FITG experiments: four scanners with
occlusion and clutter
Progress this year:
- Multi-scanner support, allowing 360 degree coverage.
- Detection of occlusion so that occluded tracks are given a chance
to reappear before we kill them off, and so that we know if a
track disappeared due to occlusion.
- Model-based segmentation greatly reduces the tendency for objects
to merge when they pass near each other. The existing
tracks are used as the model for a model-based clustering algorithm
(k-means.)
Problem areas:
- model-based segmentation is somewhat overzealous in splitting
tracks, causing the number of tracks to multiply, and larger objects
such as vehicles to be tracked as multiple tracks.
- Even fairly open brushy vegetation or tall grass can prevent
tracking through that area. Model-based segmentation improves
this, but it is still a weak point. Brushy
vegetation and grass also tends to create false positive motion
detections.
- multi-scanner integration is not entirely smooth. Sometimes
we don't recognize that something seen in two scanners is in fact the
same object, in which case we report two tracks during the overlap,
then the old track dies when we pass out of the old scanner FOV.
- Displayed history paths are not very smooth, and the response to
rapid turning is sluggish. This could likely be improved by a
different batch estimation approach I'm considering.
Inherent limitations of the approach:
- It looks silly losing a person because of low vegetation
which is in the scan plane, but where the person is visually seen above
the vegetation. This is a consequence of the 2D approach.
- If someone crawls below the scan plane, they are not seen.
- Stationary people can't be detected by looking for motion.
It
would be difficult to classify standing people based on 2d shape alone,
and in any case, we don't currently try.
- Pitch and roll of the robot (or non-flat ground) limits useful
range because the scan plane hits the ground. This could be
improved by a multi-plane but still not full 3D scanner (like Ibeo)
(many of these problems could helped by using a real 3d scanner like
the XVU laser in some way. We have a broken proof of this in the
Jay-integration of the XUV laser to the 2D scanner framework.
More generally, segmenation could be done in 3D. There would
likely be CPU speed issues due to the large amount of data to be
processed.)
Configuration:
Testing was done on XUV2 using 4 SICKs, one on front, back and both
sides. As the scanner FOV is 180 degrees and the orientations are
at 90 degree increments, much of the proximity is visible to two
scanners, with only rectangular areas extending from the front, back
and sides that are only seen by one scanner.
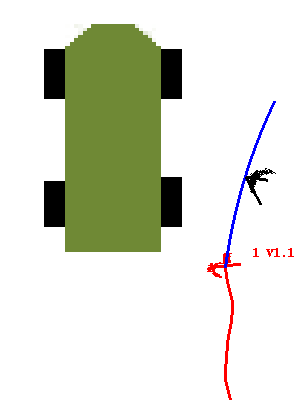
Simple example image:
This image shows the driver walking alongside the robot, passing near a
tree. 1 is the track ID (in this case), and V1.1 tells us the
speed is 1.1 meters/sec. The blue arc is the two-second
projection of the current motion, and the red trail is the previous
path (up to 20 seconds worth.) The front of the XUV is the pointy
end, though the XUV doesn't actually have a point in the front.
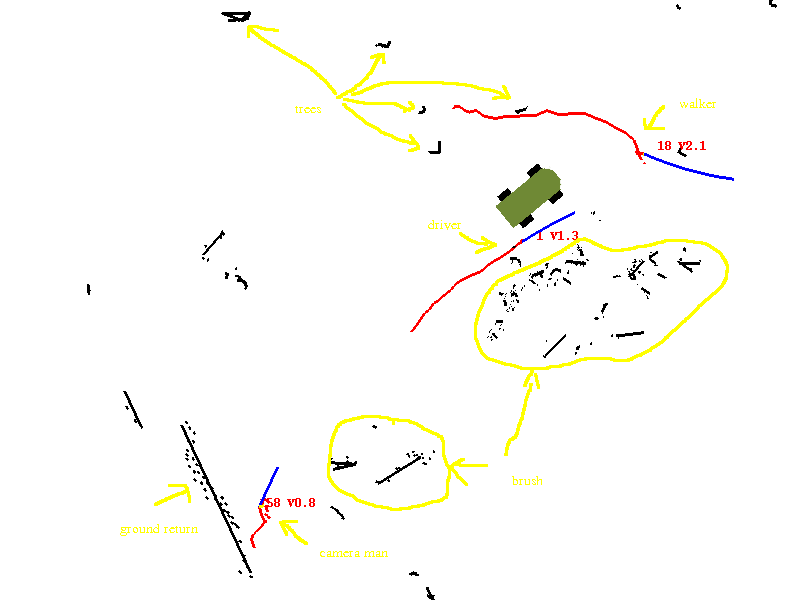
Complex situation:
Here's a more complex situation with three walkers, trees, brush, and
ground returns:
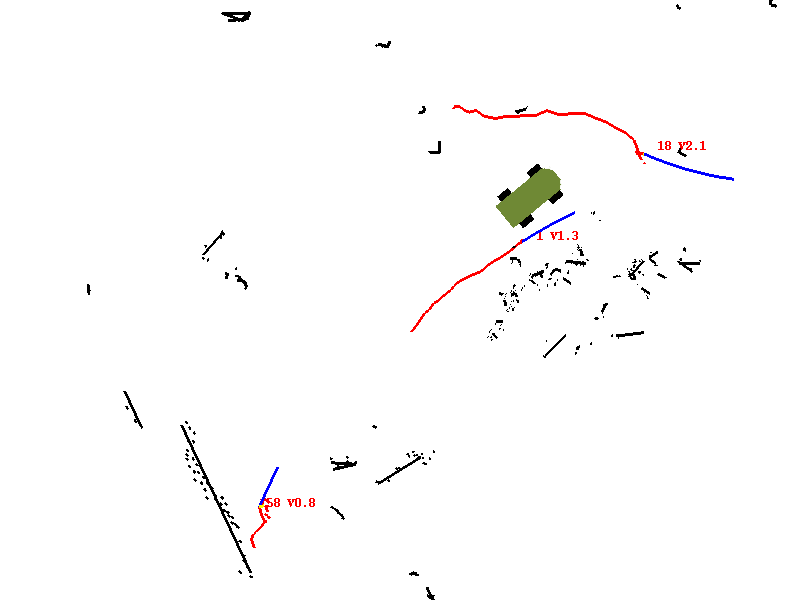
un-annotated version:
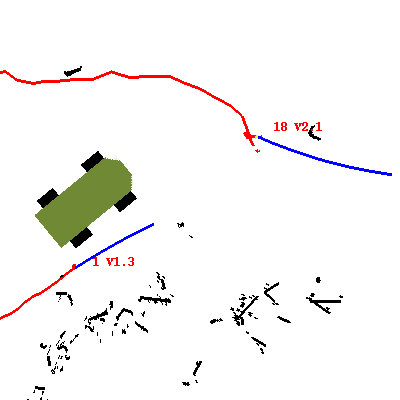
Smaller 400x400 version of this picture zooomed in around the robot,
showing only two walkers.
Occlusion:
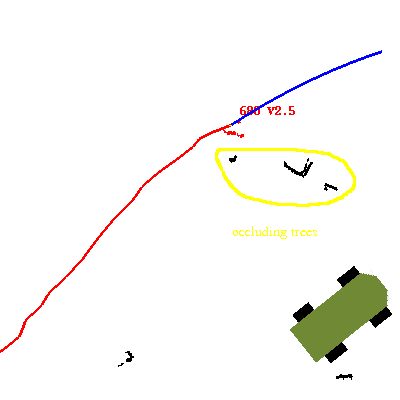
Un-annotated version:

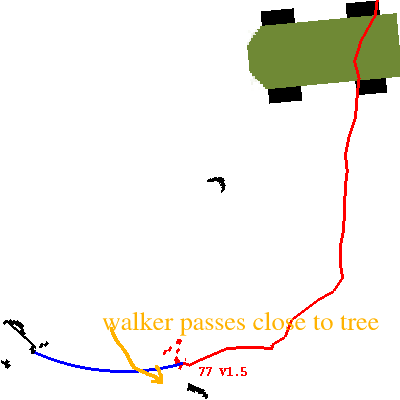
Clutter:
This shows a close approach of the walker to the front of a tree.
This is not a maximally close approach, but the best one I found in
this particular dataset.
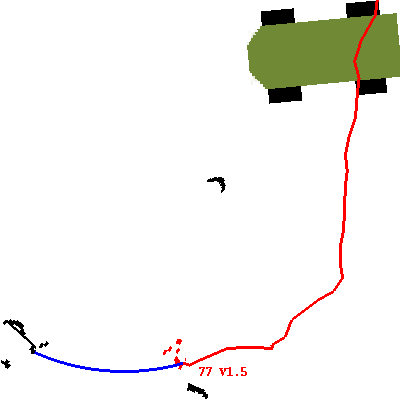
un-annotated:
Still pictures
Videos:
- 20 sec clip of three walkers in
trees, showing ground returns. The
same sequence as raw input data.
- 12 sec clip of two walkers with
an occlusion and lots of busy clutter.
- 26 second camera video showing experiment in progress.
mpeg4 .mov
{kind=link}
{kind=link}
{kind=link}