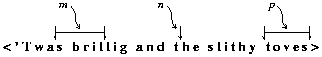
The key feature of the algebra is that each value is not itself a sequence, but is instead a reference to a portion of an underlying sequence called its base; thus the value is an indivisible composite of a reference to the base and the location and extent of a subsequence within that base. In Figure 1, the base is "'Twas brillig and the slithy toves" and variables m, n, and p refer to subsequences. This type of data value is called a subsequence reference, or subseq, and can refer to as much as the entirety of its base or as little as the empty subsequence between two elements. Note that two empty subseqs are not equivalent unless they are at the same positions in the same base.
The many advantages of substring references for programming--especially with multi-media strings--have been discussed elsewhere [Hansen, 1990a]. The strongest advantages are seen in returning values from functions, where the single substring reference value incorporates both the position and length of a substring. A substring isolated by one function can be passed directly as an argument to another function and that function can access not only the substring but also subsequent or prior characters of the source. Consider searching and parsing algorithms. With these, it is often desirable that the outcome of a search indicate the location of the result as a start for further processing, as for example in a loop that scans through the characters of a source string extracting a token at each iteration.
Unfortunately, in non-garbage-collected languages like C it is not possible to implement the subsequence reference algebra as a simple subroutine package without using unbounded memory. It is simple to define a struct containing the position and length so such values can be stored or passed to or from functions. However, if a function creates such a value and returns it, there is no good way to ensure that the storage allocated for the struct is ever deallocated.
The variety of sequence algebras and string facilities in existing programming languages is reviewed in [Hansen, 1990a]. Especially notable are the string processing languages SNOBOL4 [Griswold, 1971] and Icon [Griswold, 1983], neither of which implement subsequence references as a datatype. PostScript [Adobe, 1985] and Common Lisp [Steele, 1984] do implement subsequence references, but the three of the four functions of the subsequence algebra below cannot be expressed in these languages. It must be noted that all four languages offer extensive string processing capabilities beyond the scope of the algebra described here. It is not the intention of this algebra to supplant these capabilities, but rather to suggest a data type for strings on top of which other semantics can be added.
Formal treatments of string values sometimes present as their algebra the free monoid with concatenation. This adequately generates all string values, but cannot express substring references. The computation model in such treatments is often a set of rewriting rules with strings as the data values and the rules as the only mechanism; there are no if's, while's or functions. In contrast, the subsequence algebra is a representation for strings designed to be consistent with other data values in a programming language; the computational engine is the ordinary tools of if-then-else, while-do, and functions.
One string representation common to many programming languages is an array of characters with integers or pointers to indicate position and extent of substrings. From an algebraic standpoint this model is inferior because it requires an additional domain--integers or pointers--as well as the domain of sequences. In practice, the array/integer model of strings suffers from other deficiencies: Characters do not always fit in a single byte, or even two bytes, so array subscription may not access distinct characters; string values are limited in length to predeclared storage sizes; and it is not always intuitive--especially when modifying a program--as to whether an integer i refers to the i'th character or the preceding or following inter-character position. When a substring is to be returned by a function under the array/integer model the return value can easily be a reference to the start of the substring, but the length of the substring must be returned through some side-effect like a global variable or modification of an additional parameter to the function.
The icon language offers an entirely different paradigm for reference to substrings. The question mark operator establishes its left operand as a subject string to be scanned and its right operand is a statement (usually a compound statement) which advances an implicit pointer through the subject string. This is a dynamic notion of substring since it depends on the entire state of the computation to determine the current substring. To store a substring or pass it as a value, the program can either make a copy of its contents or store two references, one to each end of the substring. Neither is a single value referring to the substring within its base.
The subsequence algebra has been implemented three times so far. First in a research language [Hansen, 1987], then as part of the cT system for educational computing [Sherwood & Sherwood, 1988], and most recently in the Ness language [Hansen, 1989; Hansen, 1990b] as part of the Andrew system [Morris, et al., 1986]. (In these past implementations the declarator for subseq values is "marker".) A subset of Ness will be used for programming examples below. In addition to the functions of the algebra, the subset utilizes subseq declarations, assignment, if-then-else, while-do, predicates, compound statements, function definition, call (with call-by-value parameters), and return. Spare as it may be, this subset was sufficient to write a preprocessor from itself into C.
Section 2 defines the fundamental primitives, applications of which
are shown in Section 3 where they are used to define other functions
to access subsequences. Section 4 establishes that the algebra is
sufficient to compute not only all subsequences of a given sequence,
but also all functions. Section 5 shows how the algebra can be extended
to cover modification of strings and section 6 presents a regular expression
parser as an extended example. Rather than axiomatic definitions and
proofs, subseqs are defined syntactically and proofs are done with
symbol manipulation. This proof technique, and the elegance of the
algebra, combine to render most proofs quite straightforward; indeed,
the goal of this paper is not so much to prove results about the algebra,
but rather to demonstrate its potential for simple expression of algorithms.
In practice it is expected that the elements of the alphabet have "small" representations; large objects can be incorporated by storing references to them.
The algebra does not require that sequences be finite; the implemntation of a sequence could include a generator to produce tail elements on demand as they are accessed. This paper does not explore this potential, however, and treats all sequences as finite.
Each value in the algebra is itself a reference to a subsequence of a base sequence, so we call the value a subsequence reference value or subseq. For the formal exposition in this paper, the notation for subseq values must represent both the base sequence and the position within it of the referenced subsequence. We write base sequences in angle brackets like this
< s1 c >
Identifiers within the angle brackets are meta-variables which refer to individual elements (a, b, c, ...) or to sequences of zero or more elements (p, q, r, s1, s2, ...) . Quoted strings represent themselves. In most cases a subseq representation will also contain square brackets:
< s1 [ s2 ] s3 >
where each si is a sequence of zero or more elements. The entire sequence < s1 s2 s3 > is the base. s2 is the referenced portion. If s2 has length zero, the subseq is empty.
It may appear that the definitions below require copying sequences; the intended interpretation--and the implementation of Ness--does not require copying sequences for any of these functions other than concatenation and replace().
Traditional programming constructs are described as follows for subseq values. In the descriptions, the construct is followed by an arrow, =>, and then the resulting value as a subsequence reference representation.
Constants return a subseq for the entire sequence. For character strings this is:
"some text" => < [ "some text" ] >
Concatenation (written with "~")
constructs a new sequence by juxtaposing the referenced portions of
the arguments (that is, the portion inside the square brackets) and
returning a subseq for the entire new sequence.
< s1 [ s2 ] s3 > ~
< s4 [ s5 ] s6 > => < [ s2 s5 ] >
Comparison of subseq values is defined to be sequence comparison of the referenced portions. This operation is well defined only when there is an appropriate ordering relation defined for elements of the sequences, such as lexicographic ordering of characters. For any relational operator relop:
< s1 [ s2 ] s3 > relop < s4 [ s5 ] s6 > => < s2 > relop < s5 >
Assignment of subseq values assigns the subseq value, it does not copy the sequence. After the assignment
if the expression x has the subseq value < s1 [ s2 ] s3 > then a and x will each have that value after the assignment; they are separate values, but both refer to the same underlying base.
Printing a subseq value prints the referenced portion.
print(< s1 [ s2 ] s3 >) => <s2 > is printed
Declarations in the examples will utilize the keyword subseq:
subseq var1, var2, ...
Parameter passing is call by value and passes the entire subseq
value, including the base. Thus if f has a formal parameter m and
is called with f(p) where p is < s1 [ s2 ] s3 > then f can access any
portion of the base of p. All parameters of functions defined in this
paper are subseq values and parameter declarations are omitted.
The algebra of subsequence expressions has the following primitive operations. The effects of these functions on a typical character string are illustrated in Figure 2.
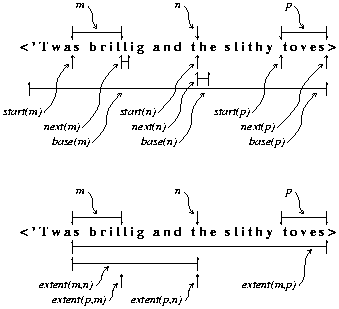
Start(m) returns a subseq both of whose limits are at the beginning of the argument:
start(< s1 [ s2 ] s3 >) => < s1 [] s2 s3 >
Next(m) returns a subseq for the element following the argument. If the argument was at the end of its base, next() returns the end of the base.
next(< s1 [ s2 ] c s3 >) => < s1 s2 [ c ] s3 >
next(< s1 [ s2 ] >) => < s1 s2 [] >
Base(m) returns a subseq for the entire sequence surrounding the argument.
base(< s1 [ s2 ] s3 >) => < [ s1 s2 s3 ] >
With these first three functions, an expression for the first character of the base of subseq m is next(start(base(m))). In Figure 2 this would have as its value a reference to the initial apostrophe in the string.
Extent(m, p) produces a subseq extending from the beginning of its first argument to the end of its second argument. If the second argument ends before the start of the first, the result is an empty subseq at the end of the second argument. Extent() expects that its arguments be on the "same" base, that is, a base generated by a single constant or concatenation. If the bases differ, extent() returns a unique empty constant.
To formally define extent() we abuse the notation slightly by omitting some square brackets; missing right (or left) brackets appear somewhere to the right (or left) of the corresponding left (or right) bracket which does appear.
extent(< s1 [ s2 s3 >, < s1 s2 ] s3 >) => < s1 [ s2 ] s3 >
extent(< s1 s2 [ s3 >, < s1 ] s2 s3 >) => < s1 [] s2 s3 >
extent(< s1 [ s2 ] s3 >, < s4 [ s5 ] s6 >)
=> < [] >, where < s1 s2 s3 > /= < s4 s5 s6 >
As written, the formal definition does not require identical bases for the two arguments, only that the base sequences be equal. There is no way in the algebra to distinguish two subseqs on the same base from two subseqs on different but equal bases. However, implementations of extent() may return the empty sequence unless the two bases are indeed physically one.
Referring again to Figure 2, an expression for " slithy "--with spaces--is
extent(next(next(next(n))), start(p))
because next(n) is "h", next(next(n)) is "e" and next(next(next(n))) is the space before slithy. As an example with more general applicability, an expression to compute all but the first element of a subseq t is extent(next(next(start(t))), t).
The following example utilizes the algebraic operations introduced above. ExpandTabs() copies an input string and produces a modified version with tab characters replaced with enough spaces to move subsequent text to appropriate column positions. The main loop sequentially processes each character of the input, generating the output in variable new. For each cycle, c refers to the current character and m is the remaining unprocessed text. Each time a tab is encountered, its place in the new string is filled with extent(tab, base(eight)), which is the right number of spaces because variable tab is advanced by one character for each non-tab character and replenished with eight spaces when exhausted.
In order for a set of functions to be teachable and memorable, they should be based on an underlying set of functions that are as small as possible. The next section will present a number of additional subsequence functions all of which can be defined in terms of the above four primitives. To show that none of the four is redundant we have:
Theorem 2.1 (Necessity): The four primitive functions--start(), next(), base(), and extent()--are all necessary for computation with the algebra. That is, none can be expressed as a functional composition of the others.
Proof: We wish to demonstrate for each of the primitives, P, that there is no expression E which behaves as defined above for P and yet does not contain P in the expression E. We do this by exhibiting a particular value, v, and argue for each primitive that no such expression E exists that converts this value appropriately, and therefore no expression E exists which implements P for all arguments. The particular value v is
< "ab" [ "cd" ] "ef" >
Note first that
next(v) = < "abcd" [ "e" ] "f" >,
start(v) = < "ab" [] "cdef" >, and
base(v) = < [ "abcdef" ] >.
For extent() no E can exist because the value returned may have to be of any length and the other functions return only subseqs of zero, one, or all the elements of a base.
For base() no E can exist because none of the other functions can otherwise generate a subseq beginning before the left bracket of v.
For next() no E can exist because no other function can create a subseq that ends one character after the end of v.
For start(), note first that base() and next() return values that terminate at or after the end of their argument. Extent() returns a value which ends where its second argument does, but since that argument can only be derived from v, next(), base(), or extent(), there is no way it could be prior to the termination of v.
Since none of the functions can be expressed in terms of the others,
all are necessary. QED
Experiments with various alternative sets of primitive functions have shown none more convenient for programming than the set above. For instance, by symmetry the algebra could be defined with previous() instead of next() or finish() instead of start(); but either would emphasize right-to-left processing instead of the more natural left-to-right processing. Next() could return an empty subseq after the following element, but algorithms often require elements rather than empty subseqs.
There is an algebra which is formally simpler than the one above, requiring three primitive operations instead of four. It utilizes next() and extent() and a third function we can call startofbase():
StartOfBase(m) returns a subseq for the empty sequence at the beginning of the entire sequence surrounding the argument.
startofbase(< s1 [ s2 ] s3 >) => < [] s1 s2 s3 >
Implementation of base(x) with the three primitives first has a loop to find e, the end of the base, and then returns the value extent(startofbase(x), e). Start() is less obvious:
The set of three functions, however, is less convenient for programming
than the four primitives presented earlier.
finish(m) - Returns a subseq for the empty subsequence just after m:
finish(< s1 [ s2 ] s3 >) => < s1 s2 [] s3 >.
Lemma 3.1: An expression for finish(m) is start(next(m)).
Proof: If s3 is non-empty it contains a first element c and a continuation s4:
start(next(< s1 [ s2 ] c s4 >))
= start(< s1 s2 [ c ] s4 >)
= < s1 s2 [] c s4 >
= < s1 s2 [] s3 >
while if s3 is empty we have:
start(next(< s1 [ s2 ] >))
= start(< s1 s2 [] >)
= < s1 s2 [] >
= < s1 s2 [] s3 >
In both cases the expression computes the correct value. QED
Algorithms frequently need single element subsequences analogous to next, but in some other position relative to a given subseq; for example, the first element before the subseq and the first and last elements within the subseq. We begin with the single element subseq which starts at the same place as its argument:
front(m) - Returns a subseq for the first element after start(m), if there is one, otherwise m must be empty at the end of its base and this value is returned:
front(< s1 [ c s2 ] s3 > => < s1 [ c ] s2 s3 >
front(< s1 [] c s3 >) => < s1 [ c ] s3 >
front(< s1 [] >) => < s1 [] >
Lemma 3.2: An expression for front(m) is next(start(m)). (Proof omitted.)
Front() returns a single element regardless of whether its argument is the empty string, but sometimes it is preferable to have a function first() which is empty when its argument is. To define first() it is easiest to begin with rest(), a function to compute all but the first element. The implementation of this function exploits a detail of the definition of extent().
rest(m) - Returns a subseq for all elements of m other than the first; but if m is empty, so is rest(m):
(i) rest(< s1 [ c s2 ] s3 >) => < s1 c [ s2 ] s3 >
(ii) rest(< s1 [] s3 >) => < s1 [] s3 >
Lemma 3.3: An expression for rest(m) is extent(next(next(start(m))), m).
Proof: The proof of (i) has three cases depending on the lengths of s2 and s3. When s2 has at least one element we write s2 as < c2 s4 > and the proof proceeds thus:
rest(< s1 [ c c2 s4 ] s3 >)
= extent(next(next(start(< s1 [ c c2 s4 ] s3 >))),
< s1 [ c c2 s4 ] s3 >)
= extent(next(next(< s1 [] c c2 s4 s3 >)), < s1 [ c c2 s4 ] s3 >)
= extent(next(< s1 [ c ] c2 s4 s3 >), < s1 [ c c2 s4 ] s3 >)
= extent(< s1 c [ c2 ] s4 s3 >), < s1 [ c c2 s4 ] s3 >)
= < s1 c [ c2 s4 ] s3 >
In the second case s2 is empty and s3 has one or more elements, while in the third case s2 and s3 are both empty. In both cases the subseq is reduced to a empty subsequence at its former end. These cases can be verified by an argument similar to that of the first.
For part (ii) we observe that the first argument to extent() is next(next(start(m))),
which cannot yield a subseq starting before the beginning of m and
the second argument is m, which ends at the end of m. Since m is empty,
the extent() must yield a subseq equivalent to m. QED
first(m) - Returns the first element of m, but if m is empty, so is first(m):
first(< s1 [ c s2 ] s3 >) => < s1 [ c ] s2 s3 >
first(< s1 [] s3 >) => < s1 [] s3 >
Lemma 3.4: An expression for first(m) is extent(m, start(rest(m))). (Proof omitted.) QED
last(m) - Returns the last element of m, but if m is empty, so is last(m):
(i) last(< s1 [ s2 c ] s3 >) => < s1 s2 [ c ] s3 >
(ii) last(< s1 [] s3 >) => < s1 [] s3 >
Lemma 3.5: Last(m) is computed by this function:
{Note: Although this definition requires a recursion, when the implementation of the algebra stores elements in contiguous memory last() can be computed more efficiently by scanning backward in the base sequence.}
Proof: Case (ii) follows trivially from the definition of rest().
Case (i) must be proved by induction on the length of m. If m has one element, then rest(m) is "" by the definition of rest(), so m is correctly returned as its own last element. If m has more than one element, we write it as < s1 [ c2 s2 c ] s3 >, the else clause is executed and we return last(< s1 c2 [ s2 c ] s3 >). By the inductive hypothesis, the latter expression gives the correct value. QED
As a tool for later sections and as an example of first() and rest(), consider a simple token scanner. The function token(s, chset) below will scan forward through the subseq s and find the first token which is composed of characters from chset, where chset represents the set of characters e3ach of which appears at least once anywhere in chset. The basic scheme is to look through the subseq for an element which is in chset and then find all adjacently succeeding characters also in chset. It is a convention for pattern matching functions that the range of the search is over s if s is non-empty or otherwise over extent(s, base(s)); it is another convention that the failure value is finish(s).
It is not difficult to show that printsubsequences(s) prints all subsequences of s. We begin with a lemma.
Lemma 4.1 (Tail Recursion): If P is an operation and Q is a sequence of zero or more variables each preceded by a comma, then the function f() defined by
performs P once for each tail of x, including the final empty subsequence. That is, if x is < s1 [ c1 c2 . . . cn ] s3 > then P is executed for each of
< s1 [ c1 c2 . . . cn ] s3 >,
< s1 c1 [ c2 . . . cn ] s3 >,
. . .,
< s1 c1 c2 . . . [ cn ] s3 >, and
< s1 c1 c2 . . . cn [] s3 >.
Proof: If x is < s1 [] s3 >, then n is zero and P is executed once; the then clause is not executed because x = "". When n > 0 we argue by induction. A call to f() evaluates P once for the current value of x and then calls f recursively for rest(x). By the definition of rest, rest(x) is a tail of x so n is one less and the general case holds by induction. QED
Lemma 4.2: The call printsubsub(s, s) prints all subsequences of s that begin at start(s).
Proof: By the Tail Recursion Lemma, printsubsub(s, s) executes print(extent(s, start(t))) for t being each tail of s. This is exactly the subsets of s that begin at the beginning of s. QED
Lemma 4.3: The call printsubsequences(s) prints all subsequences of s.
Proof: By the Tail Recursion Lemma, printsubsequences(s)
executes printsubsub(s, s) for s being each tail
of the initial s. By the preceding Lemma, this call prints
the subsequences beginning at each position within s, which
is the entire set of subsequences. QED
Theorem 4.1 (Sufficiency): The subsequence algebra is sufficient to generate all subsequences of the base of a sequence.
Proof: By the preceding Lemma, if s is a sequence, the call printsubsequences(base(s)) will print all subsequences of the base of s. Since they are printed, they must have been generated. Since only the functions of the algebra have been used to operate on sequence values, those functions must be sufficient. QED
Note that the Sufficiency Theorem proves that all subsequences can be generated, but not that any specified subsequence or set of subsequences can be generated. The simplest way to do this is by showing that the algebra can simulate a Turing machine:
Theorem 4.2 (Universal Computability): The subsequence algebra is sufficient to compute any computable function.
Proof: By Church's Thesis, computable functions are those which can be computed by a Turing Machine or any equivalent machine. One such machine is the Two-Counter machine which requires simply two (very) large numbers to represent the state and the tape of a Turing machine. Since sequences in the algebra are of unlimited length, two of them can be utilized to simulate two counters--for example by a unary encoding--and thus a program in the algebra can simulate a Turing Machine. QED
If we pretend that efficiency matters for a Turing Machine, the simulation can be done more directly by utilizing a sequence for the tape with a subseq as the read head. The requirement for an infinite tape is, as usual, avoided by encoding only that finite portion of the tape which has or has had non-zero values. Each of the four operations of the Machine--write a one, write a zero, move left, and move right--can be implemented as a function with the tape as argument and producing a new tape. In order to have a subseq value on the new tape in the same position as on the old, we need a function to do the equivalent of copying a subseq along with its base:
Here are the functions for the first and last of the four Turing machine operations; the other two are similar.
In both functions nextPerSubseq is employed so the newly created value
that is returned will refer to the correct position on the tape. For
even more efficiency--as long as we are pretending it matters, it would
be better if we did not copy the entire tape at each iteration but
instead modified the existing sequence. To do so requires that the
algebra be extended as described in the next section.
Without extending the notation we can informally define replace() as:
replace(< s1 [ s2 ] s3 >, < s4 [ s5 ] s6 >)
if < s1 [ s2 ] s3 > is not a constant
=> Error, otherwise
This definition is inadequate because it does not describe the effect
on other subseq values that refer to the same base. Informally we
can say that replace(x, y) affects other subseqs on base(x) as though
the value of y is inserted at the end of x and then x is deleted.
Thus subseqs that begin after x are shifted along so they still refer
to the same underlying text as they did and subseqs that span x will
have new contents for the portion that was x. For subseqs which end
at the end of x there are four cases, depending on whether each of
x or the other subseq is empty or not; the action for each case is
described in Table 1 and illustrated in Figure 1.
| x is empty | x is non-empty | |
| other is empty | other precedes insertion | other follows insertion |
| other is non-empty | other includes the insertion |
Rather than theoretical considerations, the basis of Table 1 is practical
experience with the algebra. In most cases it has seemed preferable
that empty subseqs remain empty after a replace. An empty subseq often
indicates a position to begin further processing, so when the x and
the other subseq are both empty the other is left preceding the insertion
so the insertion will be processed. But when x is non-empty the other
subseq originally followed x and should still follow the replacement.
The subseq a / bcd / EFGHijkl becomes a / bcd / XYZijkl
The subseq a / bcdE / FGHijkl becomes a / bcd / XYZijkl
< The subseq a / bcdEFGH / ijkl becomes a / bcdXYZ / ijkl
The subseq a / bcdEFGHi / jkl becomes a / bcdXYZi / jkl
The subseq abcd / EFG / Hijkl becomes abcd / / XYZijkl
< The subseq abcd / EFGH / ijkl becomes abcd / XYZ / ijkl
The subseq abcd / EFGHi / jkl becomes abcd / XYZi / jkl
The subseq abcdE / FG / Hijkl becomes abcd / / XYZijkl
< The subseq abcdE / FGH / ijkl becomes abcd / XYZ / ijkl
The subseq abcdE / FGHi / jkl becomes abcd / XYZi / jkl
<> The subseq abcdEFGH / / ijkl becomes abcdXYZ / / ijkl
> The subseq abcdEFGH / i / jkl becomes abcdXYZ / i / jkl
Replace empty string between c and d in abcdef with "XYZ"
< The subseq a / bc / def becomes a / bc / XYZdef
The subseq a / bcd / ef becomes a / bcXYZd / ef
<> The subseq abc / / def becomes abc / / XYZdef
> The subseq abc / d / ef becomes abcXYZ / d / ef
With replace() we can rewrite the Turing tape operations as
To formally model replace() we must introduce the notion of a memory with a collection of base strings each having some number of subseqs. The entire contents of memory is represented in curly braces:
{ . . . , < s1 [ s2 ] s3 >, . . . < s4 [ s5 ] s6 > , . . . }
To indicate that subseqs share the same base, we label the brackets of each subseq. Thus two subseqs on the same base in memory would be:
{ . . . , < s1 [j s2 [k s3 ]j s4 ]k s5 >, . . . }
where the subsequence referred to by j is s2 s3 and that of k is s3 s4. We require that the labels on all pairs of brackets be unique, so a label both identifies a base and refers to a subsequence within it.
For convenience in the formal definition, we introduce the notion of
an "extended sequence" composed of intermixed brackets and elements from
a base sequence. To distinguish the two forms of sequence the component
items in an extended sequence are called "constituents"; each constituent
is either an element of a base sequence or a left or right bracket
which represents one end of a subseq on that base. For each label
in a well-formed extended sequence there is one left bracket and one
right bracket with that label and the left bracket precedes the right.
The Greek letters appearing as meta-linguistic variables below take
as values subsequences of extended sequences (but not references to
these subsequences).
Using bracket labels to indicate subseq values, the function we wish to define is
replace(p, q) => r
which has two subseq arguments and returns a third. The memory representation prior to executing the function is
{ . . . < sb1 [p sb2 ]p sb3
>
. . . < sb4 [q sb5 ]q sb6 >
. . . }
where
The subsequences p and q may overlap on the same base, so the formal definition must make a copy of q. It does so by introducing a new base string in the memory representation with an otherwise unused label denoted by x. The first rule just makes this copy:
(1) { . . . < sb1 [p sb2 ]p
sb3 >
. . . < sb4 [q sb5 ]q sb6 >
. . . }
=> { . . . < sb1 [p sb2 ]p sb3
>
. . . < sb4 [q sb5 ]q sb6 >
. . . < [x s5 ]x > }
For the case of a non-empty p, we rewrite sb2 as s7 c b7, where
(2)
. . . < [x s5 ]x > }
=> { . . . < sb1 [p [r s5 ]r
]p b7 sb3 >
. . . }
For an empty p we assume that sb2 is also empty and rewrite sb1 and sb3 extracting and splitting the set of all brackets between the last non-bracket element of sb1 and the first character of sb3:
Since [a and ]a bound an empty subsequence between s1 and s3, they are constituents in b1. The third rule provides for inserting the replacement text s5 between b1 and b3, and again deleting the copy x and indicating the return value n.
(3) { . . . < sx1 b1 b3 sx3 >
. . . < [x s5 ]x > }
=> { . . . < sx1 b1 [p s5 ]p
b3 sx3 >
. . . }
With replace() the function ExpandTabs of Section 2 can be reduced in length by a third: lines for the variable result are removed except the one for c = "\t" which becomes
replace(c, extent(tab, base(eight)))
As another example, take the problem of replacing newlines with spaces in order to wrap short lines into paragraphs. The function WrapLines below replaces most newlines with a single space, but uses two spaces if preceded by an end of sentence or leaves the newline in place if it is followed by white space. Spaces preceding the newline are removed as well.
In some applications that create new sequence values it is crucial to start with an empty mutable value into which text can be inserted with replace(). For this the algebra is extended again with a primitive read-write constant:
newbase() => < [] >
With newbase() we can now redefine concatentation and introduce an append operation:
s ~ t == base(replace(end(replace(newbase(), s)), t)).
v ~:=
t == v := base(replace(finish(base(v)), t)), (
With append output values can be constructed by beginning with
and appending values with
As an optimization, the expression
is interpreted as
Append has the side-effect-free advantages of concatenation, but can be implemented without allocating space for another copy of result on each iteration. We can illustrate this scheme with a function to collect footnotes--delimited with curly braces--from throughout a text and construct a new text with the footnotes at the end.
end function
end while
end if
footnotes ~:= "\n\n"
result ~:= extent(m, start(l))
m := extent(next(l), m)
A regular expression parser has as its arguments a subject string to be matched against and a pattern describing what is to be found. For this example we assume that the match must be found at the beginning of the subject; it is a trivial extension to check each position to see if the pattern begins there. (There are several non-trivial algorithms for finding the pattern at an arbitrary location without doing too much backtracking.)
Four forms of regular expression are recognized by the example function:
(In some other formulations, a repetition matches only as many instances as are necessary to make the remainder of the pattern match.)
For our purposes direct matches will be individual elements and concatenations will be a sequence of patterns. For example, the pattern "abc" is the concatentation of three direct matches for a, b, and c and will match a subject if it begins with those three characters.
To describe the representation of alternation and repetition we need to introduce the notion of subseq objects: this is a subseq value which has been encapsulated as an object so it can serve as an element in a sequence. Subseq objects will be used in the representation of patterns where non-direct regular expressions are components of other regular expressions. In formal definitions a subseq object will be underlined to indicate that it is a unit.
When sequences contain subseq objects we need two additional operations, isseq and contains. The boolean function isseq(), when applied to a subseq returns True if the first element of the subseq is an embedded subseq object:
If isseq() yields True, the embedded subseq can be extracted with the contents() function. If its argument does not begin with a subseq object, contents() behaves the same as first():
Now we can specify the representation of regular expressions as sequences:
Of the four functions below for a regular expression pattern matcher, the first,--rex_match--serves only to determine what sort of expression the pattern is and to call one of the other functions to process it. The other three each handle one form of regular expression; direct patterns are handled within rep_cat, the parser for concatenations.
Note that throughout these functions the pattern argument is processed
with first and rest so the argument could be a subsequence of some
larger sequence. In contrast, the subject is permitted to extend past
the finish of the original argument to the end of its base. The reader
is challenged to revise these functions to restrict the pattern match
to the extent of the original value of s.
Acknowledgements. This work was catalyzed by Bruce Sherwood's
search for a string sublanguage for the cT educational computing environment.
I am indebted to him, Judy Sherwood, David Andersen, the Center for
Design of Educational Computing, and cT users. Initial development
of these ideas was done while in residence at the Department of Computer
Science, University of Glasgow, with the support of the Science and
Engineering Research Council (grant number GR/D89028), both under the
direction of Malcolm Atkinson. The work has also benefitted from conversations
with Kieran Clenaghan, David Harper, Joe Morris, John Launchberry,
Mark Sherman, and John Howard.
[Griswold, 1971] Griswold, R. E., J. F. Poage, and I. P. Polonsky, The SNOBOL4 Programming Language, Prentice-Hall (Englewood Cliffs, 1971).
[Griswold, 1983] Griswold, R. E. and M. T. Griswold, The Icon Programming Language, Prentice-Hall (Englewood Cliffs, 1983).
[Hansen, 1987] Hansen, W. J., Ness - Reference Manual, Computer Science Dept., Univ. of Glasgow, 1987.
[Hansen, 1989] Wilfred J. Hansen, "Ness Language Reference Manual", available on X-windows distribution tape as .../contrib/andrew/atk/ness/doc/nessman.d, Information Technology Center, Carnegie-Mellon Univ., 1989.
[Hansen, 1990a] Hansen, Wilfred J. "Programming Language Support for Multi-Media Text with an Algebra for Subsequences," Information Technology Center, Carnegie Mellon Univ. (March 1990).
[Hansen, 1990b] Hansen, Wilfred J., "Enhancing documents with embedded programs: How Ness extends insets in the Andrew ToolKit," Proceedings of 1990 International Conference on Computer Languages, March 12-15, 1990, New Orleans, IEEE Computer Society Press (Los Alamitos, CA, 1990), 23-32.
[Morris, 1986] Morris, J., Satyarayanan, M., Conner, M. H., Howard, J. H., Rosenthal, D. S. H., Smith, F. D. "Andrew: A distributed Personal Computing Environment," Comm. ACM, V. 29, 3 (March, 1986) 184-201.
[Sherwood, 1988] Sherwood, B. A., and Sherwood, J. N., The cT Language. Stipes Publishing Company, (Champaign, Illinois, 1988).
[Steele, 1984] Steele, G. L., Jr., Common Lisp: The Language, Digital Press (Bedford, MA, 1984).