
In bygone days, users were fortunate if their computer printed numeric tables with values identified by labels in upper case letters. Then came mixed case text and later the selection of characters in ASCII. More recently, computer text has come to include the full printer's arsenal: typographic styles including fonts, indentation, justification, and so on.
In parallel with program output, programming languages have advanced from the 48 characters of Fortran to double that in ASCII and even more in ISO-8859 and representations of non-European languages. It is now time for programming languages to acknowledge typographical text. Language implementations should accept styles within program text and comments, string constants should permit typography, and languages should provide operations for dealing with typographical styles. This paper describes as a set of functions the semantics of a facility for operations on styled text.
Reasonable arguments can be presented on both sides of the question of whether a language ought to support styled text. In a low-level language like C or C++ it may be desirable to forego styles in order to allow programmers to create parochial style facilities or to allow implementation of multiple facilities. For modern higher-level languages a built-in style system permits efficiency of implementation, absolves the programmer from the implementation task, and permits typography in programs that are to be manipulated by other programs (e.g., a cross-referencer or pretty-printer).
The only languages currently offering style operations are macro languages associated with word processors. At best these languages deal with styles in the step-by-step sequence of a user operating at the console: select text, apply menu operations. This works reasonably well, but may be a bit awkward for systems that are not interactive.
Ness [Hansen, 1990], the language described below, is a macro language,
but contains sufficient additional functionality to serve as a general
purpose programming language. Ness's string data type is described
in the next section. Later sections describe the styles facility as
it has been implemented and section 4 discusses various alternate designs.
Five primitive operations can be defined for the subseq type:
start(s) - returns an empty subseq referring to the position between the character before s and the first character of s.
base(s) - returns a subseq for the entire sequence of which s refers to a part.
extent(r, s) - returns a subseq for all text from the beginning of r to the end of s. If the end of s precedes the beginning of r, the value is the empty subseq at the end of s.
replace(r, s) - modifies the text underlying r so the
portion referred to by r is removed and is replaced with a copy
of s. Returns a reference to the copy of s in its new
location.
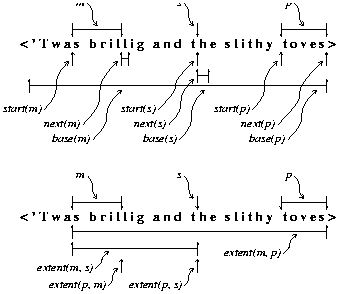
Compositions of the primitive functions can yield references to all
other interesting subsequences relative to a given subsequence. For
instance, the character which begins where s begins is next(start(s))
and the empty sequence at the end of m is start(next(m)).
Ness functions specify style values by supplying a subseq referring to text whose first character is in the desired style. The style facilities of Ness include a number of functions, but all can be described in terms of three basic functions:
hasstyles(m, s) - boolean. Returns True if all the text referred to by next(start(m)) has all of the named styles of next(start(s)). Otherwise returns False.
removestyles(m, s) - modifies the text referred to by m
so it does not have any of the named styles which apply to the character
next(start(s)). Returns m, which now refers to newly
unstyled text. (By an oversight, removestyles has not been
implemented. That it has not been missed emphasizes the fact that
most style algorithms written so far have relied primarily on addstyles
and hasstyles.)
(Clearstyles has been implemented, but there are insufficient tools to write removestyles in terms of clearstyles.)
Another important function that has been implemented is searchforstyle:
where the text within the braces is to be given the named style and the delimiters deleted. The heart of the algorithm relies on a table relating style names to styles:
In this table, each entry is in the style named in the entry; the first is bold, the second italic, and the third is in the heading style. The translator algorithm first searches for '@style{' and sets one variable, say b, to refer to the entirety of this beginning delimiter. Taking care to recursively process nested styles, it then does a second search for the closing brace and sets a second variable, say e, to refer to it. The algorithm proceeds with:
Let us assume that there is a function HeaderLine which determines whether its argument is in a header line, and if so returns the entire line; if not, it returns an empty subseq value. Then the macro continues with
where concatenation (~) always copies its arguments and produces a new string.
In principle, styles are a separate data type from text; by this light, it is incorrect to utilize styled text to represent styles. It is especially awkward in that only the first character of the styled text is applied, so any remaining text is simply ignored. However, styles are not really used enough in programs to justify the introduction of the machinery for a new data type together with suitable constants, values, and operations. Experience to date indicates that using text as the representation of a style is adequate.
If styles were a separate data type, there would be operations in that type for creating and operating on styles. With the text-representation approach, however, a style definition function is needed:
The designer of some applications may wish to allow the user to enter the name of a style to be imposed on some text. For this purpose Ness provides the function:
Another artifact of the AUIS environment is the indirection of mapping
style names to style attributes. This mapping is allowed in the Ness
implementation to affect style comparison; hasstyles compares
the names of styles rather than their attributes. This means that
two segments that have the same attributes may not compare as having
the same styles. An alternative design would assign style attributes
to text without the intervention of named style; this alternative would
be difficult to implement within AUIS text and would not have any benefits
as far as any programs tried to date.
group - consecutive text on which a style has been imposed.
The text may have additional styles nested within it.
2222 55
33333333 44444 66
111111111111111111 777
abcdefghijklmnopqrstuvwxyz
That is, d...u has style 1, fghi has style 2, and
so on. Then the style segments are abc, de, fghi,
jklm, n, op, qr, s, tu,
v, wx, y, and z; while the style
groups are d...u, fghi, f...m, opqrs,
qr, wx, and wxy. Note that the list of
style segments covers the entire text, but the style groups cover only
the text that has styles.
Traversal is done by functions whose argument is a subsequence of the text and whose result is the next succeeding appropriate subsequence:
nextstylegroup(m) - returns a subseq for a longer style group that starts at the same place as m, or if none, the shortest of the style groups that start at the next place after start(m) where a style group starts.
enclosingstylegroup(m) - returns a subseq for the smallest style group that covers the same text as m but also covers additional text.
When applied to the alphabet text above, nextstylesegment returns successively each of the listed segments. Nextstylegroup returns the segments in their numeric order. Enclosingstylegroup will perform one of these mappings:
fghijklm -> d...u
qr -> opqrst
opqrst -> d...u
wx -> wxy
Conversion from styled text to Scribe form can illustrate style traversal.
The code can utilize the same table, style_table, as in the
conversion from Scribe to styled text. If we do not have nested styles,
the appropriate loop is
Note that searchforstyle finds in style_table the entire entry from @ through {; this value is exactly the value to be inserted at start(m).
When styles can be nested, the algorithm becomes more complicated because two style groups may start in the same place. In order to get their leading delimiters in the correct order, it is necessary to perform the translation from the outermost enclosing style group inward. This can be done with a recursive function utilizing enclosingstylegroup and modifying the text just before the function exits. The alternative of constructing a new result text does not, in this case, lead to a simpler algorithm.
It is not difficult to express nextstylesegment in terms of hasstyles; the element next(m) is in the same segment as m if
It is more of a challenge to express nextstylegroup in terms of simpler functions:
-- m is first segment of group
-- extend m with all following text having at least same style as s
while hasstyles(next(m), s) do
Translator from RTF to Andrew format. Each styled portion of text in RTF is delimited with curly braces and a keyword. The translator looks up the keyword in a table and determines the translation. When the translation is a style, the proper style is taken directly from a character in the table.
American Heritage Dictionary. The source form of the American Heritage Dictionary contains macros of the form <ME>,each of which specifies the format for the succeeding text. As with the RTF translator, each macro is located in a table and the correct translation is made; styles are in the table. It is remarkable that adding bold and italic in the right places turns plain-looking text into looking exactly like a dictionary.
Few Ness programs have yet exploited the style facilities. Those that
have, however, have not uncovered any hints as to how to design the
system better. Further experiments are clearly called for.
Hansen, Wilfred J., "Enhancing documents with embedded programs: How Ness extends insets in the Andrew ToolKit," Proceedings of IEEE Computer Society 1990 International Conference on Computer Languages, March, 1990, New Orleans, IEEE Computer Society Press (Los Alamitos, CA), 23-32.
Hansen, W. J., Subsequence References: First Class Values for Substrings,
ACM Trans. Prog. Lang. and Sys. 14, 4, Oct. 1992.