NeuLab Presentations at NIPS 2017
NeuLab members have two papers and an invited talk at the 2017 version of NIPS, the premier conference in machine learning! Come check them out if you’re in Long Beach!
Main Conference
On-the-fly Operation Batching in Dynamic Computation Graphs
- Authors: Graham Neubig, Yoav Goldberg, Chris Dyer.
- Time: Tue Dec 5th 06:30 – 10:30 PM @ Pacific Ballroom #126.

Dynamic neural network toolkits such as PyTorch, DyNet, and Chainer offer more flexibility for implementing models that cope with data of varying dimensions and structure, relative to toolkits that operate on statically declared computations (e.g., TensorFlow, CNTK, and Theano). However, existing toolkits - both static and dynamic - require that the developer organize the computations into the batches necessary for exploiting high-performance algorithms and hardware. This batching task is generally difficult, but it becomes a major hurdle as architectures become complex. In this paper, we present an algorithm, and its implementation in the DyNet toolkit, for automatically batching operations. Developers simply write minibatch computations as aggregations of single instance computations, and the batching algorithm seamlessly executes them, on the fly, using computationally efficient batched operations. On a variety of tasks, we obtain throughput similar to that obtained with manual batches, as well as comparable speedups over single-instance learning on architectures that are impractical to batch manually. You can also read a practical tutorial.
Graham will also be giving an invited talk about the work in the How To Code a Paper workshop (Saturday 2:00PM).
Controllable Invariance through Adversarial Feature Learning
- Authors: Qizhe Xie, Zihang Dai, Yulun Du, Eduard Hovy, Graham Neubig.
- Time: Wed Dec 6th 06:30 – 10:30 PM @ Pacific Ballroom #121.
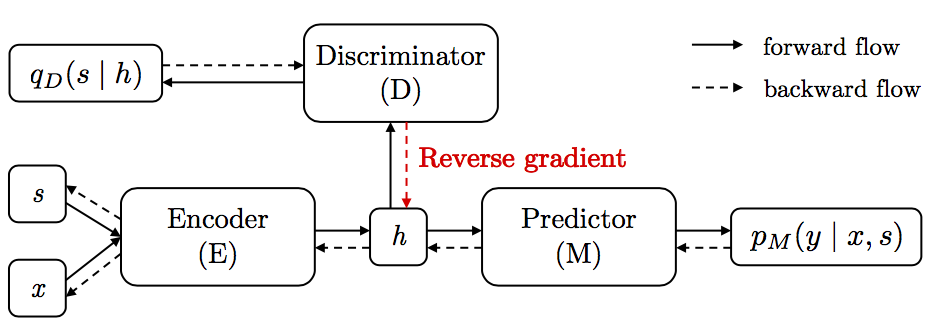
Learning meaningful representations that maintain the content necessary for a particular task while filtering away detrimental variations is a problem of great interest in machine learning. In this paper, we tackle the problem of learning representations invariant to a specific factor or trait of data. The representation learning process is formulated as an adversarial minimax game. We analyze the optimal equilibrium of such a game and find that it amounts to maximizing the uncertainty of inferring the detrimental factor given the representation while maximizing the certainty of making task-specific predictions. On three benchmark tasks, namely fair and bias-free classification, language-independent generation, and lighting-independent image classification, we show that the proposed framework induces an invariant representation, and leads to better generalization evidenced by the improved performance.