[19.1] What properties must a tree have for it to be a BST?
TFor every node n with value v, each left child (and all its children, etc.) must have values strictly less than v. Also, each right child of v (and all its children, etc.) must have values strictly greater than v
[19.2] If we know that a tree T is a BST, do we know anything special about subtrees T[“left”] and T[“right”]?
If we know that a tree T is a BST, we have by the definition of a BST that every node in T[“left”] and T[“right”] also obey the restrictions of a BST. Therefore, we have that subtrees T[“left”] and T[“right”] are also BSTs.
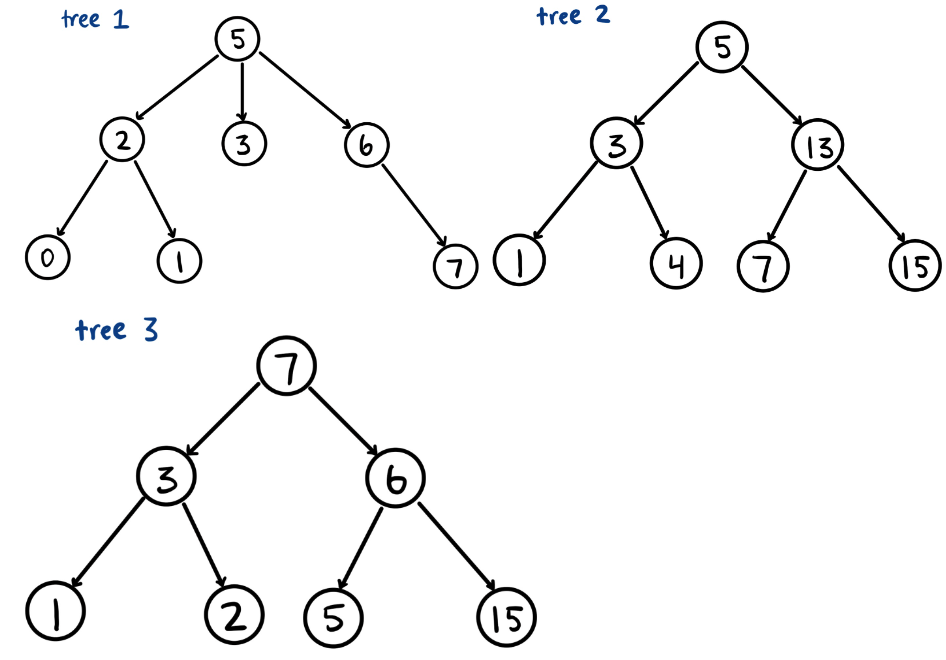
[19.3] Label each of the following as a BST, binary tree, or regular tree.
Tree 1: tree
Tree 2: BST
Tree 3: Binary tree
[19.4] Assume that we have a tree of n nodes.
What does it mean for out tree to be balanced?
If it is balanced, what is the big-O runtime of binary searching the tree?
If it is balanced, what is the big-O runtime of linear searching the tree?
If it is unbalanced, what is the big-O runtime of binary searching the tree?
If it is unbalanced, what is the big-O runtime of linear searching the tree?
The node's left and right subtrees are approximately the same size for every node in the tree.
O(logn)
O(n)
O(n)
O(n)
[19.5] In lecture, we discussed how hashed search is somewhat analogous to finding your post boxes in the UC. Please list another example of how we encounter hashed searches in our lives.
One example is the library catalog system. Knowing the book we want, we can get the specific location via a code in the catalog, to look for it in the library. This prevents us from having to look through the entire library for the book we want.
[19.6] Hash functions map values to _____? What rules must a hash function follow?
Solution:
A hash function maps values to integers. It must be deterministic, which means that whenever given a specific value x, hash(x) must always return the same output, i. Also, given two different values, x and y, hash(x) and hash(y) should usually return two different outputs, i and j.
[19.7] What is a collision? Describe in words what are some characteristics of a bad hash function? How might this affect the performance of our hashed search?
Solution
A collision describes when an element is added to a bucket of the hash table that already contains an element. A bad hash function is one that, when given different values, often returns back the same index. This implies that there will be many collisions when inserting items in our hash table. This would hurt the performance of our hashed search because when looking in a specific bucket for a value, we may need to look through many items before finding the desired one (O(n) instead of the O(1) lookup that hashing provides).
[19.8] Given a value x, a hash function f, and a hash table T, describe the process of how you would put value x into hash table T. How would you look up the value x later on?
First, we would hash the value x by calling f(x). This would give us some index i. However, i might be larger than the size of the hash table T. Therefore, we will place x into the bucket with index i % size_of_T. To later look up this value, we will again hash x by calling f(x) to get an index i. Accounting for the size of the hash table, we will look for our value in bucket i % (size of T).
[19.9] What types of data can we not place into a hashtable? Why?
We cannot place mutable values into a hashtable. We will see why with a simple example. Consider a list L = [], a hash function that returns the length of the list, and a hashtable of size 3. Based on this, we will place the list L in bucket 0. Let’s say that later on, we update L to now be L = [5]. Our hashtable however still has the value L in index 0, though it should be in index 1 now. Hence, when we search for L, the hash-function will tell us it will be in index 1; we will look into bucket 1 and not find it as it is still in index 0.
[19.10] What does hashing have to do with dictionaries?
In Python, the underlying data structure representing a dictionary is a hashtable. Dictionary keys are immutable because they are stored, along with their corresponding values, in a hash table. This allows us to check whether a key is in a dictionary in O(1) and also access the value for any key in O(1).
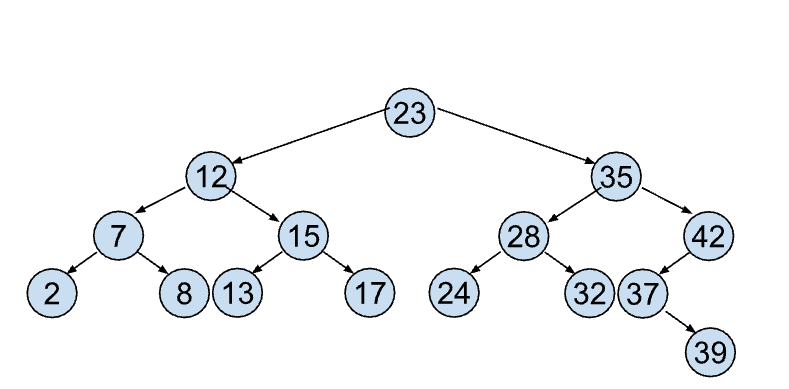
[19.11] Consider the following BST:
List the numbers you would visit if you ran a search algorithm looking for the following values:
18
32
40
9
23, 12, 15, 17
23, 35, 28, 32
23, 35, 42, 37, 39
23, 12, 7, 8
[19.12] Using the function stringHash, place the following values in the given hash table: “onion”, “noble”, “wolf”, “flowers”, “ash”. Feel free to use the ASCII Table for this question.
[19.13] Is the above a good hash function? Why or why not?
It is not a great hash function as many words may have the same length and the same middle character or last character, causing such words to collide and end up in the same bucket. A hash function that uses all the characters in the input string would make for more unique hashes and therefore be a better hash function.
[19.14] Write a function getLargest(T) which returns the largest element of the given BST.
[19.15] Which of these values can we hash? What makes something hashable?
“Hello”, ‘H’, [“hello”, 2], 3, True
We can only hash immutable datatypes (such as strings, ints). So the only valid answers would be: “Hello”, “H”, 3, True. We cannot hash mutable data types (such as lists), so [“hello”, 2] cannot be hashed.
[19.16] Write the code for how to do linear search on a Tree. Assume your function takes a tree and a target as parameters.
def search(t, target):
if t == None:
return False
elif t["contents"] == target:
return True
else:
leftSide = search(t["left"], target)
rightSide = search(t["right"], target)
return leftSide or rightSide
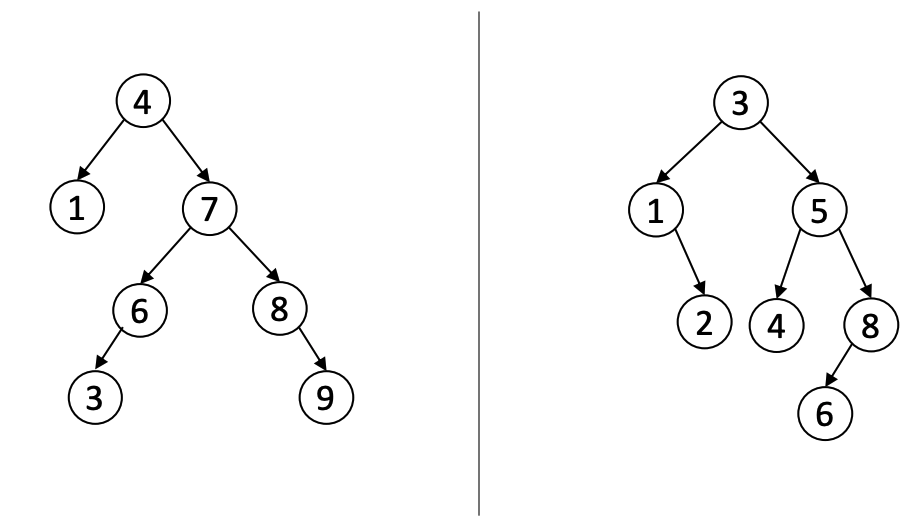
[19.17] Are the given trees BSTs? Why or why not?
The tree on the left (root 4) is not a BST. Node 3, which is smaller than 4, should be on the left side of 4, as a right parent of 1.
The tree on the right (root 3) is a BST. 1 and 2 are smaller than 3 and 5, 4, 8, 6 are bigger than 3. Applying the same rules to each subtree, we have 2 greater than 1, 4 less than 5, 8 and 6 greater than 5, 6 less than 8. Each node follows the BST properties thus this is a BST>
[19.18] Write the code for how to do binary search on a BST. Assume your function takes a tree and a target as parameters.
[19.19] Why might a binary search tree be preferred over a sorted list?
When we want to add new data to our data structure, it is easier to do so for a binary search tree. For both a BST and sorted list, we need to binary search to find the location at which the new element should go. The difference, however, is that we need to slide a bunch of values over in a sorted list to make room for the new item. In BSTs, we just need to create a node and place an edge.
[19.20] What is the runtime of the following operations? Why?
item in lst where lst is a list of elements
item in dict where dict is a dict of key-value pairs
item in lst where lst is a list of elements runs in linear time (O(n)), because Python can't guarantee that the list is sorted. It uses linear search.
item in dict where dict is a dict of key-value pairs runs in constant time (O(1)), because Python uses hashign.