- ... 0.1
- For
those few cases where
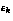 becomes 0 (less that 0.12% of our
results) we simply use a large positive value,
becomes 0 (less that 0.12% of our
results) we simply use a large positive value,  ,
to weight these networks.
For the more likely cases where
is larger than 0.5 (approximately
5% of our results) we chose to weight the predictions by a very small
positive value (0.001) rather than using a negative or 0 weight factor
(this produced slightly better results than the alternate approaches in
pilot studies).
,
to weight these networks.
For the more likely cases where
is larger than 0.5 (approximately
5% of our results) we chose to weight the predictions by a very small
positive value (0.001) rather than using a negative or 0 weight factor
(this produced slightly better results than the alternate approaches in
pilot studies).
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ... noise2
- X% noise indicates
that each feature of the training examples, both input
and output features, had X% chance of being randomly perturbed to another
feature value for that feature (for continuous features, the set of
possible other values was chosen by examining all of the training
examples).
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.