Text Segmentation in the Informedia Project
|
Faculty
Mentor: |
|
Alex
Hauptmann (alex@cs.cmu.edu) |
|
Students: |
|
Zhirong Wang (Zhirong@cs) Ningning Hu
(hnn@cs) Jichuan Chang (cjc@cs) |
Abstract
In this paper, we report our experiences of building text segmenter for the Informedia project. Several methods are used in our project; their experimental results are compared and analyzed. Based on the application background of Informedia project, we choose to use relaxed error metrics to do performance evaluation.
1.
Introduction
2.
Our
Approach
2.1 Data Collection and
Preparation
2.2
Support Vector Machine
·
Rainbow: Rainbow is a statistical text
classification tool built on top of the Bow library. It first
build an index file by counting word in training data, then a SVM classifier
are trained and used to classify the testing data.
In our experiment, the performance is similar with Naive Bayes
classification (although achieved in much longer time).
·
SVMlight is a SVM tool built for
text classification. It accepts vector (of word counts) or sparse vector input.
After counting the number of distinct word, we realized that even for SVM,
there are too many features to train a classifier.
In order to reduce the dimension of feature space within several hundreds, we decide to choose only the words with the highest average mutual information. To simplify the computation, we actually chose words from the sentences sitting just before and after the boundary, which have the largest difference between their occurrence probability in boundary blocks and background blocks.
The result is disappointing mainly because SVMlight takes too much to learn. For a simple case with 500 training data (actually 3 passages), the training process finished in 15 minutes (out machine runs Linux on top of a Intel Pentium III box). The training time increases quickly with the training data size, when we change the size of training data into 1600 (about 8 passages) if failed to finish after 15 hours[1].
2.3 Neural Network
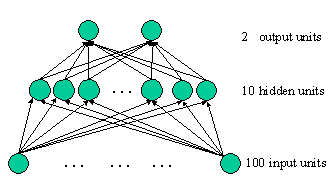
2.4
Naive Bayes Classification
2.5
Topic Change Detection
·
Number of topics
·
Size of sliding window
Table 1 shows the result of different segmenter built with different sliding window size and number of topics. According to this result, we can see that clustering into more topics can improve the overall classification accuracy. But limited by Rainbow’s processing ability, we only have the time to get such result.
|
|
Recall |
Precision |
|||||
|
Topics Size |
4 |
6 |
8 |
4 |
6 |
8 |
|
|
8 |
0.321839 |
0.256177 |
0.311724 |
0.196568 |
0.248424 |
0.365696 |
|
|
|
16 |
0.421456 |
0.360208 |
0.38069 |
0.198198 |
0.267633 |
0.353846 |
Table 1. Segmentation performance using topic change detection method
2.6
Fixed Length Text Segmentation
This part will
be finished by Zhirong Wang.
3.
Experimental
Result and Analysis
3.1 Error Metrics
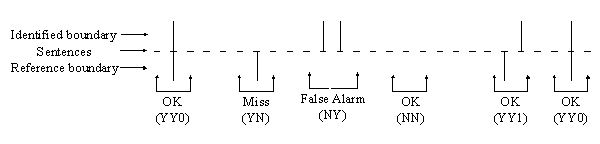 Figure 2. Failure model of sentence-based text segmentation
method (Adapted from [7])
Figure 2. Failure model of sentence-based text segmentation
method (Adapted from [7])
(YY# means under the degree of relaxation #, identified boundary is OK.)
|
|||||
|
0.263 |
0.516 |
|
|||
|
0.331 |
0.648 |
|
|||
|
2 |
0.336 |
0.772 |
0.383 |
0.749 |
|
Table 2. Performance of ANN segmentation
Performance Evaluation
(1) SVM: Rainbow and SVMlight
|
|
SVMligh |
|
|
Recall |
0.07 |
?? |
|
Precision |
0.223 |
?? |
(2) ANN
2.1. Impact of Training Data Distribution
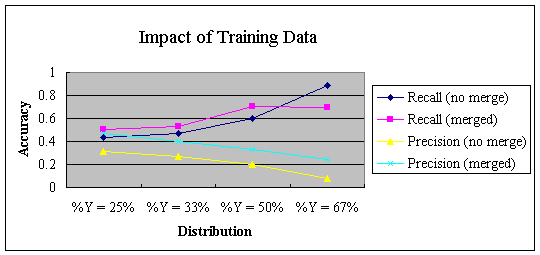
Figure 3. Impact of Training Data Distribution
|
100 Input Units |
No Stop Words |
No Stop Words |
||
|
Recall |
0.597 |
0.721 |
0.705 |
0.846 |
|
Precision |
0.201 |
0.115 |
0.327 |
0.208 |
|
|
100 Input Units (No merge) |
200 Input Units |
||
|
Recall |
0.597 |
0.628 |
0.705 |
0.739 |
|
Precision |
0.201 |
0.137 |
0.327 |
0.219 |
|
|
%Y = 25% |
%Y = 33% |
%Y = 50% |
|
Recall |
0.589 |
0.777 |
0.888 |
|
Precision |
0.122 |
0.100 |
0.009 |
|
Recall |
4 |
6 |
8 |
Precision |
4 |
6 |
8 |
|
# topics = 8 |
0.322 |
0.256 |
0.312 |
# topics = 8 |
0.197 |
0.248 |
0.366 |
|
# topics =16 |
0.421 |
0.360 |
0.381 |
# topics =16 |
0.198 |
0.268 |
0.354 |
This part will
be finished by Zhirong Wang.
(6) Performance of different segmentation methods
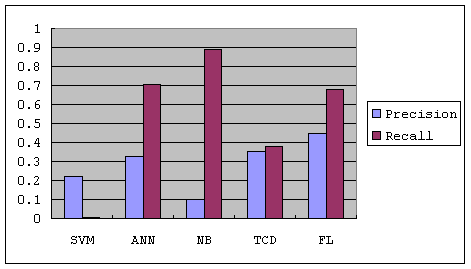
Figure 4. Segmentation Accuracy
4.
Conclusion
Appendix A: Top 50 Features used in ANN experiments
|
Without Stop Word Removal |
After Stop Word Removal |
||
|
CNN |
OF |
CNN |
WORLDVIEW |
|
THE |
A |
REPORTS |
__USA__ |
|
OF |
I |
CAPTIONING |
UNITED |
|
IT |
THAT |
__NUM__ |
CLINTON |
|
TO |
AND |
CLOSED |
THINK |
|
REPORTS |
IN |
WORLDVIEW |
PRESIDENT |
|
AND |
IT |
ADDITION |
STATES |
|
THAT |
WORLDVIEW |
REPORTING |
__NUM__ |
|
IS |
THEY |
BELL |
CNN |
|
THIS |
WE |
LONDON |
SPACE |
|
CAPTIONING |
__USA__ |
PROVIDED |
WORLD |
|
ON |
ON |
ORDERED |
IRAQ |
|
A |
YOU |
THINK |
PRINCESS |
|
__NUM__ |
HE |
HEART |
DAY |
|
THEY |
BE |
JERUSALEM |
DIANA |
|
WE |
THERE |
ATLANTIC |
WELL |
|
ARE |
DO |
WASHINGTON |
ISRAEL |
|
CLOSED |
TO |
WALTER |
NEW |
|
BY |
HAVE |
RODGERS |
JUDY |
|
THERE |
FOR |
PEOPLE |
AHEAD |
|
WORLDVIEW |
UNITED |
COMMUNICATION |
GET |
|
AT |
THIS |
WHITE |
TODAY |
|
I |
WILL |
THANK |
FIRST |
|
DO |
CLINTON |
CORRESPONDENT |
MILITARY |
|
ADDITION |
FROM |
MOSCOW |
MONEY |