1.1 kNN on R21578:
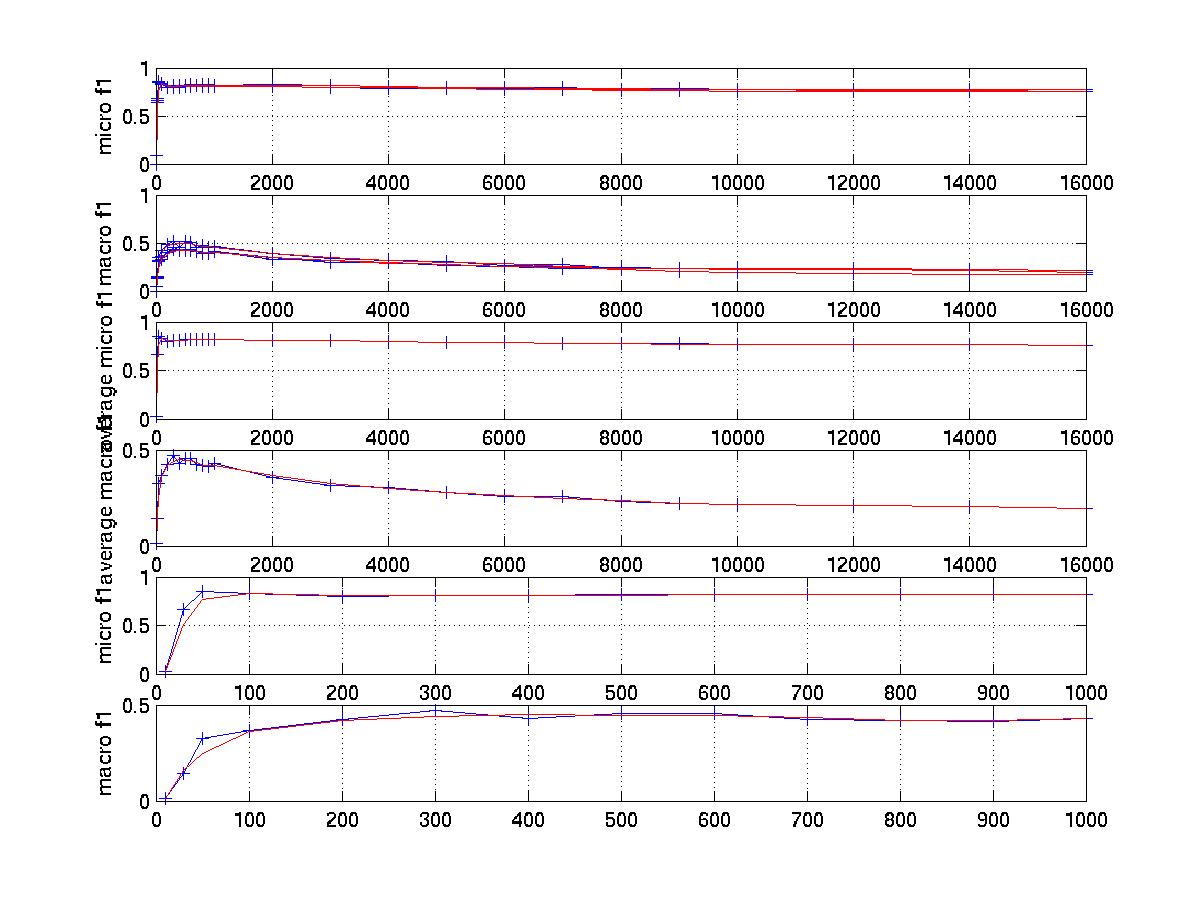
Result for microF1 and Result for macroF1
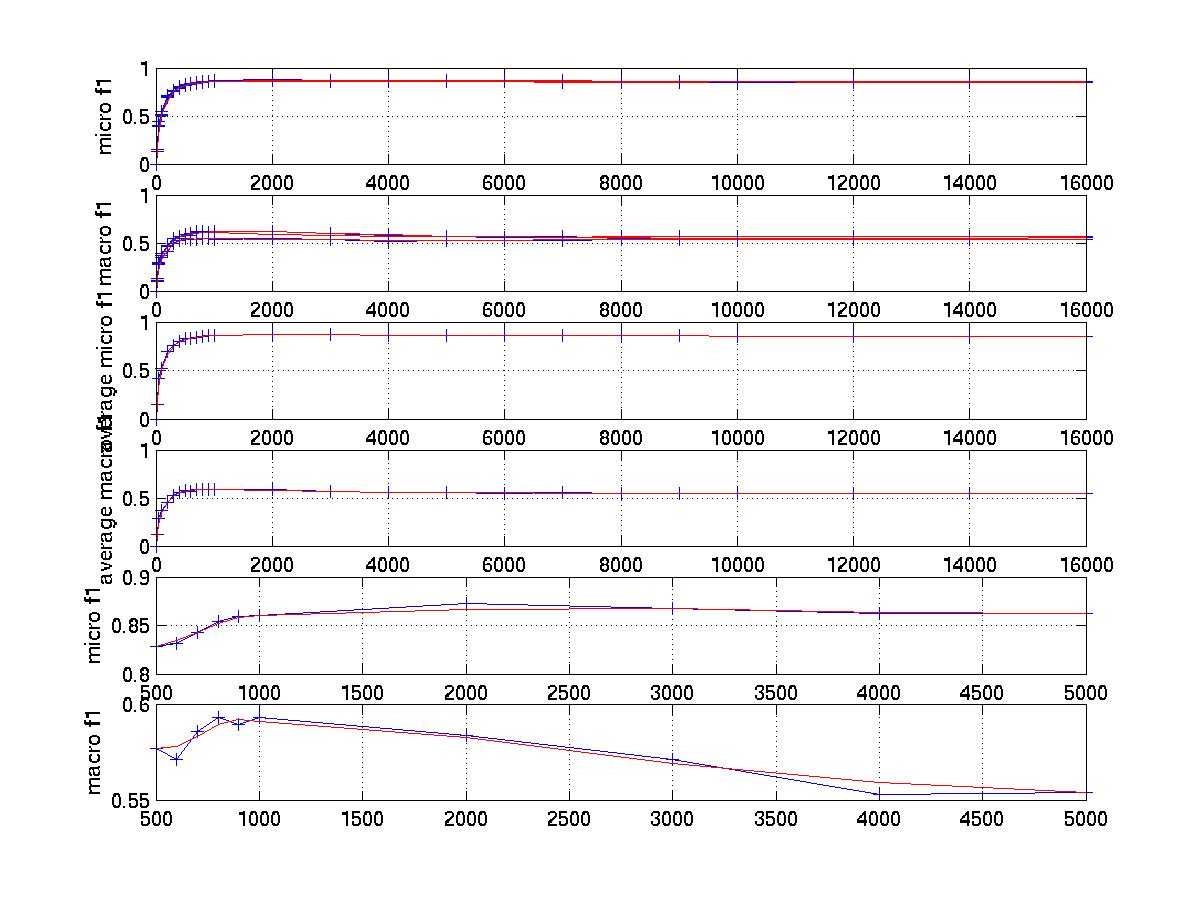
The graph
that tunes feature selection (2000 is the best number for microf1 and
1000 is better for macrof1)
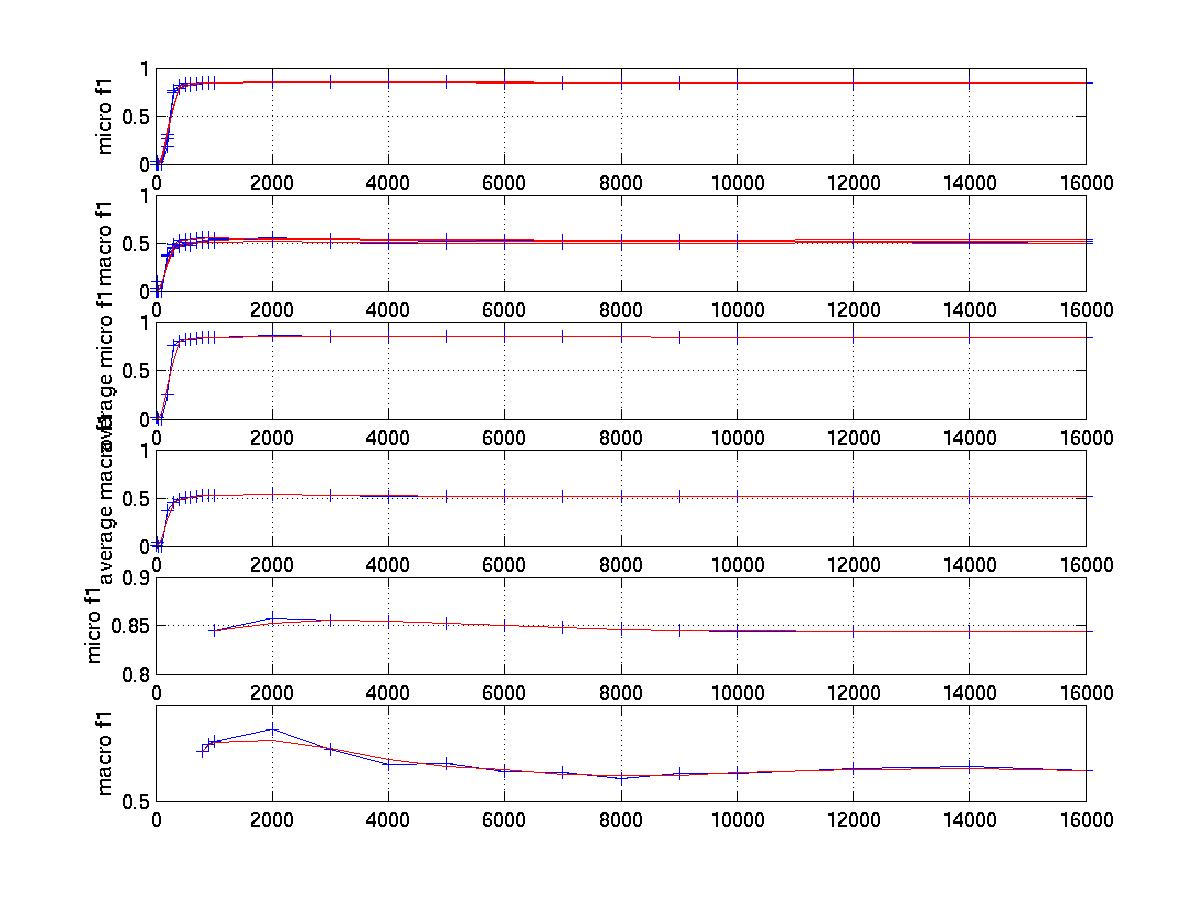
The graph that tunes nearest neighbor
number K (85 is the approximate best number for both microf1 and macrof1)
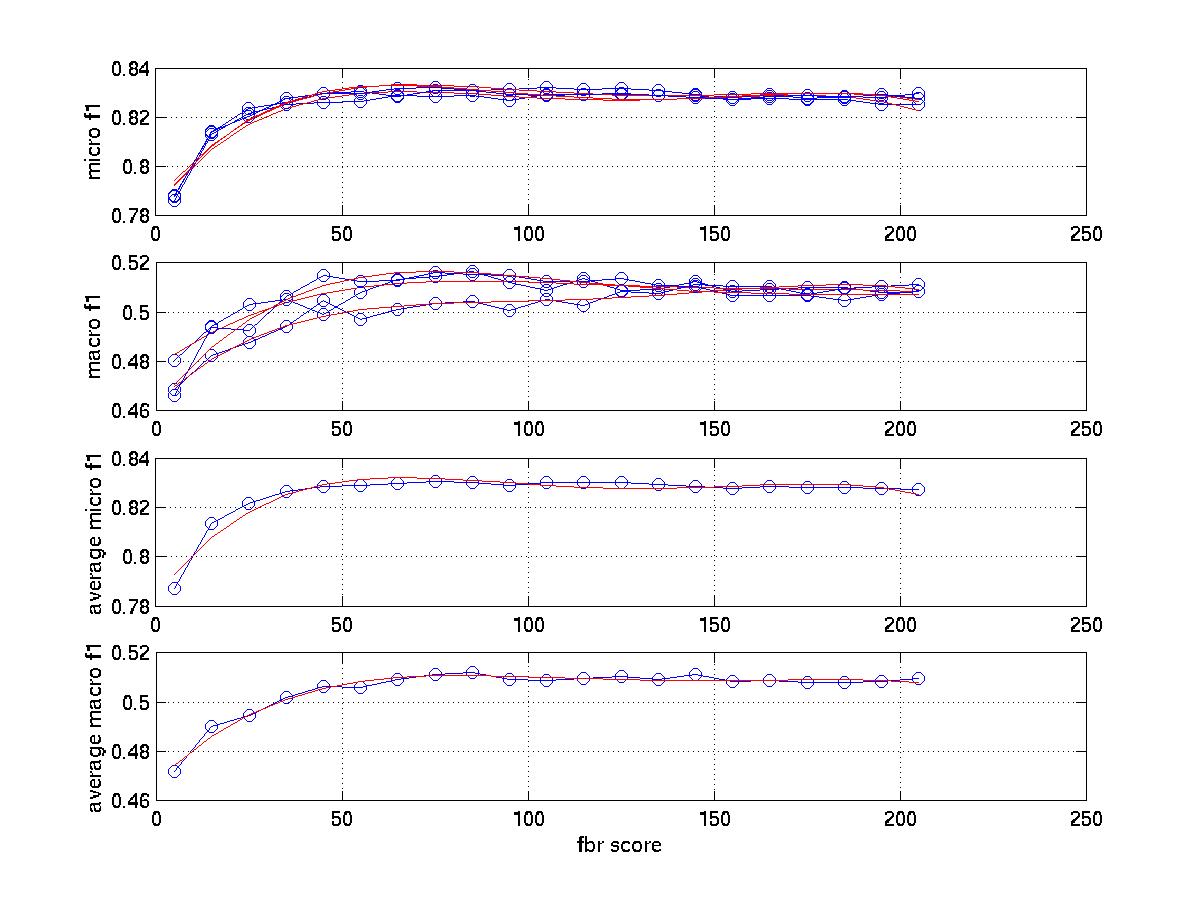
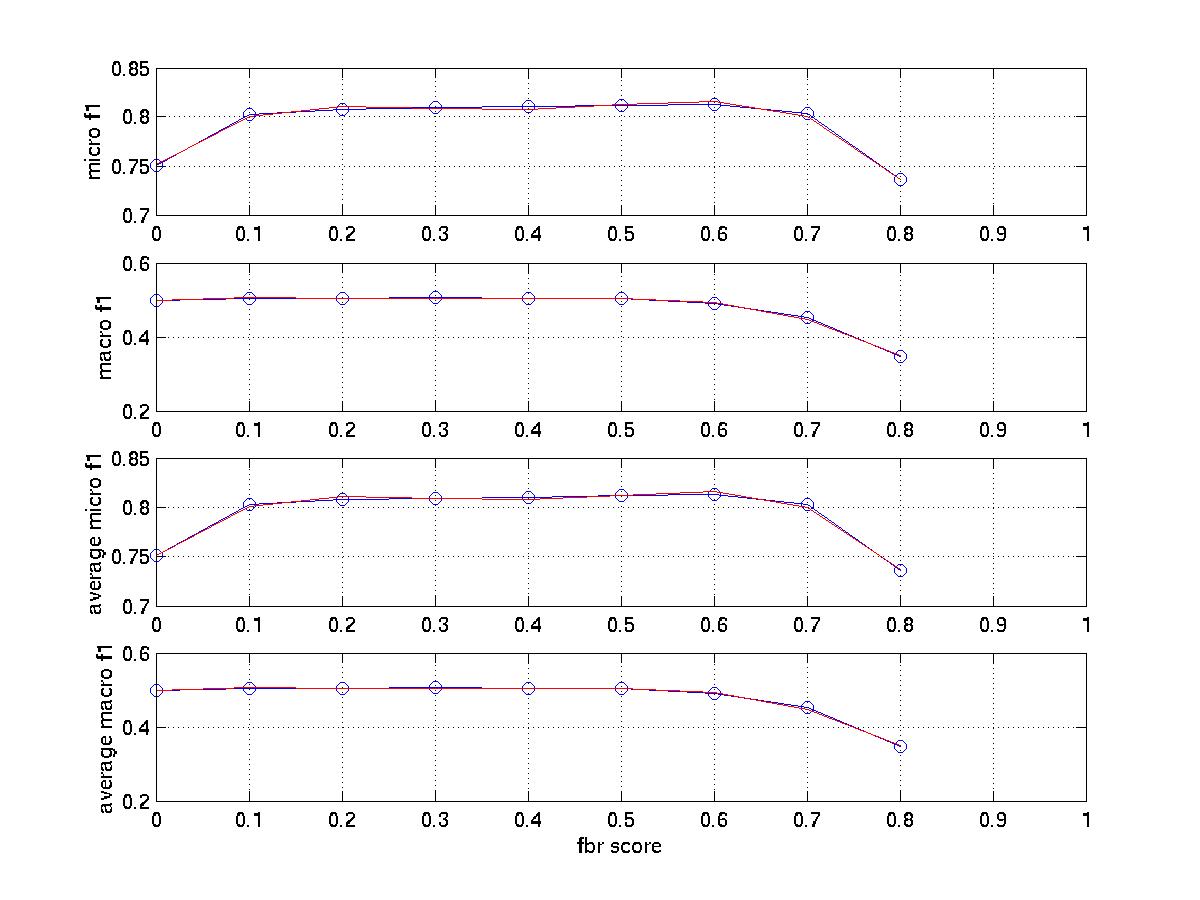
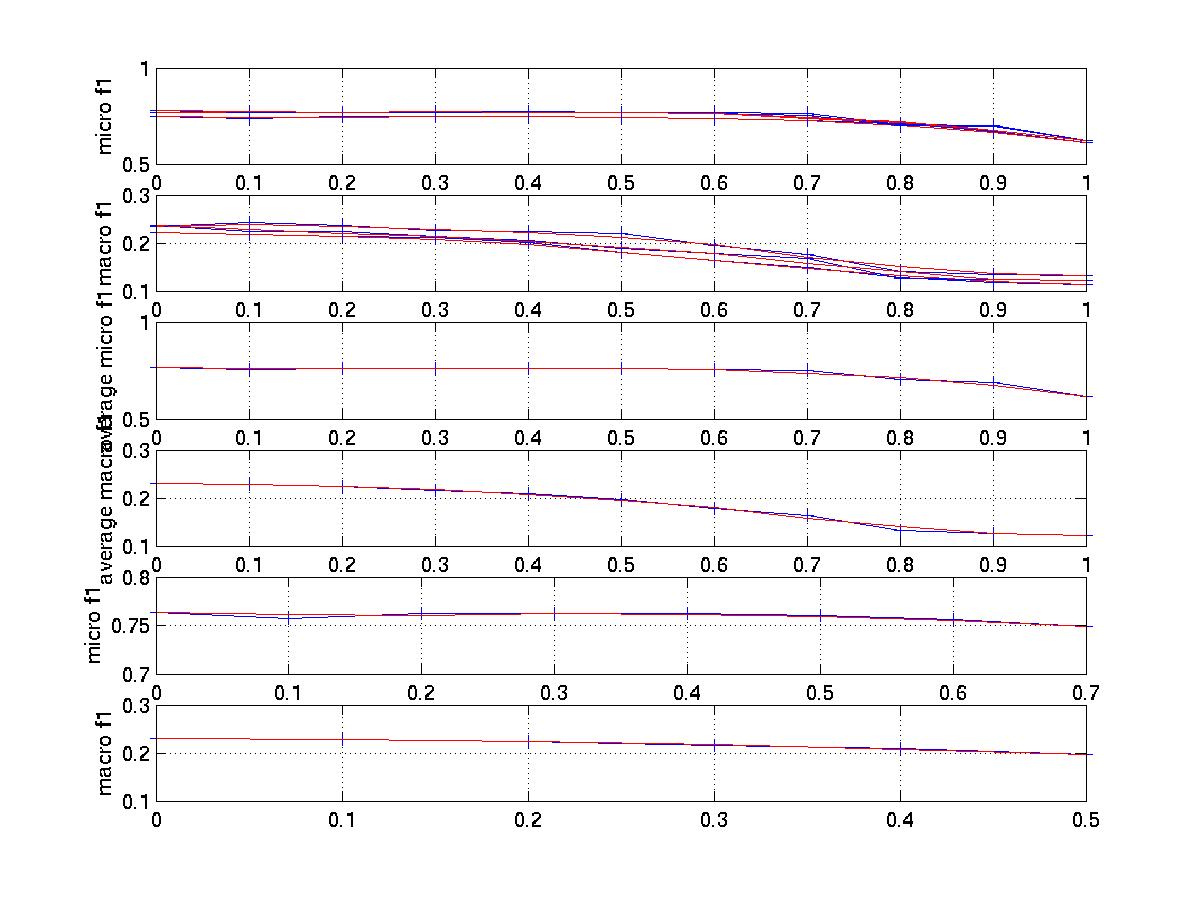
The
graph that tunes fbr score (0.6 is the best number for microf1 and
0.4 for macrof1)
(It need be noticed that the term-weighting method used here is ooc,
NOT ltc. All the other other classifiers have used ltc)
notice: The blue line represent real dots
while the red line represents regression fit. First two subplots of every
graph show 3 fold cross validation curves. The next two subplots show the
average results over the 3 fold cross validations. The last two subplot
show the key area of the above graphs so that the curve can be observed
more clearly.
Observation: The feature selection curve is stable and reasonable. The curve that tunes K with micro average F1 is also stable while the curve for macro average F1 has much larger variance. It has been mentioned the best K is near 45 in [1]. This point is proved by our micro F1 curve . However it seems the best K for macro average f1 should be larger than 45. In fact, when K increase, the curve first increases, than remains stable. I also tuned fbr score. while always using fbr rank =1 because R21578's average category number per document is 1.23 for training set and 1.24 for test set. The significance of tuning fbr score is that we can see whether scut is better or rcut (r=1)is better and the tradeoff between them. The best fbr score is 0.5 in [1]. I think this is for micro avg f1. My finial micro result is very close to that in [1] ( 0.8573 vs 0.8567) while my finial macro result is much higher (0.6146 vs 0.5242).
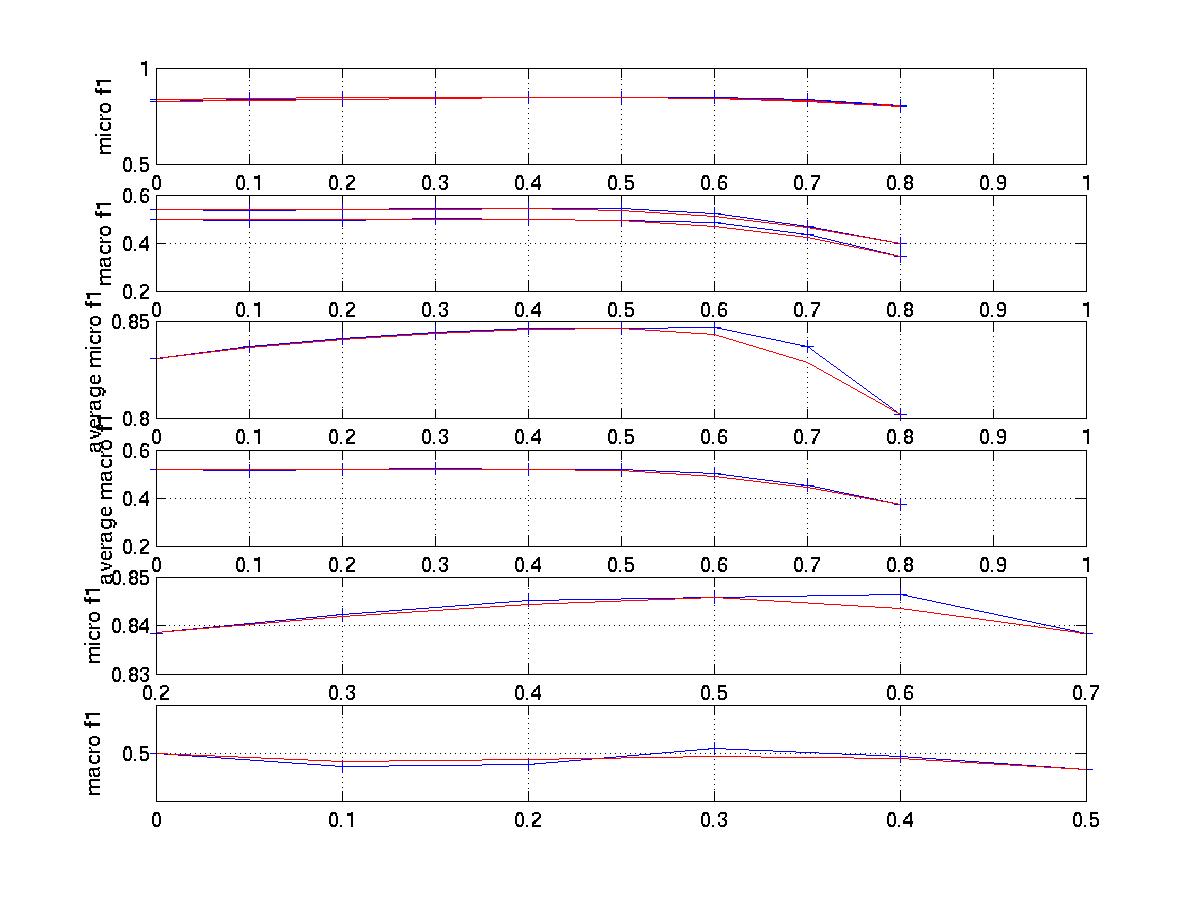
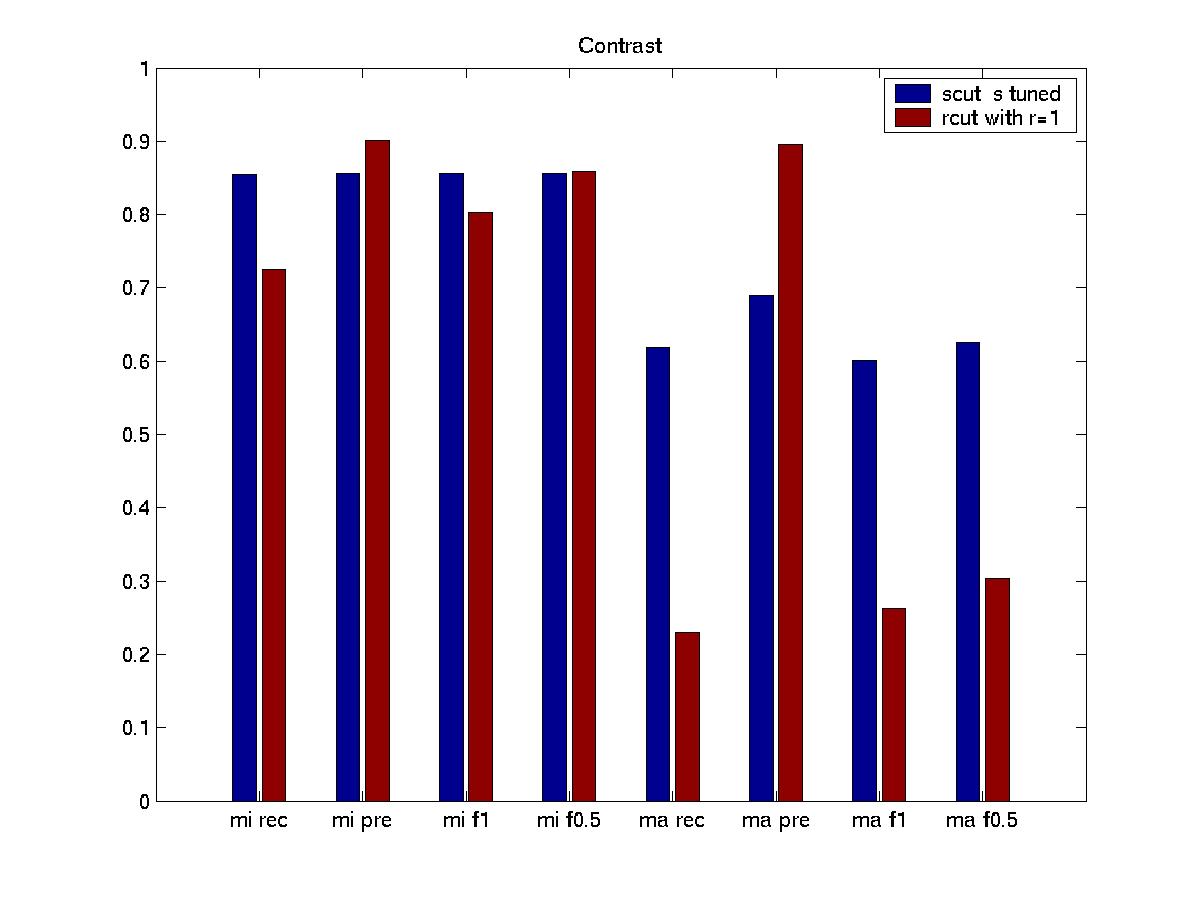
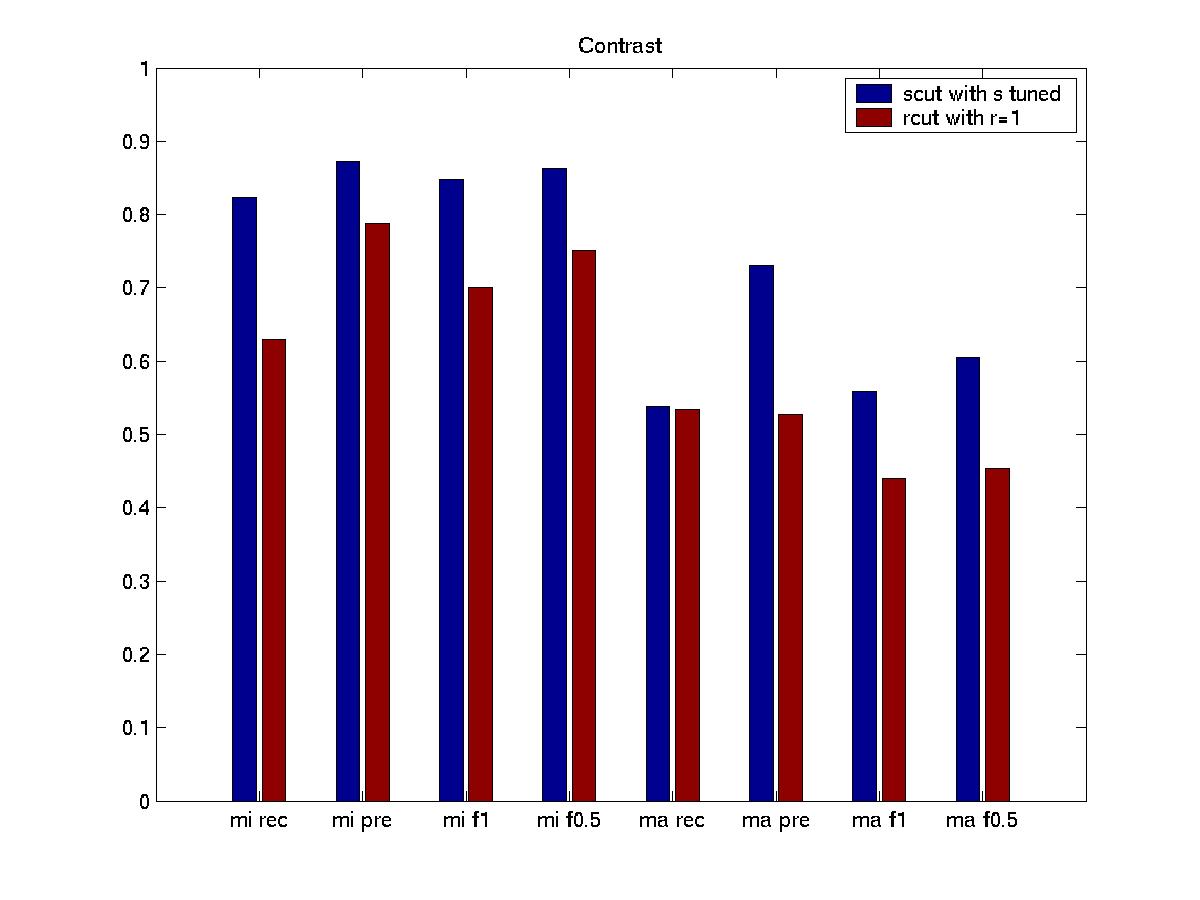
This is a graph
that compares the scut with s tuned and rcut with r=1. It shows when considering
micro avg. result, scut has higher recall while rcut has
has higher precision. scut's f1 is a little better than rcut and they
have comparable f0.5 value. However, when considering macro result, rcut
performs
very poor. Though it still has higher precision, its other measures
are far lower than scut.
1.2 Rocchio on R21578
Result
for microF1 and Result
for macroF1
The graph
for tuning feature selection number (2000 is the best number for both
microf1 and macro)
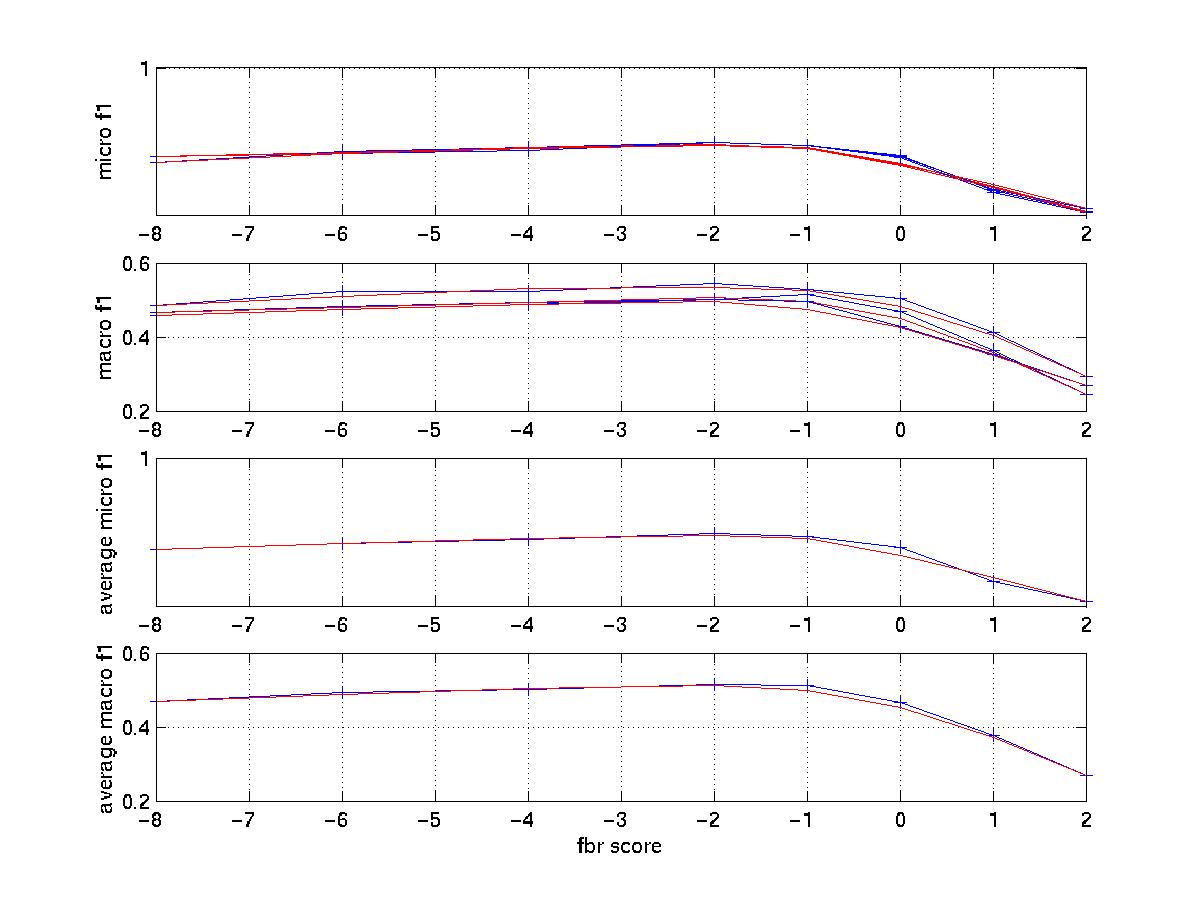
The graph for tuning fbr score
(0.6 is the best number for microf1 and 0.3 for macrof1)
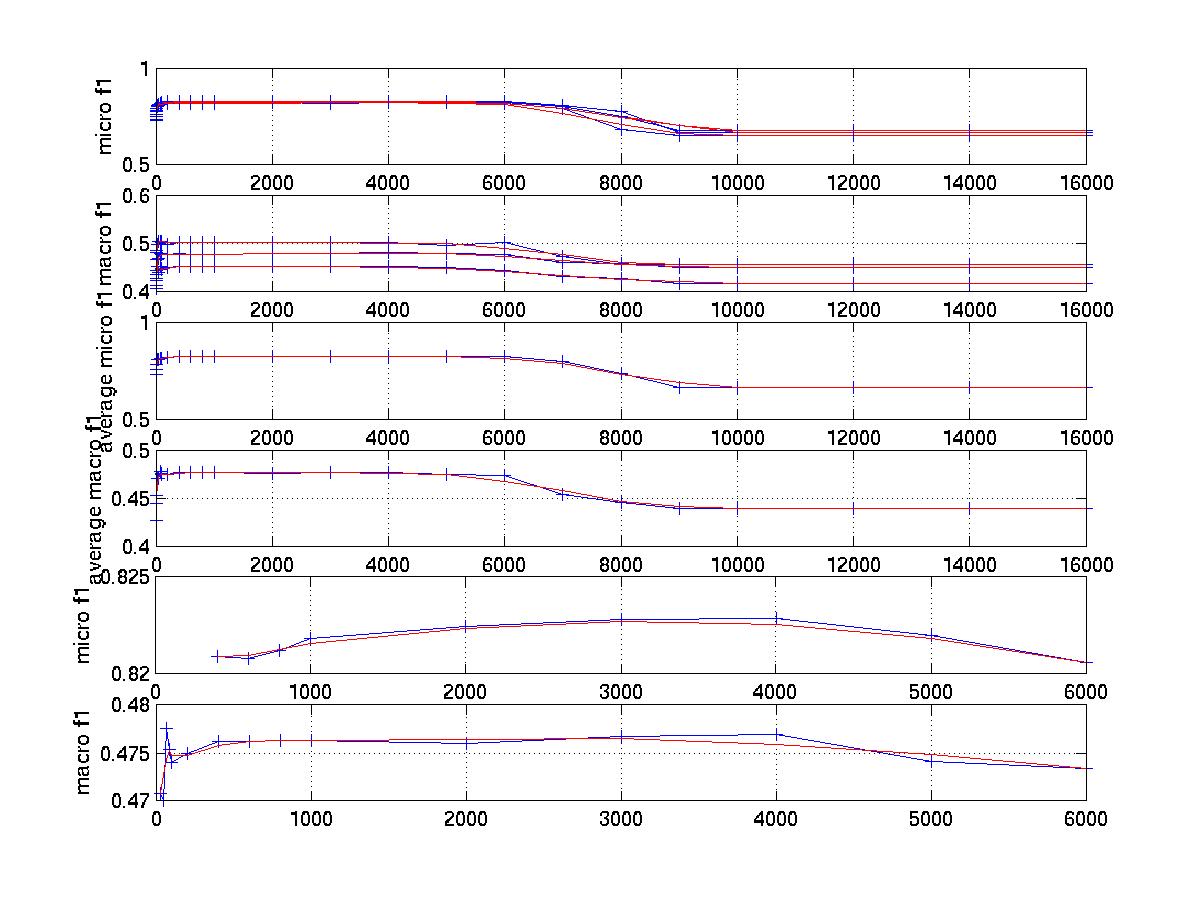
The graph for tuning Pmax
(4000 is the best number for both microf1 and macrof1)
The graph for tuning beta
(-2 is the best number for both microf1 and macrof1)
Observation: We have thought Rocchio will not perform well since it is a simple classifier. In fact, It's performance is good. Besides, It has small training cost.
This is a graph
that compares the scut with s tuned and rcut with r=1. It shows Rocchio's
scut is better than rcut in almost every aspects.(I mean on
R21578. Data set may also have much influence on the performance of
decision strategy.)
1.3 Naive Bayes on R21578
Observation: A obvious point is that
NB has reasonable micro result(though still lower than other classifiers)
but its macro result is
very low. This shows NB is less powerful on rare categories than other
classifiers. So when we deal with a data set which is mainly consist
with rare categories, NB may not be a good choice.
Another issue is that NB has 2 versions:
binary version and multi-class version. From the theory, they should be
both correct. Obviously, Multi-class version need much less training cost.
The problem is that it can only deal with the situation that one document
has only one label and this is not the case in Reuters 21578. So here we
took a simplified implementation. For documents that have two labels, we
duplicate it and assign 1 copy to each of the categories it belongs to.
This simplification may affect the category priors. But the affection will
be very small. In fact, we found the performance of this version is no
less than the binary version. The reason is that we should still assign
di to ci even if P(Ci|di) is 0.2 when P(cj|di) is even less.
1.4 SVM on R21578
Result SVM on R21578 for micro and macro (using scut, fbr=0.3. No features have been deleted)
The graph
tuning feature selection number ( The best value for micro F1 is 15000,
the value for macro is about 13000, it shows using feature selection
for svm is not very helpful)
The graph for tuning fbr score
(0.3 is OK for both microf1 and macrof1)
In SVM's primary sense, it uses 0 as the
threshold for every category. So we have 3 different decision stragety
now: scut with s tuned. scut with s=0 and
rcut with r=1. I tried these 3 decisions from the comparison, we can
see when considering micro result, tuned scut has better recall while rcut
r=1 and scut s=0 have better precision. These 3 strategies have comparable
f1 and f0.5. However when considering macro result, tuned scut is obviously
better in all the measures except precision. It's clear that tuned scut
threshold can improve macro result greatly.
1.5 Some conclusions and comments:
Here is a table for the
4 classifiers on Reuters 21578.(using 5 fold cross validation and the best
tuned parameters)
| Micro avg. F1 | Macro avg. F1 | |
| kNN | 0.8557 | 0.5975 |
| Rocchio | 0.8474 | 0.5914 |
| NB | 0.8009 | 0.4737 |
| SVM | 0.885787 | 0.595677 |
We can see that NB has worse performance. The other three classifiers have close result on macro f1. However SVM has a little better result on micro f1.
Since the decision strategies depend on specific classifiers and data set, it's hard to get a general conclusion. But From the experiments above, we can say(on R21578) .Scut(s tuned) has always has higher recall than rcut(r=1) while rcut tends to have higher precision. They have comparable performance on micro avg. f1 and f0.5. But when considering macro avg. performance, Scut tends to have much better f1 and f0.5. To SVM, we can also use scut s=0 since it's the original idea of SVM,but its performance is no better than scut with s tuned.
In parameter tuning, I found Rocchio ,KNN and NB 's best feature number is 1000-2000. SVM does not depend on feature selection so much, just as Joachims has observed. fbr score is another parameters shared by the classifiers. Generally saying, I found 0.6 is a good valure for micro f1 and 0-0.1 is best for macro f1. The curve tuned for macro avg. results often have larger variance than micro avg. result.
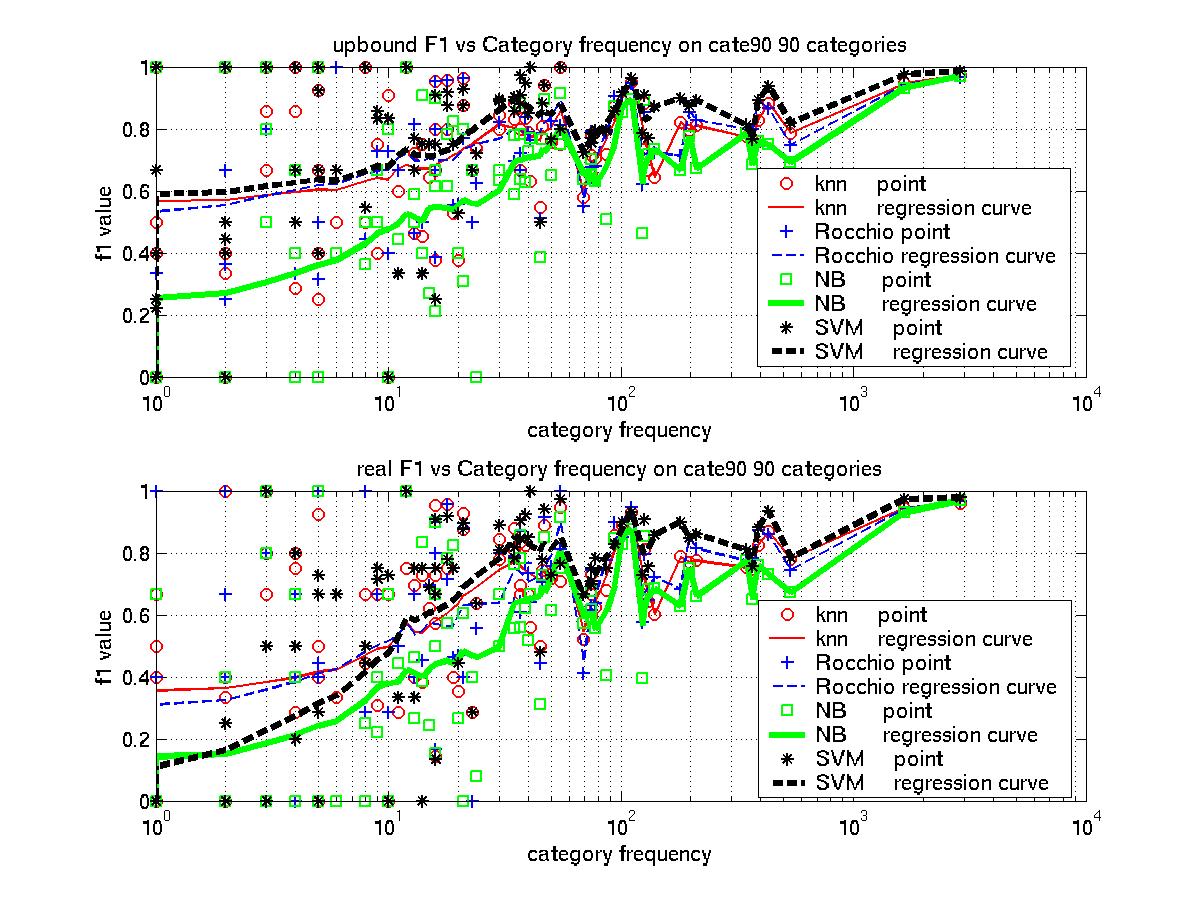
This is a graph
reflecting the upbound and real f1_catfre performance.
with regression window size=20.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}