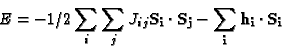
Reference: J. J. Hopfield, ``Neural networks and physical systems with emergent collective computational abilities'', Proc. Natl. Acad. Sci. USA 79, 2554 (1982)
In this, and the next lecture, we will study a type of neural network that was inspired by analogies with the physics of magnetism.
o o o o o
Low T, E --> minimum
o o o o o
crystalline solid
o o o o o
o o o o
o o o High T, S --> maximum
o o o
o o o o o liquid state
o o o o
When the system of interest is too complicated to deal with mathematically, it is common to look for a simpler system (or even an idealized model system) that has similar behavior. The ferromagnetic phase transition is interesting because magnetic systems can be described with fewer variables (the direction of the magnetic moments of the atoms, which assume discrete quantized values). This make their analysis somewhat simpler, although still difficult. At low temperatures a pure crystal of iron in a very weak magnetic field will be completely magnetized, with the magnetic moment of each atom pointing in the same direction. At about 1043 deg. K, the magnetization abruptly vanishes.
The key to being able to quantitatively describe the free energy and related thermodynamic quantities is to express the total energy of the system in terms of the states of the atoms.
The magnetic moment of a magnetic atom (Fe, Ni, Co, for example) is proportional to its quantized spin angular momentum, S. The energy of a collection of magnetic atoms can be written as
Here, the vector Si is the spin of the ith atom, and hi is proportional to the local magnetic field at the site of the ith atom. Often, it is due to an externally applied magnetic field and is the same for every atom. The dot product in the first term means that if Jij is positive, then the energy will be a minimum (most negative) if Si and Sj point in the same direction. The second term minimizes the energy when Si is in the same direction as the local magnetic field.
Jij represents the "exchange coupling" between atom i and atom j. This is a quantum mechanical effect involving the overlap of electron wave functions. It depends on the distance between the two atoms, and becomes weaker with distance, and also alternates in sign. A plot of Jij as a function of the distance between the ith and jth atoms looks roughly like an exponentially damped cosine (although it isn't described by such a simple function).
Types of ordered magnetic systems that undergo a phase transition:
The Ising model is a simplified model, in which the the spins point
either "up" (S = 1), or down (S = -1). The Ising model version of a
spin glass would have the energy
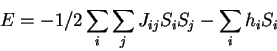
usually with the assumption that the interactions run over all pairs of spins, and the exchange couplings Jij have a Gaussian distribution about zero. An approximate solution describing the spin glass phase transition was found by David Sherrington and Scott Kirkpatrick in 1975. Since then, the Ising spin glass has been extensively studied with Monte Carlo computer simulations. To learn more about the history of the Ising model, see the Digression on the Ising Model.
This is the background behind John Hopfield's model of a neural network that acts as a content addressable memory.
The goal is to design a neural network that can be used to store patterns, and that will give back the proper stored pattern when it is presented with a partial match to the pattern. For example, instead of associating a phone number with a name by some indexing scheme that tells what memory location holds the phone number, the memory directly uses the name to get the number, or vice versa. For this reason, it is called a Content Addressable Memory, or auto-associative memory. What goes on in your mind when you try to associate a name with a face?
The Hopfield CAM model has three assumptions:
i.e. The connection strength between neuron j and neuron i is the same as that between neuron i and neuron j, and a neuron does not connect to itself.
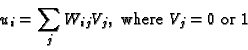
(Note that there is no bias or external input for the original Hopfield model.)
For each neuron i, in turn, set
Repeat this until there is no further change in the ``energy''
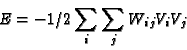
that is minimized by this procedure. This is only guaranteed to converge if the updates are applied asynchronously, i.e. using the new value of Vi right away, instead of updating all of the V's at the end of a pass through the net. This ``energy'' function is an example of a Lyapnov function. This is the term used by mathematicians to describe some function of the variables characterizing the system that tends to a minimum as an update rule is applied. Often it is hard to find such a function, or even to prove that one exists.
Except for the fact that the allowed states of a neuron are 0 and 1 instead of ±1, this is mathematically equivalent to the magnetic spin problem. In this case, nature has given us a Lyapnov function, so we know that this network will tend to a steady state.
There are three questions that we should ask at this point:
A: The pattern is presented by initializing all the Vi to an input pattern. For example, these might correspond to pixel values for a digitized letter, or the binary representation for a name, phone number and social security number. This is typically an incomplete or degraded pattern, and we want to recall the complete stored pattern. We then use the update rule given above to let the network evolve to a steady state. This will hopefully result in the stored complete pattern that is closest to the pattern that is used as the input.
A: To store a set of patterns (labeled by the index p), set the weights to

where ![]() is the set of desired states for pattern p. The nice
feature of this network is that no training cycles are needed. We have
an explicit expression for the weights in terms of the desired outputs.
is the set of desired states for pattern p. The nice
feature of this network is that no training cycles are needed. We have
an explicit expression for the weights in terms of the desired outputs.
A: This can be more easily seen if we use state variables that assume values of ±1 instead of 0 or 1. In class, we made the substitution Si = (2Vi - 1) and found that when the energy is expressed in terms of Si, the most significant term is of the form
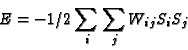
and the weights are given by
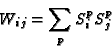
Using this expression for the weights, we get
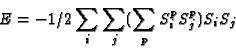
Suppose that we only have a single pattern p to store. Then E is at a minimum (the most negative) when
and the update rule leads us to a final state that is the same as the stored pattern.
If we have more than one pattern, the weights aren't optimum for the retrieval of any one pattern, but represent an average or compromise over the set of patterns. Some frustration develops. Instead of having a single minimum energy state, we will have a local minimum for each pattern. If the initial state of the network isn't too far from the stored state, the system will slide into the nearest local minimum, which will be the desired output state.

This figure represents a contour map with lines of constant energy for different values of the output of two of the neurons. (For N neurons, this would be an N-dimensional plot.) The circles each represent a "basin of attraction", or local minimum, corresponding to a stored pattern. If the initial state is displaced slightly from one of these, the network state will tend toward the stored pattern.
Normally, we think of a local minimum as something to be avoided. When we try to minimize the error in a feedforward net by using the backpropagation algorithm, getting stuck in a local minimum can keep us from finding the global minimum that produces the best set of weights. In this case, local minima are desireble. We don't want the system to settle down to some global minimum in the energy instead of finding the state corresponding to the nearest minimum.
What happens if you try to store too many patterns? What is the capacity of the Hopfield associative memory? Hopfield found in his computer experiments that the ability of the network to retrieve patterns fell dramatically when the number of stored patterns approached 15% of the number of neurons. As the number of patterns becomes large, Wij begins to look like a random variable. The term in the sum that favors a particular pattern is greatly outweighed by all the others, and the associative memory begins to look like a true spin glass.
People are fond of saying that the Hopfield net is like a spin glass, but the important distinction is that a properly behaving Hopfield net doesn't have a random connectivity matrix. A real spin glass would make a very poor associative memory.