In the last lecture, I gave an overview of the features common to most neural network models. By clicking here, you can see a diagram summarizing the way that the net input u to a neuron is formed from any external inputs, plus the weighted output V from other neurons. This is used to form an output V = f(u), by one of various input/output relationships (step function, sigmoid, etc.). These usually involve a threshold parameter, theta. At the bottom of the figure, there is a typical network, with input units receiving external inputs, hidden units which communicate only with other neurons, and output units whose outputs are visible to the outside world.
Today, we will start our examination of some specific models.
In 1943 two electrical engineers, Warren McCullogh and Walter Pitts, published the first paper describing what we would call a neural network. Their "neurons" operated under the following assumptions:
We can summarize these rules with the McCullough-Pitts output rule
![]()
and the diagram

Using this scheme we can figure out how to implement any Boolean logic function. As you probably know, with a NOT function and either an OR or an AND, you can build up XOR's, adders, shift registers, and anything you need to perform computation.
We represent the output for various inputs as a truth table, where 0 = FALSE, and 1 = TRUE. You should verify that when W = 1 and theta = 1, we get the truth table for the logical NOT,
Vin | Vout
-----+------
1 | 0
0 | 1
by using this circuit:

With two excitatory inputs V1 and V2, and W =1, we can get either an OR or an AND, depending on the value of theta:
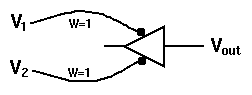
if ![]()
if ![]()
Can you verify that with these weights and thresholds, the various possible inputs for V1 and V2 result in this table?
V1 | V2 | OR | AND
---+----+----+----
0 | 0 | 0 | 0
0 | 1 | 1 | 0
1 | 0 | 1 | 0
1 | 1 | 1 | 1
The exclusive OR (XOR) has the truth table:
V1 | V2 | XOR
---+----+----
0 | 0 | 0
0 | 1 | 1 (Note that this is also a
1 | 0 | 1 "1 bit adder".)
1 | 1 | 0
It cannot be represented with a single neuron, but the relationship
XOR = (V1 OR V2) AND NOT (V1 AND V2)
suggests that it can be represented with the network

Exercise: Explain to your own satisfaction that this generates the correct output for the four combinations of inputs. What computation is being made by each of the three "neurons"?
These results were very encouraging, but these networks displayed no learning. They were essentially "hard-wired" logic devices. One had to figure out the weights and connect up the neurons in the appropriate manner to perform the desired computation. Thus there is no real advantage over any conventional digital logic circuit. Their main importance was that they showed that networks of simple neuron-like elements could compute.
The next major advance was the perceptron, introduced by Frank Rosenblatt in his 1958 paper. The perceptron had the following differences from the McCullough-Pitts neuron:
Describing this in a slightly more modern and conventional notation (and with Vi = [0,1]) we could describe the perceptron like this:

This shows a perceptron unit, i, receiving various inputs Ij, weighted by a "synaptic weight" Wij.
The ith perceptron receives its input from n input units, which do nothing but pass on the input from the outside world. The output of the perceptron is a step function:
![]()
and
![]()
For the input units, Vj = Ij. There are various ways of implementing the threshold, or bias, thetai. Sometimes it is subtracted, instead of added to the input u, and sometimes it is included in the definition of f(u).
A network of two perceptrons with three inputs would look like:

Note that they don't interact with each other - they receive inputs only from the outside. We call this a "single layer perceptron network" because the input units don't really count. They exist just to provide an output that is equal to the external input to the net.
The learning scheme is very simple. Let ti be the desired "target" output for a given input pattern, and Vi be the actual output. The error (called "delta") is the difference between the desired and the actual output, and the change in the weight is chosen to be proportional to delta.
Specifically, ![]() and
and ![]()
where ![]() is
the learning rate.
is
the learning rate.
Can you see why this is reasonable? Note that if the output of the ith neuron is too small, the weights of all its inputs are changed to increase its total input. Likewise, if the output is too large, the weights are changed to decrease the total input. We'll better understand the details of why this works when we take up back propagation. First, an example.
Before we can start, we have to ask, "how can we use this rule to modify the threshold or bias term, theta?"
Answer: treat theta as the weight from an additional input which is always "on" (V = 1). Now, consider the the net:

Unit 3 (the perceptron) receives inputs from the two input units 1 and 2, weighted by W31 and W32, and a constant input of 1, weighted by theta3.
Let ![]() and intitially set
all the weights to
and intitially set
all the weights to ![]() .
.
Then, we have
![]()
![]()
The error term is ![]() .
This means that the change in weight will be
.
This means that the change in weight will be
![]() , and the change
in the bias is
, and the change
in the bias is ![]() .
.
Now fill in this table showing the results of each iteration, stopping when there is no further change through the presentation of all four patterns. We call each set of four patterns an "epoch". In this case, we are "training by pattern" because we adjust the weights after each patttern. Sometimes, nets are "trained by epoch", with the net change in weights applied after each epoch. (I'll do the first iteration.)
| | | | | | new | new | new
V_1 | V_2 | t_3 | u_3 | V_3 | delta_3 | W_31 | W_32 | theta_3
----+-----+-----+------+------+---------+------+------+---------
0 | 0 | 0 | 0 | 1 | -1 | 0 | 0 | -0.5
0 | 1 | 1 | | | | | |
1 | 0 | 1 | | | | | |
1 | 1 | 1 | | | | | |
----+-----+-----+------+------+---------+------+------+---------
0 | 0 | 0 | | | | | |
0 | 1 | 1 | | | | | |
1 | 0 | 1 | | | | | |
1 | 1 | 1 | | | | | |
----+-----+-----+------+------+---------+------+------+---------
0 | 0 | 0 | | | | | |
0 | 1 | 1 | | | | | |
1 | 0 | 1 | | | | | |
1 | 1 | 1 | | | | | |
----+-----+-----+------+------+---------+------+------+---------
0 | 0 | 0 | | | | | |
0 | 1 | 1 | | | | | |
1 | 0 | 1 | | | | | |
1 | 1 | 1 | | | | | |
----+-----+-----+------+------+---------+------+------+---------
How many epochs does it take until the perceptron has been trained to generate the correct truth table for an OR? Note that, except for a scale factor, this is the same result which McCullogh and Pitts deduced for the weights and bias without letting the net do the learning. (Do you see why a positive threshold for a M-P neuron is equivalent to adding a negative bias term in the expression for the perceptron total input u?)
{kind=link}