Today we will learn how to train an acoustic model (AM). Starting from the the two Gaussian we estimated for speech and silence during homework3 you initialized in homework4 a context independent AM and wrote a start_up.tcl script that build a HMM-object and loads all the required description and parameter files. We will use this results today to seed our training.
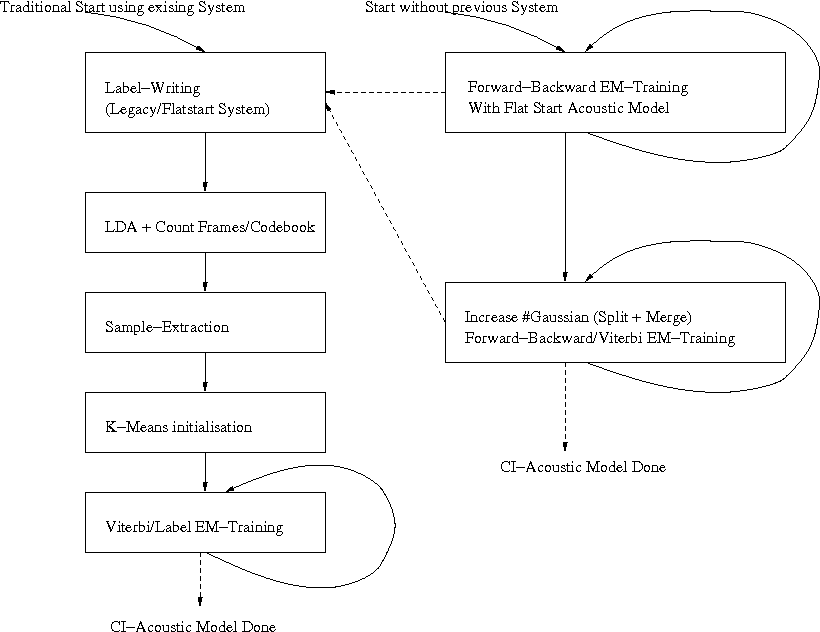
There are many ways to train a larger acoustic model starting from that point. The following picture shows two of the possible approaches.
To train the context independent (CI) acoustic model (AM) used building a decision tree we will follow the right side of the training schemes. Starting from a initial flat-start AM. Improve the state assigments using Forward-Backward EM Training (Baum-Welch-Training) and then increase the number of parameters of the model, because during the next step we will need the mixture weights of the GMMs to compute a similarity of different contexts.

# from your your homework4
source start-up.tcl
# open database (homework 2)
set uttDB utterance
DBase db
db open ${uttDB}.dat ${uttDB}.idx -mode "r"
Path path
# the path-object is a container object that allows
# to store Forward-Backward trellis or a Viterbi path
# The method fwdBwd performs a fwdBwd for a given HMM-object
# The method viterbi computes a Viterbi path for a given HMM-object
# let us see how good our seed model is and compute a Viterbi path for utterance spk030_utt7
set uttKey spk030_utt7
set uttInfo [db get $uttKey]
makeArray uttArray $uttInfo
# makeArray is a janus-function, not TCL!
# check content with parray
hmm make "$ $uttArray(TEXT) $"
# we need the features/observations
fs eval $uttInfo
# now find the most likely state sequence
set score [path viterbi hmm]
path.
# we have 1241 elements of the type PathItemList
path.itemList(300).
# Question: Why store all 1241 PathItemList objects only one item?
# item is a list of PathItem-objects
path.itemList(300).item(0) configure
# {-stateX 54} index of state in HMM
# {-senoneX 54} index of Senone in SenoneSet: sns.item(54) configure
# {-phoneX 15} index of phone in phoneGraph
# {-wordX 5} index of word in wordGraph
# {-alpha 0.000000} used in forward-backward
# {-beta 0.000000} used in forward-backward
# {-gamma 1.000000} occupation probability from forward-backward
# {-lscore 0.000000} local acoustic score
# fills the lscore entry and computes the accumulated scores given the path
set score [path lscore hmm]
# 1.212375e+05
set lscore [path.itemList(300).item(0) configure -lscore]
# 107.675224
# easier to access formats provided by the path-object
path words hmm
# this is a list of words with start FRAME and end FRAME
# {$ 0 46} {wei4le5 47 57} {jia1qiang2 58 71} {dian4ying3 72 82} {hang2ye4 83 93} {guan3li3 94 344} {fa1zhan3 345 358} {he2 359 365} {fan2rong2 366 379} {dian4ying3 380 390} {shi4ye4 391 401} {man3zu2 402 415} {ren2min2 416 429} {qun2zhong4 430 443} {wen2hua4 444 454} {sheng1huo2 455 468} {xu1yao4 469 479} {cu4jin4 480 493} {she4hui4zhu3yi4 494 518} {wu4zhi2wen2ming2 519 540} {he2 541 547} {jing1shen2 548 561} {wen2ming2 562 572} {jian4she4 573 586} {guo2wu4yuan4 587 601} {jue2ding4 602 615} {zhi4ding4 616 629} {dian4ying3 630 640} {guan3li3 641 654} {tiao2li4 655 1239} {$ 1240 1240}
path phones hmm
# Same information for the phonemes (demi-syllables)
# {SIL 0 46} {uei 47 50} {l 51 53} {e 54 57} {j 58 60} {ia 61 64} {q 65 67} {iang 68 71} {d 72 74} {ian 75 78} {ing 79 82} {h 83 85} {ang 86 89} {ie 90 93} {g 94 96} {uan 97 337} {l 338 340} {i 341 344} {f 345 347} {a 348 351} {zh 352 354} {an 355 358} {h 359 361} {e 362 365} {f 366 368} {an 369 372} {r 373 375} {ong 376 379} {d 380 382} {ian 383 386} {ing 387 390} {sh 391 393} {-i 394 397} {ie 398 401} {m 402 404} {an 405 408} {z 409 411} {u 412 415} {r 416 418} {en 419 422} {m 423 425} {in 426 429} {q 430 432} {vn 433 436} {zh 437 439} {ong 440 443} {uen 444 447} {h 448 450} {ua 451 454} {sh 455 457} {eng 458 461} {h 462 464} {uo 465 468} {x 469 471} {v 472 475} {iao 476 479} {c 480 482} {u 483 486} {j 487 489} {in 490 493} {sh 494 496} {e 497 500} {h 501 503} {uei 504 507} {zh 508 510} {u 511 514} {i 515 518} {u 519 522} {zh 523 525} {-i 526 529} {uen 530 533} {m 534 536} {ing 537 540} {h 541 543} {e 544 547} {j 548 550} {ing 551 554} {sh 555 557} {en 558 561} {uen 562 565} {m 566 568} {ing 569 572} {j 573 575} {ian 576 579} {sh 580 582} {e 583 586} {g 587 589} {uo 590 593} {u 594 597} {van 598 601} {j 602 604} {ve 605 608} {d 609 611} {ing 612 615} {zh 616 618} {-i 619 622} {d 623 625} {ing 626 629} {d 630 632} {ian 633 636} {ing 637 640} {g 641 643} {uan 644 647} {l 648 650} {i 651 654} {t 655 657} {iao 658 661} {l 662 664} {i 665 1239} {SIL 1240 1240}
# nice output, with additional state information (last element)
path labels hmm -what words
path labels hmm -what phones
path labels hmm -what senones
# stores in FMatrix for each frame the probability
# of being in a certain word. Accumulates all gamma values
# from states that belong to a word with the corresponding
# index in wordGraph
FMatrix gamma
path wordMatrix gamma
gamma configure
# {-m 1241} {-n 31} {-count 0.000000}
# same for phonemes
path phoneMatrix gamma
gamma configure
# {-m 1241} {-n 110} {-count 0.000000}
# same for senones
path senoneMatrix gamma
gamma configure
# {-m 1241} {-n 150} {-count 0.000000}
# that is the bottom
path stateMatrix gamma
gamma configure
# {-m 1241} {-n 387} {-count 0.000000}
# a little TCL
canvas .c -width 1000 -heigh 500
.c configure -width 1000 -heigh 500
pack .c
gamma display .c -width 1000 -height 500 -grey 1
# This displays the Viterbi path in the initial janus window
# as you can see from the picture it looks rather steep
# a much more elaborated tool to visualize a Viterbi is provided by
# displayLabels
catch {displayLabels path hmm}
# NB: it seems that the tool is a little bit broken
# the word guan3li3 and tiao2 are pretty long
# OK these does not look so good, but we did not any training so far
#
# let us take a look at the features to see what happen there
set SID "" ;# the procedure assumes that the SiystemID SID variable is set
fs show lMEL
# let add the information from the Viterbi path to the features
# 1) in the pull-down menue, select the check-box: show labels
# 2) same menu choose: insert labels
# 3) same menu choose: labels from path
#
# step 2) created an update button at the bottom of the window
# use this to display the labels if not drawn automatically
# take a look at the Viterbi alignment
# from frame 630 to 655 we have silence in the middle of
# the utterance which is aligned to speech.
#
# Move to the end of the utterance. We see that the speech
# last until the end of the recording! If you can not see
# it from the lMEL features switch to the ADC feature
# We should use optional silence at the begin/end and between words
# remember exercise4?
hmm make $uttArray(TEXT) -opt $
# we compute a new Viterbi path
path viterbi hmm
# in the feature window read the updated labels (step 3) above
# and click the update button
# Silence is no longer assumed at the end of the utterance
# and longer silence is found between words.
# But now, we sometimes find short silence between words
# were maybe speech happen.
# to view the labels with displayLabels we have to close the window first!
catch {displayLabels path hmm}
# The Viterbi path looks a little bit better
# close the displayLables window and keep the feature window open
# Now we will start the EM-training
# the correct EM-training for HMM is the Baum-Welch Algorithm (see paper)
# The proof of convergence uses an alternating update of model parameters:
# means, covariance and transition probabilities
# We will not train the transition probabilities, and update
# means and covariance at the same time. Therefore a convergence is not proved
# but it works faster!
# Another method to speedup training is to use the Viterbi approximation,
# which means use a Viterbi path instead of the forward-backward to compute
# the states occupation probability gamma.
#
# Because our seed model is poor we will start with forward-backward
catch {path fwdBwd hmm}
# ERROR viterbi.c(0742) Cannot find a forward path through HMM hmm in 47.
# it does not work!!
# because the model is poor the scores of the models are very high (-> probability is close to 0.0)
# to smooth the probabilities we scale them by 1.0/26. This can be done in the SenoneSet
sns configure -scoreScale [expr 1.0/26.0]
# During the lab some discovered that the fwdBwd
# did not work even with the step above. The reason was a
# different version of janus. Someone who wrote code for janus
# changed the default scoring routine used in janus.
#
# My message to people who develope new code for Janus:
# In my opinion changing default behavior is a bad idea
# unless there is a really good reason.
#
# The solution: make sure to use always the basic score routine for training!
# sns setScoreFct -help
# Options of 'setScoreFct' are:
# one of (base, opt, opt_thread, opt_semCont, opt_str, compress, old_base, old_opt) (string:"base")
sns setScoreFct base
set score [path fwdBwd hmm]
# it works and the forward score is 4.744641e+03
# Task: Plot for some utterances the gamma-Matrix (word/phone/state)
# and compare it with more iterations and Viterbi alignment
# path wordMatrix gamma
# gamma configure
# gamma display .c -width 1000 -height 500 -grey 1
# prepare to accumulate sufficient statistic
cbs createAccus
dss createAccus
# the senoneset propagates the accumulation of the statistics down to the models
sns accu path
# Task: Check the accumulators of the SIL-s1 and the ong-s4
# Question: make yourself clear how the statistic is accumulated
# score before update
set score [path viterbi hmm]
# 5.462189e+03
# update the underlying models
sns update
# score after update
set score [path viterbi hmm]
# 5.327602e+03 ; okay score improved (lower -> better)
# let us see if the alignment changed
#
catch {displayLabels path hmm}
# difficult to judge
# Let us update the labels in the feature window
# but first scroll so that you can see the features from frame 880 to 960
# now re-read the labels from path (step 3) and hit the update button
# clearly the alignment changed a lot
# Task: How much does the label change if we replace in the step above the fwdBwd with Viterbi.
# Note you have to reload the initial models or start from the beginning.
# One iteration of training consist of the following steps
#---------------------------------------------------------
# clear the statistic from the previous iteration (we do not train with a momentum)
# 1: for each training utterance
# 2: create hmm
# 3: process the features
# 4: compute forward-backward
# 5: accumulate statistics
# 6: update the models
# Task: Write a TCL-procedure accuOneUttFwdBwd that performs the accumulation for one utterance.
# Task: Write a TCL-procedure accuOneUttViterbi that performs the accumulation for one utterance sith viterbi alignment.
# and one that use this function .
# Question: What diagnostic output can/should be provided?
source ./trainLib.tcl
# now do some more training (we keep spk030_utt7 the last element in list)
set keyList {spk030_utt1 spk030_utt2 spk030_utt3 spk030_utt4 spk030_utt5 spk030_utt6 spk030_utt8 spk030_utt9 spk030_utt10 spk030_utt7}
set iter 0
set maxIter 10
while {$iter < $maxIter} {
incr iter
accuOneIterFwdBwd $keyList $iter
# update the models
sns update
}
# well what score do we get now for spk030_utt7
set score [path viterbi hmm]
# inital seed model : 5.462189e+03
# after first iteration : 5.327602e+03
# +10 iteration fwdBwd : 4.975636e+03
# Look at the labels in the feature window
# Question: How to find a good number if iterations?
set maxIter 20
while {$iter < $maxIter} {
incr iter
accuOneIterFwdBwd $keyList $iter
# update the models
sns update
}
# set score [path viterbi hmm]
# 21 iteration 4.970510e+03
# lets see what happen if we switch to viterbi
set maxIter 40
while {$iter < $maxIter} {
incr iter
accuOneIterViterbi $keyList $iter
# update the models
sns update
}
set score [path viterbi hmm]
# 21 fwdBwd + 20 viterbi : 4.926609e+03
After the the Viterbi paths have a reasonable quality we can start increasing the number of Gaussian. In the next exercise we will build a data driven decision tree that models different phonetic context of the same phone with different GMMs. The whole work so far is a preparation to build this tree. The tree will be build in a top-down way by splitting nodes according to a criteria. Because the criteria we use is based on the mixture weights of a shared GMM (semi continuous HMM), we need more Gaussian than one in our GMM.
There are many possible ways to increase the number of Gaussian, because we don't want to change the pre-processing we will split the Gaussian that got enough data. This is similar to the heuristic merge and split training described by Fukunage in Link/Cite.
There are some technical issues with merge and split methods in janus. First of all, merge only works if the codebooks have an accumulator filled. The other thing is merge creates empty mean vectors, that are removed from the split method, and therefore it is neccesary that split is called after merge.
Question: What clusters should be split and how should they be splited?
set maxGaussians 4 ;# number is only an example!
set splitStep 0.01 ;# default value!
set mergeThresh 10.000000 ;# default value!
foreach cb [cbs] {
# refMax sets the maximal number of allowed Gaussian for that codebook
cbs:${cb} configure -refMax $maxGaussians
# because the cfg object is shared by all Codebook-object in all CodebookSet-objects configuring one would be sufficient!
# so be careful if you want to have different values for different codebooks (but usual here the same value is OK)
cbs:${cb}.cfg configure -splitStep $splitStep
# if a Gaussian has a occupation of less then 2 * $mergeThresh it is not split
cbs:${cb}.cfg configure -mergeThresh $mergeThresh
}
cbs:SIL-s1 configure -refMax [expr 4 * $maxGaussians]
# Question: How does the splitting works if we train a semi-continuous HMM?
set maxIter 60
while {$iter < $maxIter} {
incr iter
accuOneIterFwdBwd $keyList $iter
# update the models
sns update
# split every 4 iterations
if {! ($iter % 4)} {
puts "split gaussians during at iter $iter"
# dss merge
dss split
}
}
set score [path viterbi hmm]
# 4.764493e+03
set maxIter 79
while {$iter < $maxIter} {
incr iter
accuOneIterViterbi $keyList $iter
# update the models
sns update
# split every 4 iterations
if {! ($iter % 4)} {
puts "split gaussians during at iter $iter"
dss merge
dss split
}
}
# let us take another look at the labels in the feature window
set score [path viterbi hmm]
# 4.703383e+03
# What we can se here is that the g demi-sylable models also much silence
# One of the possible reasons is that the model is over trained. Think about reasonable settings for split and merge.
#
#Task: Train an acoustic model on the whole training data and plot some diagnostic output. Try different configurations. (Homework: Details from Stan)
#
Last modified: Wed Jan 11 20:39:52 Eastern Standard Time 2006
Maintainer: tschaaf@cs.cmu.edu.