In what follows, three different techniques are presented and evaluated. The shortest path graph search algorithm is described, along with experimental results, in Section 2. The N-best list generation problem and a new segmented N-best list algorithm are presented in Section 3. Finally, a temporal smoothing technique that overcomes noise by interpolating HMM state scores from neighboring frames is described in Section 4.
The CMU evaluation decoder ([1]) is configured as follows. An initial Viterbi beam search produces a single recognition hypothesis as well as a word lattice that includes word segmentations and acoustic scores. The shortest path graph search produces another single, globally optimal hypothesis (using a trigram grammar) from the word lattice. Finally, N-best lists are generated from the word lattice.
In broadcast speech, the presence of background or channel noise, spontaneous speaking styles, the unconstrained duration of utterances, all tend to aggravate N-best list generation. There are a vary large number of closely competing hypotheses. Therefore, the N-best list may not actually be the best N hypotheses. The shortest path graph search enables us to find the globally optimum word sequence in the word lattice. This hypothesis is also injected into the N-best list.
The final recognition results after rescoring the N-best list are presented in [1]. In this section we evaluate the shortest path search algorithm. It is interesting since it is compact and easy to implement, computationally efficient, and produces results fairly close to N-best rescoring, especially on clean speech. (It has previously been used in the CMU Sphinx-II real-time decoder as a second, rescoring step.)
The cost associated with an edge from a node ![]() to
to ![]() is formed
from two components: an acoustic score or log-likelihood and a language model
log-probability. The former is the acoustic score for
is formed
from two components: an acoustic score or log-likelihood and a language model
log-probability. The former is the acoustic score for ![]() from time
from time ![]() to
to ![]() , with
, with ![]() being the phonetic right context. For the language model
log-probability, let us first consider the case of a simple bigram grammar. The
log-probability is simply
being the phonetic right context. For the language model
log-probability, let us first consider the case of a simple bigram grammar. The
log-probability is simply ![]() . The total edge cost is the weighted
sum of the two. It is independent of other edges in the DAG. (Usually, the language
model log-probability is weighted by a language weight whose optimum value
is determined empirically.)
. The total edge cost is the weighted
sum of the two. It is independent of other edges in the DAG. (Usually, the language
model log-probability is weighted by a language weight whose optimum value
is determined empirically.)
The DAG has distinguished start and end nodes corresponding to the sentence initial and sentence final silence words, respectively. We compute the best (least cost) path through the DAG from the start node to the end node using any of the standard shortest-path graph algorithms. This gives the single best recognition hypothesis for the utterance, given the word lattice.
Longer distance language models can be handled, in principle, by replicating nodes and additional edges as necessary. This is still practical with trigram grammars, but with 4-gram or higher-order grammars the growth in the DAG size can become unmanageable. (With a trigram model, in fact, it is not actually necessary to physically expand the DAG. One can reformulate the problem in terms of an edge cost given the predecessor edge, and applying language model probabilities dynamically.)
The best path search has a number of advantages:
The practical applicability of this algorithm is occasionally limited, however, by the size of the DAG. Noisy speech can result in very large DAGs. A second factor is the presence of noise word models (such as silence and filled pauses) in the Sphinx-3 system. Noise words are inserted in a manner transparent to the n-gram language model. In creating the DAG, additional links must be created to bypass noise word nodes, increasing the size of the DAG significantly. Our implementation aborts a DAG search if pre-specified computational or memory limits are exceeded.
In phase-2, the adapted acoustic models were used for decoding. In addition, the context-dependent (CD) state output probabilities were interpolated with corresponding context-independent (CI) ones to produce smoother models ([4]). Once again, a complete Viterbi beam search was followed by DAG search. An N-best rescoring process was the final step; the best path search results were added to the N-best lists before the rescoring. (Also, the DAG search and N-best rescoring steps used different trigram language models and weights, which were optimized independently [2].)
We present the word error rates (WER) of each step in each phase of the evaluation
run. In particular, we focus on the performance of the best path search relative to
the other steps. Tables 1 and 2
show the word error rates of individual search steps in the partitioned and
unpartitioned evaluations, respectively.
| Tot | F0 | F1 | F2 | F3 | F4 | F5 | FX | |
|---|---|---|---|---|---|---|---|---|
| Viterbi | 38.8 | 28.8 | 33.8 | 44.9 | 45.1 | 45.6 | 45.2 | 64.6 |
| Best-Path | 37.3 | 27.2 | 32.4 | 43.2 | 43.3 | 45.7 | 45.8 | 61.8 |
| Tot | F0 | F1 | F2 | F3 | F4 | F5 | FX | |
|---|---|---|---|---|---|---|---|---|
| Viterbi | 36.3 | 27.2 | 33.2 | 40.4 | 37.7 | 44.1 | 37.1 | 58.5 |
| Best-Path | 35.5 | 26.1 | 32.3 | 39.7 | 37.3 | 43.9 | 38.1 | 57.8 |
| N-best | 34.9 | 25.8 | 32.1 | 38.6 | 36.6 | 43.7 | 36.5 | 55.8 |
| Tot | F0 | F1 | F2 | F3 | F4 | F5 | FX | |
|---|---|---|---|---|---|---|---|---|
| Viterbi | 39.1 | 27.2 | 34.4 | 45.8 | 50.0 | 45.6 | 40.8 | 66.7 |
| Best-Path | 37.8 | 26.0 | 33.5 | 44.7 | 48.4 | 45.0 | 40.8 | 62.9 |
| Tot | F0 | F1 | F2 | F3 | F4 | F5 | FX | |
|---|---|---|---|---|---|---|---|---|
| Viterbi | 37.3 | 25.7 | 34.0 | 42.6 | 49.5 | 43.0 | 37.5 | 60.9 |
| Best-Path | 36.5 | 24.8 | 33.7 | 39.8 | 48.8 | 42.5 | 38.8 | 60.3 |
| N-best | 35.9 | 24.7 | 33.1 | 39.1 | 48.4 | 42.1 | 35.5 | 58.3 |
Overall, we see an improvement in WER as a result of the best path search. However, the improvement varies with the test condition. It is most prominent in the clean, or F0 condition, where it comes closest to N-best rescoring. The performance improvement is more variable in the noisier conditions.
We now look at the execution speed of the best path DAG search algorithm.
Figure 1 shows the distribution of the
normalized execution time (CPU time/utterance duration) for each utterance.
It is a combined graph for both phases of both the partitioned and unpartitioned
evaluations. (The experiments were run on high end DEC Alpha and Pentium Pro
workstations.)
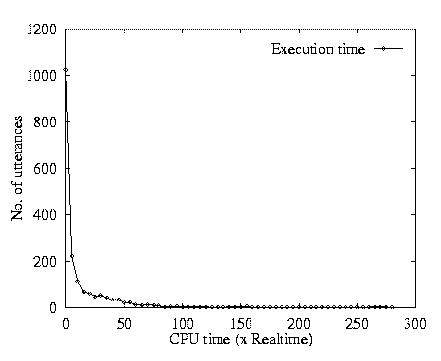
Most utterances are processed at or close to real time. The utterances with very long execution times are typically noisy, or badly articulated speech. The word lattice is very large in these cases to begin with.
In all cases, the shorter the length of the segments, the better the quality of the N-best lists. However, segment breaks also cause breaks in linguistic context, and occasionally within a word. The loss of relevant context information can introduce additional errors when N-best lists for each segment are rescored independently. This problem becomes more acute as the average segment size shrinks. The obvious solution is to rescore N-best lists in the context of neighboring ones. But because of time and resource constraints we were not able to experiment with such possibilities before the evaluation deadline.
Ultimately, because of time constraints, we settled on the front-end segmentation as the simplest scheme. A front-end segmenter is more prone to errors, compared to HMM-based models that can detect silences very accurately. To minimize errors introduced by the segmenter and by linguistic context breaks, we settled on a relatively long average segment duration of about 30 sec.
Though it was not used in the evaluations, we did implement the segmented N-best list generation algorithm, which has some similarities to the IBM envelope search ([11]). It can produce compact, low error N-best lists with efficiency and is described below.
Like all N-best algorithms, this one works by maintaining a number of partial paths and repeatedly expanding the best one by one word. In this case, several lists of partial hypotheses are maintained, one list for each possible end time in the DAG. Each list is sorted in descending order of the partial path score. The lists are initialized with the utterance initial silence and all words that can succeed it (as determined by the DAG).
The algorithm proceeds in a time-synchronous manner, repeatedly expanding the best partial path in the earliest end-time list that is non-empty. However, whenever the algorithm moves in time to a new non-empty list, it first checks if that is also the last non-empty list. If so, it marks an articulation point, and hence a segment boundary. That is, all complete paths must pass through one of the partial paths ending in this list. A segment N-best list is generated at this point and the list compacted to include only the unique grammar states. Since all future extension to partial paths must proceed from one of these, there is no need to maintain duplicate grammar states. The complete algorithm follows:
/* plist[t] = partial path list with end time=t */
for (t = 1 to T) { /* T is utterance length */
/* Look for articulation point at t */
if (plist[t+1]..plist[T] are all empty) {
output plist[t]; /* Nbest list for segment */
compact plist[t]; /* Retain only unique grammar
states; e.g. last two words with trigram LM */
/* Start of new segment */
}
/* Expand paths in plist[t]; usual N-best step */
while (plist[t] not empty) {
p = best partial path in plist[t];
pop p off plist[t];
n = DAG node corresponding to final word in p;
for (each successor node n' to n in DAG) {
for (each end time t' for n') {
p' = new partial path by appending n' to p;
compute path score for p'; /* add acoustic
and LM scores for n' */
insert p' in plist[t'];
}
}
}
}
A pruning beamwidth is employed to consider only the more promising paths.
The beam is applied to each N-best list independently.
The significant feature in the above algorithm is the compaction step after a segment N-best list is output at an articulation point. It prevents the total number of partial hypotheses from growing exponentially with the length of the utterance. The resulting efficiency allows a greater number of hypotheses to be explored in each segment. Yet, by treating each segment independently, the overall size of the list is kept compact.
This algorithm has been evaluated on the 1994 Hub1 evaluation test set using the standard 20K vocabulary. The lattice error rate on this set is 5.5%. The straightforward N-best list (unsegmented), with a list size of 500, has about 8.4% error rate. This corresponds to an oracle somehow chosing the best hypothesis from each N-best. The segmented N-best algorithm presented here has an error rate of 7.3%, a relative improvement of about 13%. At the same time, the segmented N-best files are about an order of magnitude smaller than the unsegmented ones.
Two obvious ways to improve the recognition were the following:
But there is also a third alternative. If, in fact, the input speech is noisy, perhaps smoothing the input data instead of the models can improve performance. The basic idea is to smooth HMM state scores in one frame by interpolating them with corresponding scores from a neighboring frame:
![]()
where, s is any HMM state, ![]() is its unsmoothed state score at time t,
is its unsmoothed state score at time t,
![]() is the corresponding smoothed score, and
is the corresponding smoothed score, and ![]() is an empirically
determined constant (
is an empirically
determined constant ( ![]() ). In a sense, this sends the speech
through a low-pass filter, removing noise from it. Interestingly, we found that
such smoothing provides some improvement in recognition accuracy. Moreover, the
search speed is affected much less than in the alternatives mentioned earlier.
). In a sense, this sends the speech
through a low-pass filter, removing noise from it. Interestingly, we found that
such smoothing provides some improvement in recognition accuracy. Moreover, the
search speed is affected much less than in the alternatives mentioned earlier.
| F0 | F0 | F1 | F1 | |
|---|---|---|---|---|
| WER | HMMs/Frame | WER | HMMs/Frame | |
| BASE | 18.8 | 61K | 36.2 | 81K |
| WIDE | 18.6 | 106K | 36.2 | 143K |
| CD-CI | 17.6 | 92K | 36.5 | 137K |
| TIME | 18.2 | 65K | 36.1 | 87K |
On F0, simply widening the beamwidth is utterly useless. There is about a 75% increase in search complexity for no significant improvement in recognition accuracy. The surprising result is that temporal smoothing does much better, (though not as well as CD-CI smoothing) with less than 10% increase in search complexity. The WER on the F1 condition is unaffected by any of the techniques.
We note that we did not employ this heuristic in the evaluations since we did not have sufficient time to evaluate its utility or robustness.
I would like to thank Paul Placeway, Roni Rosenfeld, Eric Thayer, and other members of the Sphinx group for their comments on the contents of this paper.