15-212-ML : Homework Assignment 3
Due Wed Oct. 7, 12 noon (electronically); papers at recitation.
Maximum Points: 100 (+30 extra credit)
Guidelines
-
Strive for elegance! Not every program which runs deserves full credit.
Make sure to state invariants in comments which are sometimes implicit
in the informal presentation of an exercise. If auxiliary functions are
required, describe concisely what they implement. Do not reinvent the wheel
and try to make your functions small and easy to understand. Use
tasteful layout and avoid longwinded and contorted code.
-
Make sure that your file compiles and runs. A program which doesn't run
will not get full credit and is likely to incur a heavy penalty.
-
Home works must be all your own work.
-
Late home works will be accepted only until start lecture on Thursday,
with a 25% penalty.
-
If you have any questions about this assignment, contact Philip Wickline
at philipw@cs.cmu.edu, Adam
Megacz at megacz@usa.net , or use cmu.andrew.academic.cs.15-212-ML.discuss.
Problem 1: Dictionaries (35 points + 10 extra credit)
Binary trees are a particularly useful and versatile data structure. As
described in the lecture notes, a binary search tree is a binary
tree with values of an ordered type at the nodes arranged in such a way
that for every node in the tree, the value at that node is greater than
the value at any node in the left child of that node, and smaller than
the value at any node in the right child. Thus an inorder traversal
of the tree will yield an enumeration of the values in the tree from least
to greatest. This representation invariant makes makes binary search
trees efficient structures to search, taking time proportional to lg(n)
to find element in a balanced tree, where n is the number of elements
in the tree.
However, without taking special care, trees that are built from arbitrary
insertions of data are not necessarily balanced, meaning that searches
may take time O(n) in the worst case. There are many mechanisms
for building balanced binary search trees. One such mechanism, red-black
trees, is described in the lecture notes. For problem 1 you will implement
balanced binary trees using a balancing criterion based upon tree height.
We define the height, h(t), of trees inductively on the structure
of the tree:
h(empty) = 0
h(t) = 1 + max(h(t.left), h(t.right))
where t.left and t.right are the left and right children of t, empty is
the empty tree, and max is the function which returns the greater
of its two arguments. In other words h(t) is zero if the tree is
empty, and the one more than the height of the largest child otherwise.
The idea is to store at each node the height of that node in the tree.
Then, when new trees are constructed from old trees, the new tree can be
balanced by means of one of the rotations described below. In addition
to the binary search tree invariant described above, you must maintain
the following invariant at each node with height greater than 2:
h(l) <= h(r) * w and
h(l) * w >= h(r)
where w is a constant called the weight ratio, l is the
left child, and r is the height of the right child. In other words,
at every node, neither child is more than w times the height of
the other.
There are four rotations that you will use to keep trees balanced: single
left, single right, double left, and double right. The two left rotations
are presented pictorially below; the right rotations are just the mirror
images of these.

A single rotation lifts Z relative to X and Y, while a double rotation
lifts Y. Therefore, when balancing trees, you should use a double rotation
if Y is taller, or a single rotation if Z is taller.
Question 1.1 (35 points)
Write a structure Dict with the basic types described in the DICT
signature (5 points) and the empty, lookup, insert (20
points), and fold (10 points) values.
signature DICT =
sig
type key = string
type 'a entry = key * 'a
type 'a dict
val empty : 'a dict
val lookup : 'a dict * key -> 'a option
val insert : 'a dict * 'a entry -> 'a dict
val fold : ('a * 'b * 'b -> 'b) -> 'b -> 'a dict -> 'b
(*val delete : 'a dict * key -> 'a dict (* extra credit
*) *)
end; (* signature DICT *)
Use w = 3 and use the following datatype as the representation
type of an 'a dict.
datatype 'a dict =
E
| T of 'a entry * int * 'a dict * 'a dict; (* data * height
* left child * right child *)
(* Invariants (writing height(t) for the height of tree t):
1. t : s dict is a binary search tree
2. For every tree t = T (e, h, left, right), h = height(t)
3. For every tree t = T (e, h, left, right),
height(left) <= w*height(right)
and height(right) <= w*height(left)
*)
-
empty should be the empty tree
-
lookup (tree, key) should return SOME of the value associated
with key in tree if it is in the tree, and NONE
otherwise
-
insert (tree, (key, value)) should take a balanced tree
tree and an entry (key, value) and return a balanced
tree with the new entry in it. If key already exists in the tree,
the old entry should be replaced with the new.
-
fold f init d should go through the binary tree d
and return init if it encounters a leaf (i.e. the empty tree).
For every other node in the tree it should return f(datum,vLeft,vRight)
where datum is the datum of the node, and vLeft is the
result of applying fold on the left subtree of d, vRight
is the result of applying fold on the right subtree of d.
NOTE: Make sure to annotate all your functions with the invariants
they expect for the arguments! Otherwise the graders may not be able
to understand and assess the correctness of your implementation!
Hint: Your code will be much easier to understand if you use a helper
function balance (not visible in the signature!) which
takes an entry a and two balanced trees, X and Y,
whose heights are not too much out of balance (you need to decide how much
that is, it will be an invariant of the function), and constructs the balanced
tree derived from the tree
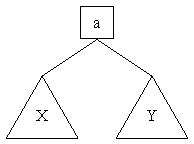
using one of the rotations, if necessary. Again, be sure to state all
of the invariants balance expects from its arguments.
Question 1.3 (Extra Credit, 10 points)
Write the function delete which takes a key and a tree and returns a balanced
version of the tree created by removing the entry with the given key from
the tree. No exception should be raised if the key is not in the tree.
Problem 2: An Address Book (30 points)
For this problem you will write a simple address book utility using the
dictionary structure implemented in problem 1. The purpose is to become
familiar with programming using a strict interface. You will need to know
how to use record types for this exercise. Read pp. 32-35 in Paulson if
you don't already know about records.
The following signature ADDRESSBOOK
describes address books:
signature ADDRESSBOOK =
sig
type key = string
type entry =
{Key : key,
LastName : string,
FirstName : string,
Nickname : string option,
Email : string,
OfficeBuilding : string,
OfficeNumber : int}
type address_book
val empty : address_book
val addEntry : address_book
* entry -> address_book
val lookup : address_book
* key -> entry option
exception NotFound of
key
val updateNickName :
address_book * key * string -> address_book
val updateEmail : address_book
* key * string -> address_book
val updateOfficeBuilding
: address_book * key * string -> address_book
val updateOfficeNumber
: address_book * key * int -> address_book
(* question 2.2 & 2.3
*)
val getRange address_book
* key * key -> entry list
end
The address book will store entry records with information
about the people listed in the address book. The entries should be
stored with the concatenation of the last name and the first name as keys.
For instance the entry with LastName = "Wickline" and FirstName
= "Philip" should have Key = "WicklinePhilip", and should
be stored with key "WicklinePhilip" in the collection of entries.
Question 2.1 (10 points)
Implement a structure AddressBook with the types described in
ADDRESSBOOK and the empty, addEntry, lookup,
and various updateFoo functions.
-
empty should be the empty address book
-
addEntry(book, entry) creates a new address book extending book
with the key #Key entry mapped to entry
-
lookup(book, key) returns SOME of the entry associated
with key in book, if one exists, and NONE otherwise
-
updateFoo(book, key, value) should return a new address book which
is identical to book except that the Foo field of the record associated
with key contains value. If key does not occur
in book, then the exception NotFound key should be raised.
Question 2.2 (10 points)
Write the function getRange which when given an address book and
a pair of keys, returns the list of all entries in the book whose keys
are alphabetically between the two keys, inclusive. For example, if the
address book book has entries with keys "WatkinSarah", "SmithJose",
and "SmithJoseph", the call getRange(book, "SmithJose", "Taylor")
should return the entries associated with the keys "SmithJose" and
"SmithJoseph", in no particular order. What is the time complexity
of this function? Why is it less efficient than a simple lookup?
Question 2.3 (10 points)
Extend the signature and implementation of dictionaries to add facilities
to make the getRange function more efficient. Call the the
new signature DICT1 and the structure Dict1. Modify
your address book structure to use this new dictionary structure, and call
the new address book structure AddressBook1.
Problem 3: Regular expressions (35 points + 20 extra credit)
In class five different operators have been introduced to describe regular
expressions R:
-
Characters a
-
Concatenation r1 r2
-
The empty string One
-
Alternative r1 + r2
-
Empty set Zero
-
Repetition r*
This has been implemented as the following datatype.
datatype regexp =
Char of char
| Times of regexp * regexp
| One
| Plus of regexp * regexp
| Zero
| Star of regexp;
From time to time it is helpful to have some more constructs available
to form regular expressions, such as
-
A wildcard symbol _ which accepts any character
L(_) = {a | a is a character in the alphabet}
The constructor must be called Underscore.
-
Intersection r1 & r2 which
accepts a string only if it is contained in r1 and simultaneously
in r2.
L(r1 & r2) = {s
| s in L(r1) and s in L(r2)}
The constructor must be called And.
-
A wildcard T which matches any string.
L(T) = {s | s is a string over the alphabet}
The constructor must be called Top.
-
Negation ~ r which contains every string which is not
contained in r.
L(~ r) = {s | s not in r}
The constructor must be called Not.
The regular expression matcher accept is available in the file
regexp.sml and should be extended to
deal with these new constructors. Remind yourself of the specification
of the acc function and make sure your new cases fit this specification.
You should also generate some test data to validate your implementation.
Note that for the purposes of our implementation, the alphabet is simply
any ML value of type char.
Question 3.1 (5 points)
Implement the case for the one-character wildcard _.
Question 3.2 (15 points)
Implement the case for intersection r1 & r2.
Question 3.3 (15 points)
Implement the case for T.
Question 3.4 (Extra credit, 10 points)
Prove the correctness of the case for intersection in your implementation,
following the pattern in the handout.
Question 3.5 (Extra credit, 10 points)
Implement the case for Negation.
Handin instructions
-
Put your SML code into a single file named ass3.sml in your ass3
directory. All of your definitions should be in this one file. Please keep
a backup for your records. Your handin directory for this assignment is
/afs/andrew/scs/cs/15-212-ML/studentdir/<your andrew id>/ass3/ass3.sml