM
Ningning
Hu & Jichuan Chang
Abstract
Although many techniques have been
exploited to improve the DRAM performance, the ratio of processor speed to DRAM
speed continues to grow rapidly, which makes the DRAM a performance bottleneck
in modern computer systems. In this report, we explore the possibility of
implementing fast block copy operation in DRAM. By writing data in another row
during DRAM refreshing period, we can copy a whole row of data in only two
memory cycles. In order to quantify the usefulness of such an operation, we
first studied the memory copy behavior of typical applications. Aligned and
unaligned row copy and subrow copy instructions are then implemented in SimpleScalar
2.0. The performance improvement of our benchmarks and SPECint95 are
measured and analyzed.
1.
Introduction
DRAM has been used as main memory for over 20 years. During
this time, DRAM density has increased from 1kb/chip to 256Mb/chip, a factor of
256,000, while the latency of DRAM access has only been reduced to 1/10. The
ratio of processor speed to DRAM speed in modern computers continues to grow
rapidly. All these make the DRAM a performance bottleneck of modern computer
system.
One possible way of improving DRAM performance is to exploit
the wide bandwidth within DRAM chip (2-3 orders of magnitude larger than
CPU-memory bandwidth), to copy large amount of data quickly in a single DRAM
chip. Such operations can occur in a DRAM read cycle. In a traditional DRAM
chip, a row of bits is read into a latch upon a RAS signal. After reading the
individual bit within this row, the latched row must be written back to the
same row (since reading operation is destructive). If we can write the content
of latch into an arbitrarily specified row in the same DRAM chip when
refreshing, we can actually copy hundreds of bytes of data in just two DRAM
cycles.
Memory copy operations (memcpy(), bcopy(), etc)
are intensively used in text processing application, networking services,
video/image streaming and operating systems, with different block sizes and
alignment property. In our project, we focus on the opportunity and usefulness
of fast block copy operations in DRAM. This report will introduce our
implementation of DRAMs supporting fast block copy and the simulation results
using fast block copy operations.
The rest of this paper is organized as follows. In section 2,
we will discuss related works. In section 3, we describe the methodology used
in our experiments. In section 4, we will briefly introduce traditional DRAM
organization and how to extend the DRAM hardware to support different kinds of
block copies. In section 5, we present the experiment results and our analysis.
In section 6, we suggest future directions and conclude.
2. Related
works
Many techniques have been used by memory manufactures to
improve the performance of DRAM. Extended data out (EDO) DRAM and synchronous
DRAM (SDRAM) have long been popular. Advanced interface technologies, such as
Rambus RAM (RDRAM), RamLink, and SyncLink are quickly emerging.
Application-specific memories, such as cache DRAM (CDRAM), enhanced DRAM
(EDRAM), video DRAM (VRAM) [3, 4], and Synchronous Pipelined DRAM (SPDRAM) [5],
have achieved better performance in their intended area.
The research community also proposed novel methods to
integrate DRAM with computation logics. For example, The Computational RAM
(C-RAM) brings SIMD computation logic into DRAM by implementing the logic-in
memory at sense-amps [10]. The Intelligent RAM (IRAM) architecture merges the
processor and memory into a single chip to reduce memory access latency,
increases memory size while saving power consumption and board area [9].
There are also many conventional methods to improve the
performance of block copy operations. Non-blocking caches allow the processor
to overlap cache miss stall times with the block movement instructions [11].
Data prefetching are also used to improve the performance of block copy.
Usually the data cache can be bypassed when block transfer operations are
performed. [12] studies the operating system behavior of block copy within IRAM
architecture, which provides complementary result with our project (due to the
restriction of SimpleScalar, we can only observe the behaviors of
applications in user level).
3.
Methodology
We use SimpleScalar 2.0 as our simulator, in which we add
an assemble instruction, blkcp. This instruction is based on the
hardware support of block copy operation within DRAM chip. It can copy a whole
row of DRAM to another new row during the refreshing period of DRAM operation
in 2 cycles, or subrow copy in 3 cycles. We run our simulator on the office
PCs: Pentium III processor running at 733MHz, with 256MB main memory.
There are at least two important factors that influent the
relevance and usefulness of blkcp instructions: (1) the frequency of
block copy operations in different kinds of applications, and 2) the block
sizes and alignment property of these block copy operations. These data should
be collected in both kernel and user modes, by observing all kinds of library
functions that use block copy operations (including bcopy() and memcpy()).
But currently SimpleScalar2.0 doesn’t simulate the kernel mode operations,
and provides limited support of library customization on Linux platform. This
has limited our approach to only observe user applications and instrument only
two library functions: bcopy() and memcpy(). One possible future
work should be to collect data in all possible cases, to do comprehensive
simulation and analysis.
We didn’t have the chance to do detailed hardware simulation,
but block diagram and sequence diagram are described in section 4 to show that
the DRAM can be extended to support fast copy operations.
To start from the simplest case, we restrict that both source
and destination addresses have the same offset with respect to the row size of
DRAM, with which we can copy the source to destination row-by-row. But
according to Figure 1, we realize that aligned whole row copy is seldom the
case for real world applications. So it is necessary for us to consider how to
support the unaligned whole row copy, as well as aligned or unaligned subrow copy.
In our simulation experiments, we inspect the performance improvement for all
these kinds of block copy operations.
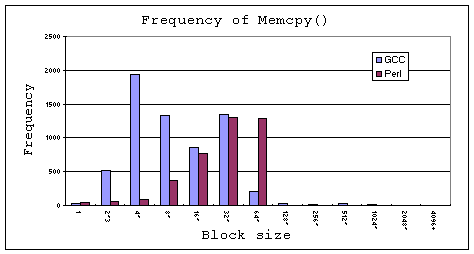
Figure 1. Block sizes of memory copy operations in GCC
and Perl.
1. Aligned
row copy: In this mode, blkcp
assumes the source and destination addresses are both aligned with row
boundary. This is the simplest case, and it could make full use of existing
DRAM hardware.
2. Unaligned row copy: In this case, we
remove the strict restriction of aligned row copy by allowing source address
not be aligned with the row boundary. Consequently, for general memory copies,
we could first process the beginning part of the destination, and then process
the remaining memory with the aligned destination address. We will show that our
design only needs three cycles to finish work[1].
3. Subrow copy: Commodity DRAM has
very large row size, for example, 1024 bits. Consequently, in the above two
modes, only very few memory copies can use the blkcp instruction. To
alleviate this situation, subrow copy is implemented. By using mask and shift
registers in DRAM, blkcp can copy one subrow into another subrow
quickly. Subrow copy can be implemented in hardware to support only aligned
(with respect to 2n memory address boundary) or unaligned copy, they
both can finish in three cycles. So our hardware diagram only presents the more
general, unaligned case. In our software simulation, we consider both cases,
the difference is that aligned subrow copy is usually used less. This is
especially significant when block size is large (>64). But for our
benchmarks, the difference is little. So in section 4, we present the result
using unaligned copy, except explicitly mentioned (for example, in fileread).
4. DRAMs Supporting Fast
Block Copy Operation
4.1. DRAM Organization and operations
In
the traditional DRAM, any storage location can be randomly accessed for
read/write by inputting the address of the corresponding storage location. A
typical DRAM of bit capacity 2N * 2M consists of an array
of memory cells arranged in 2N rows (word-lines) and 2M
columns (bit-lines). Each memory cell has a unique location represented by the
intersection of word and bit line. Memory cell consists of a transistor and a
capacitor. The charge on the capacitor represents 0 or 1 for the memory cell.
The support circuitry for the DRAM chip is used to read/write to a memory cell.
It includes:
a) Address decoders to select
a row and a column.
b) Sense amps to detect and
amplify the charge in the capacitor of the memory cell.
c) Read/Write logic to
read/store information in the memory cell.
d) Output Enable logic that
controls whether data should appear at the outputs.
e) Refresh counters to keep
track of refresh sequence.
DRAM
Memory is arranged in a XY grid pattern of rows and columns. First, the row
address is sent to the memory chip and latched, then the column address is sent
in a similar fashion. This row and column-addressing scheme (called
multiplexing) allows a large memory address to use fewer pins. The charge
stored in the chosen memory cell is amplified using the sense amplifier and
then routed to the output pin. Read/Write is controlled using the read/write
logic. [1]

Figure
2. Hardware Diagram of Typical DRAM (2 N x 2N x 1)
A
typical DRAM read operation includes the following steps (refer to Figure 2):
1. The row address is
placed on the address pins visa the address bus
2. RAS pin is activated,
which places the row address onto the Row Address Latch.
3. The Row Address Decoder selects
the proper row to be sent to the sense amps.
4. The Write Enable is
deactivated, so the DRAM knows that it’s not being written to.
5. The column address is
placed on the address pins via the address bus
6. The CAS pin is
activated, which places the column address on the Column Address Latch
7. The CAS pin also serves
as the Output Enable, so once the CAS signal has stabilized the sense amps
place the data from the selected row and column on the Data Out pin so that it
can travel the data bus back out into the system.
8. RAS and CAS are both
deactivated so that the cycle can begin again. [2]
4.2 Block Diagrams
Some important assumptions are introduced to simplify the
implementation of blkcp:
·
The source and destination block are in the same DRAM chip.
We currently don’t support block copy across DRAM chips.
·
There is no overlap between the source and destination blocks.
·
Blkcp
operation
does use register file and is not cacheable.
1M
x 1 DRAM is chosen to illustrate our implementation.
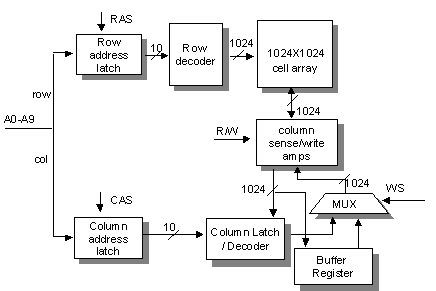
Figure 3. DRAM chip supporting aligned row copy (1M x
1)
4.2.1 Aligned DRAM Row Copy
The
block diagram of DRAM is shown in Figure 3. We add two new components in DRAM
chip: a Buffer Register and a MUX (multiplexer). The Buffer Register is used to
temporarily store the source row, and the MUX is used to choose the write back
data used in refresh period: under normal condition, column latch should be
chosen to refresh, but during row copy mode, WS is raised and Buffer Register
is chosen. Steps of copy operation are listed in the table below. It could
finish block copy in 2 cycles:
|
Cycle |
Action |
Result |
|
1 |
Fit
A0-A9 with SRC row address Raise
RAS |
Column
latch and row buffer now contains the source row data |
|
Raise
R/W |
Refresh
the SRC row (column latch write back to SRC) |
|
|
2 |
Fit
A0-A9 with DST row address Raise
RAS |
|
|
Raise
R/W, raise WS |
Data
in SRC is written back to DST when refreshing. |
4.2.2 Unaligned DRAM Row Copy
The DRAM block diagram supporting unaligned row copy is
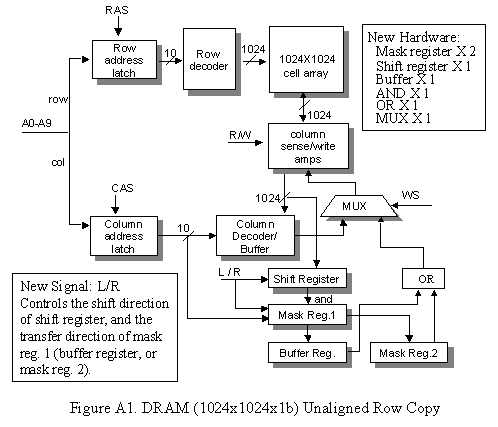
included in Appendix A (Figure A1). More hardware are added, including one
shift register, two mask register, one buffer register, one OR logic and one
MUX. As the source address is not aligned, we need 2 cycles to read out a row
size buffer before write to the destination row. Steps of copy operation is
show below:
|
Cycle |
Action |
Result |
|
1 |
Fit
A0-A9 with SRC’s row address Raise
RAS |
Column
latch and Shifter Reg. store the SRC row |
|
Raise
R/W Shift
Reg. shifts SRC’s data to the higher half and transfer to Mask Reg1. |
Column
latch is written back to cell array (refresh) |
|
|
2 |
Fit
A0-A9 with the next row address Raise
RAS Mask
Reg.1 make the lower half bits with 0, and write its content to Buffer Reg. |
Column
latch and Shifter Reg. store the SRC row |
|
Raise
R/W, raise L/S Shift
Reg. shift the row content to the lower half and transfer to Mask Reg.2 |
Column
latch is written back to cell array (refresh) |
|
|
3 |
Fit
A0- A9 with DST row address Raise
RAS, raise L/S Mask
Reg.2 clear the higher bits |
Mask
Reg. 2 stores later half or SRC data that will be written back to DST row. |
|
Raise
R/W, raise WS Buffer
Reg. “OR” Mask Reg2 |
Combined
SRC row is written to DST row |
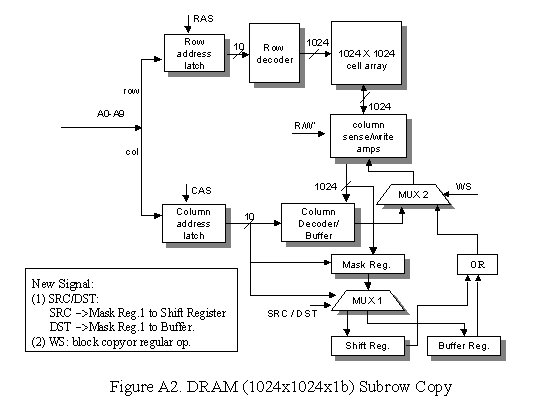
4.2.3 DRAM Subrow Copy
In this mode, part of the source row (eg. 32b of the 1024b
in a row) can be copied into a subrow destination. It assumes that both the
source subrow and the destination subrow stay within a single row, that is,
they don’t cross the row boundary. The DRAM chip diagram is shown in Appendix A
(Figure A2). The design is similar to that of unaligned row copy DRAM. Steps of
copy operation is show below:
|
Cycle |
Action |
Result |
|
1 |
Fit
A0-A9 with row address Raise
RAS |
Mask
Reg is filled with the src row |
|
Fit
A0-A9 with src subrow column address Raise
CAS, and R/W Mask
Reg set the other bits other than the source subrow with 0 Raise
SRC signal for MUX1 |
Column
latch is written back to cell array (refresh) Shift
Reg. is filled with the source subrow |
|
|
2 |
Fit
A0-A9 with DST’s subrow address Raise
RAS |
Mask
Reg is filled with DST’s data |
|
Fit
A0-A9 with the DST column address Raise
CAS Shift
Reg. shift SRC to DST’s column address Mask
Reg fill the DSR with 0 Raise
DST signal for MUX1 |
Shift
Reg. is filled with shifted SRC data; Buffer Reg. is filled with masked DST
data. |
|
|
3 |
Fit
A0- A9 with DST address Raise
RAS, and R/W Combine
Buffer Reg. and Shift Reg. using OR Raise
WS |
Subrow
SRC is written into DST |
5. Simulation Results and
Analysis
5.1 Simulation Method
5.1.1 Extending the Simulator
SimpleScalar2.0 is used to simulate the effect
of our new block copy operations. We add an instruction (blkcp) into
SimpleScalar’s instruction set, so that assembly programmer can use it to do
fast block copy. Two commonly used block copy functions (bcopy() and memcpy())
are re-implemented using blkcp instruction, the SimpleScalar library is
updated so that C program can use blkcp by calling the library
functions. The implementation is described as below:
a. Add blkcp
into SimpleScalar’s instruction set architecture
In SimpleScalar2.0,
assembly instruction is defined as a C procedure [8]. For example, in the
aligned row copy case (block size = 1024 bytes), blkcp can be defined as following:
b. Modify
library functions to utilize the new instruction
In Linux, memory copy operations are achieved by calling
library function memcpy() and bcopy().
We rewrite them using blkcp, and replace the SimpleScalar library using their new implementations. Our
experiences (which are later confirmed by SimpleScalar’s authors) show that it
is hard to rebuild the Glib in SimpleScalar2.0,
so we simply substitute memcpy.o and bcopy.o in the precompiled
library libc.a of SimpleScalar2.0. Our selected benchmarks are
linked with new library to use blkcp.
An effective way to implement block copy is to simply do a
small number of byte copies at the block’s beginning and ends, so that there is
a maximal destination blocks aligned in the middle part. Our memcpy()
and bcopy() function implementation follows this method. It first judges
whether it’s beneficial to use blkcp instruction. For example, in aligned
row copy, it should check that: (a) memory block to be copied includes at least
one physical row (not just larger than the row size); (b) source and
destination addresses have the same row offset. For operation satisfying the
requirements, block copy will use blkcp;
otherwise the data are copied byte-by-byte (or word-by-word).
If (src and dst meet requirements) {
// non-overlap, and buffer long enough
copy beginning (or ending) unaligned bytes;
block copy the aligned chucks using blkcp;
copy remained unaligned bytes;
}
else {
do memory copy byte-by-byte;
}
5.1.2 Relevant Metrics
In
our experiments, we focus on three performance metrics: (1) Total number of
instructions executed (IN); (2) Total number of memory references (MRN); (3)
Total number of blkcp used. IN and
MRN could not reflect the performance changes directly, because blkcp may
need two or three cycles to finish, and this can’t be reflected in
SimpleScalar. Actually, execution time and memory operation time are the best
metrics to evaluate the performance improvement. But both of them could not be used
as performance metrics in SimpleScalar2.0.
Because, in SimpleScalar2.0, each
instruction is implemented in the form of C procedure, and one instruction
assumed to finish in one cycle actually uses a few lines of C code, which uses
several real machine cycles and makes the real execution time meaningless.
Anyway the frequencies of operations still provide much information about the
performance.
5.1.3 Benchmark
A suitable benchmark for our experiments should meet three
requirements:
(1) Use a
lot of block copy operations;
(2) Block
size are large enough to utilize our blkcp instruction;
(3) Can be
built on SimpleScalar 2.0 to use the
special version of bcopy() & memcpy().
So far, we haven’t found such a benchmark that satisfies
these requirements simultaneously. We have tried to use SPECint95 as our
benchmarks. But for the eight of benchmarks that we could get source code, only
four could be rebuilt (the others need libraries which are not supported by SimpleScalar), and only one of them has
enough block copy operations to be used in our experiments. We also tried other
benchmarks (such as SPLASH – water and ocean), but similar problems remain. Due
to above limitations, we have to write our own benchmarks. Although
self-designed benchmarks have many problems in terms of generality and comparability,
they are useful for us to get the idea about how and when the block copy scheme
can improve the performance. Below we will briefly introduce our benchmarks:
Memcopy
This
benchmark will simulate the behavior of execution of memory intensive application.
It mainly uses two classes of instructions: arithmetic/logic and load/store.
The runtime execution times of ALU/MEM instructions are chosen randomly (but
reasonably large). We wan to test the adaptability of blkcp to various block sizes using this benchmark. Below shows its
pseudo-code:
memcopy
{
pick a random number n1 from 100
to 100,000;
do ALU operations by n1 times;
fill source buffer;
pick another random number buf_len from
1 to 2048;
/* des, src aligned with the biggest
possible row size */
memcpy(dst, src, buf_len);
}
Fileread
This benchmark is used to simulate the behavior of a
networking server, for example http or ftp server. It is known that, a genetic
http server (support static content only) could be implemented as following. In step
(b), (c) and (d), there are generally a lot of memory copy operations carried
out by the operating system to move data between buffers.
network_server_simulator
{
(a) listen for request, parse and check
access rights
(b) read static file;
(c) transform the content into desired
format;
(d) send the result back to client;
}
To
our surprise, we also found that when the application’s read buffer is large
enough (20 Bytes in SimpleScalar’s Glib implementation), fread()
also calls memcpy() to transfer data from system buffer to local buffer.
Since all our source data are big files whose length are large enough, a lot of
memcpy() operations occur. To simplify the analysis and isolate the
effect of blkcp on file system, we write the fileread benchmark, which
only reads files. It is more general because file reading is heavily used in
both kernel mode and user mode.
Perl
Perl is the only benchmark
chosen from SPECint95. It is a Perl language interpreter, which reads in a Perl
script and executes it by interpretation.
5.2. Result and Analysis
In out experiments, we combine the
data get from the three block copy modes. The experiment result with block size
of 1024 is collected using whole row block copy; others are using subrow copy.
Whether aligned or unaligned copy is used will be specified explicitly. Below
we will discuss different benchmarks respectively.
5.2.1
Memcopy
As
memcopy only involves aligned block copy, it is used to get the best
performance improvement that can be expected. Experimental data are shown in
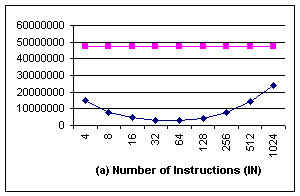
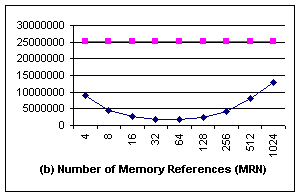
Figure 4. We can see that both IN and MRN are greatly reduced, performance is
improved by terms of 2 to 30!
But
the improvement is not monotonic: it is the best when block size is 16 bytes
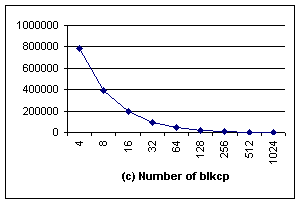
and 32 bytes. Because when block size is small (eg, 4 bytes or 8 bytes), most
of memory copies could make use of blkcp,
but the total number of blkcp used is
also large (Fig 4c). On the other hand, when the block size is large (eg, 512
bytes or 1024 bytes), blkcp could
copy a lot of memory once, but only can be used less frequently, and a large
portion of block copy is realized byte-by-byte. The bigger the block size, the more
bytes has to be treated in the normal way, that’s why the performance get worse
when block size is too large. The top line shows our implementation of naïve
memcpy algorithm (copy byte-by-byte), which has a large amount of memory
operations.
|
|
|
|
|
Figure 4. Experimental results of memcopy using unaligned blkcp. In (a) and (b) the top line doesn’t use blkcp, the lower curve is the result using blkcp. The x-axe represents the size of block supported by blkcp. |
5.2.2
Fileread
Figure
5 shows the results of fileread, the curves are very similar with the
aligned mode in Figure 4. The results from fileread tell us that, in the
normal programs, unaligned blkcp
could achieve good improvement for those systems having intensive memory
operations (say, by reading large files).
|
|
|
|
|
|
|
|
|
|
Figure 5. Experimental results for fileread, using unaligned blkcp. In (a) and (b) the top line is the data got without using blkcp, the lower curve is the one using blkcp. The x-axe represents the size of block supported by blkcp. |
Figure
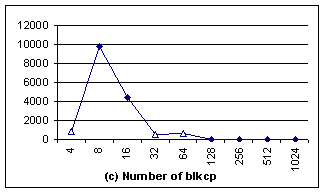
6. Experimental results for fileread, using aligned blkcp. In (a)
and (b) the top line is the data got without using blkcp, the lower curve is the one using blkcp. The x-axe represents the size of block supported by blkcp. |
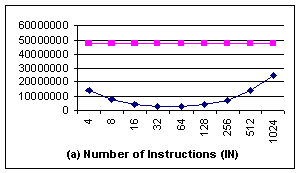
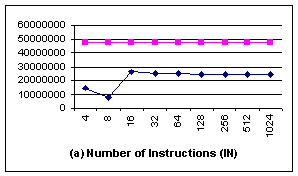
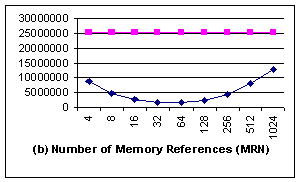
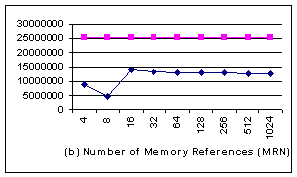
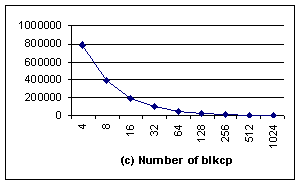
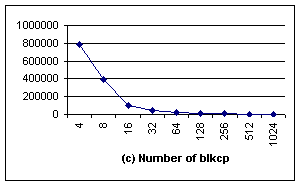
In the aligned case (Figure 6), although for
all different block sizes, there are significant performance improvements,
especially when the block size is 4 bytes and 8 bytes. The reason is that the
system buffer used in fread() can be actually aligned or unaligned to
different block size, and is not controlled by user application. When the I/O
buffer addresses are only aligned with 8, but the block size of blkcp is 16
bytes or larger, memcpy() can seldom use blkcp, as illustrated by Fig 6c[2].
Consequently, both IN and MRN for those large block sizes are much larger than those
of 4 bytes and 8 bytes.
The experiment results for the aligned case actually vary
with different executions (some time block size of 16 bytes or even 32 bytes
also improves performance significantly). And Figure 6 is a typical execution
snapshot selected among them. It strongly suggests that if the operating system
can intentionally allocate buffer aligned with the block size of blkcp,
the kernel mode performance will also be improved.
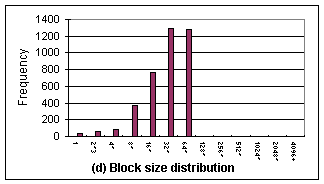
5.2.3
Perl
Figure
7 shows the result of Perl. For this benchmark, performance improvement
is not obvious, because there is only a small fraction (compared with memcopy
and fileread) of memory copy operations and the block sizes are
usually within 64 (Figure 7d). What makes thing worse is that this benchmark
failed to finish its execution when the block size is 4, 32, and 64 bytes,
which are marked with hollow triangles in Figure 7. We hypothesize that some
execution mechanisms in Perl conflict with the design of SimpleScalar in these three cases.
Omitting
those wrong data, we still could find that, within the range of the buffer
size, blkcp indeed improves the
performance, but rather small compared with memcopy and fileread.
|
|
|
|
|
|
|
Figure 7. Experimental results for perl, using unaligned blkcp.
In (a) and (b) the top line is the data got without using blkcp, the lower curve is the one
using blkcp. The x-axe represents
the block size supported by blkcp. Hollow triangles are incomplete
execution results. |
|


6.
Conclusion
Our
experiments show that for those systems frequently using large block memory
copy operations, blkcp could indeed improve the performance
significantly, just as illustrated by our first two benchmarks. It also
suggests that the performance of block copy in operating system, such as in
file systems, memory management subsystem, networking protocol stacks, can be
also significantly enhanced. But for the applications in which memory copy
operations do not dominate the performance overhead, we could not expect such
optimistic improvement by just using block copy.
There
are also some limitations in our approach. First, we did not consider the
overhead caused by the introduction of new hardware in our design. Currently,
we haven’t test the feasibility of our hardware design, but it’s apparent that
to implement such a DRAM chip is not easy or cheap. Also, as we only consider
one memory bank in our design, interleaved memory organization is ignored in
our study. The restriction of our simulator also limit the scope of our study,
currently only user mode applications are simulated, and little improvement has
been achieved on most conventional benchmarks. Some people might say that the
result is too conservative because we only modified the implementation of bcopy
and memcpy used by user application, while others might say that our
result is too optimistic because our own benchmark stress block copy operations
too much. We should consider combining the user and kernel mode simulation and
much realistic benchmarks in future research.
It’s
still difficult to conclude whether the hardware cost of such a block copy
operation could be justified. But we can say that in some cases, the
performance improvement is really large and can be used in some domain-specific
application (say, NFS). Future work should be done in comparing the result with
approaches using data prefetching and non-blocking cache. Furthermore, some
other logic and arithmetic operations should also be considered to make full
use of the new hardware we added.
Reference
[1]
Tulika Mitra, Dynamic Random Access Memory: A Survey. Research
Proficiency Examination Report, SUNY Stony Brook, March 1999
[2] RAM Guide. http://arstechnica.com/paedia/r/ram_guide/ram_guide.part1-4.html
[3] Yoichi Oshima, Bing Sheu, Teve H. Jen. High-Speed Architectures
for Multimedia Applications. Circuit & Device, pp 8-13, Jan. 1997
[4] Hiroaki Ikeda and Hidemori Inukai. High-Speed DRAM Architecture Development. IEEE Journal of Solid-State
Circuits, pp 685-692, Vol. 34, No. 5, May 1999
[5] Chi-Weon Yoon, Yon-Kyun
Im, Seon-Ho Han, Hoi-Jun Yoo and Tae-Sung Jung. A Fast Synchronous Pipelined
DRAM (SP-DRAM) Architecture With SRAM Buffers. ICVC, pp 285-288, Oct, 1999.
[6] Doug Burger, Todd. M. Austin. The
SimpleScalar Tool Set, Version 2.0. University of Wisconsin-Madison
Computer Sciences Department Technical Report #1342, June, 1997.
[7] Todd M. Austin. Hardware and Software
Mechanisms for Reducing Load Latency. Ph.D. Thesis, April 1996.
[8] Todd M. Austin. A Hacher’s Guide to the
SimpleScalar Architectural Research Tool Set. ftp://ftp.simplescalar.org/pub/doc/hack_guide.pdf.
[9] David Patterson, Thomas
Anderson, Neal Cardwell, Richard Fromm, Kimberly Keeton, Christoforos Kozyrakis,
Randi Thomas, and Katherine Yelick. A
Case for Intelligent RAM: IRAM. IEEE Micro, April 1997.
[10] Duncan G. Elliott, W. Martin Snelgrove, and Michael Stumm. Computational RAM: A Memory-SIMD
Hybrid and its Application to DSP. In Custom Integrated Circuits
Conference, pp 30.6.1-30.6.4, Boston, MA, May 1992.
[11] Rosenblum, M., et
al., The Impact of Architectural Trends on Operating System Performance,
15th ACM SOSP, pp 285-298, Dec. 1995.
[12] Richard Fromm, Utilizing
the on-chip IRAM bandwidth, Course Project Report, UC Berkeley, 1996
Appendix A: DRAMs supporting
unaligned row copy and subrow copy