Abstract
Abstract |
|
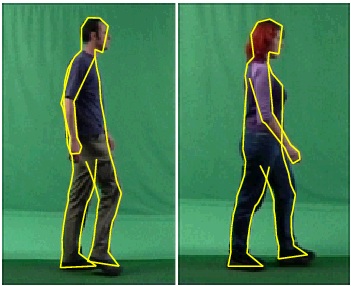
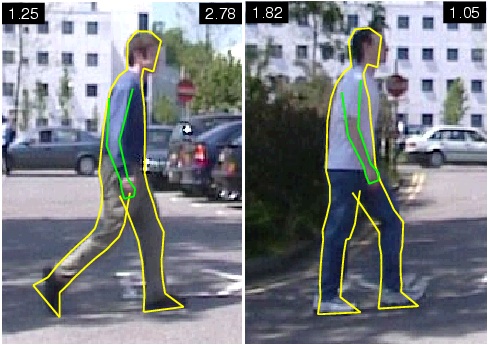
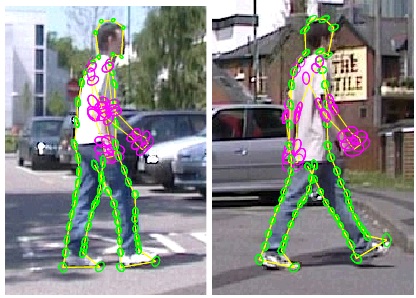
| We consider the problem of localizing the articulated and deformable shape of a walking person in a single view. We represent the non-rigid 2D body contour by a Bayesian graphical model whose nodes correspond to point positions along the contour. The deformability of the model is constrained by learned priors corresponding to two basic mechanisms: local non-rigid deformation, and rotation motion of the joints. Four types of image cues are combined to relate the model configuration to the observed image, including edge gradient map, foreground/background mask, skin color mask, and appearance consistency constraints. The constructed Bayes network is sparse and chain-like, enabling efficient spatial inference through Sequential Monte Carlo sampling methods. We evaluate the performance of the model on images taken in cluttered, outdoor scenes. The utility of each image cue is also empirically explored. | |
|
| |
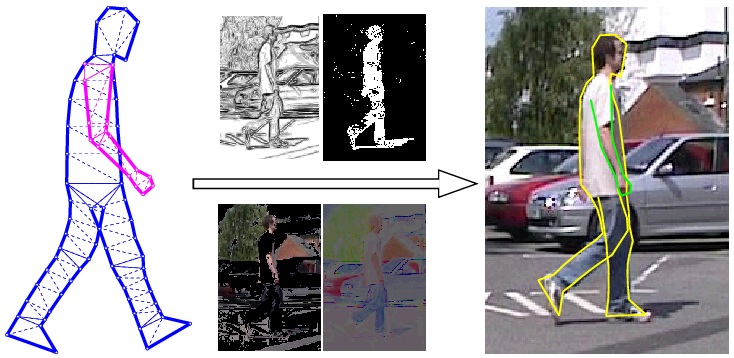
| Figure 1. Overview of our approach. An articulated non-rigid 2D body contour model (left) and local image cues (middle) are combined via Bayesian graphical modeling. The model is fit using sequential Monte Carlo to a sample image (right) taken in a cluttered, outdoor scene. | |
Publication |
|
The paper at CVPR'04:
| |
Results |
|||||||||
| |||||||||
|
Last update: May 15, 2004 |