 Computer Science Department |
 |
 |
 |
 |
 |
 |
 |
15-410 Project 1: Adventure
Table of Contents
- Project Overview
- Goals
- Technical Disclaimer
- Header Files
- Important Dates
- Welcome to x86 Kernel Programming
- Kernel Programming: Always Assuming the Worst
- Privilege Levels
- Segmentation
- Communicating with Devices
- Hardware Interrupts
- Traps and Exceptions
- Configuring Interrupts
- Writing an Interrupt Handler
- Console Device Driver Specification
- Writing a Character to the Console
- Communicating with the CRTC
- Console Device Driver Interface
- Timer Device Driver Specification
- Configuring the Timer
- Timer Device Driver Interface
- Keyboard Device Driver Specification
- Interacting with the Keyboard
- Keyboard Device Driver Interface
- Floating-Point Unit (FPU)
- Skeleton Kernel
- Provided C Functions
- Testing
- Tying it All Together
- Documenting
- Coding Standard
- Other Important Notes
- Testing and Debugging with Simics
- Getting Started with Simics
- A Note on "Triple Faults"
- Grading Makefile and Triple Images
- Hand-in Instructions
- Disorientation/Becoming Powerful
- Where Do I Start???
- Software license notice
Project Overview
In this introductory project you will be writing three device drivers. These three device drivers will constitute a library which will be used to construct single-task "kernel applications". We will provide you with "kernel applications" to test your three drivers.The first is the console device driver. The console device driver is responsible for printing characters on the screen. Without it, it would be rather difficult later in the semester to obtain feedback as to what is going on in your operating system or user applications.
The second device driver you will write is the keyboard device driver. Whenever the user presses a key, the keyboard device driver needs to find out what key it is, whether it was pushed or released, and then make that information available to the operating system. An important aspect of the keyboard device driver is that it is interrupt driven. We will take a closer look at what this means later.
The third "device driver" is the timer handler. While we do not often think of the on board PC timer as a device, it generates interrupts just like the keyboard. The timer is a critical device that will be used later in context switching between processes.
It is not possible to test these device drivers on their own. In order
to develop and test them, you will be provided with a skeleton
kernel. The kernel performs some very basic machine initialization
such as transitioning to protected mode. Once this initialization is
complete, it transfers control to the application's
kernel_main() function, which will initialize your device
drivers and begin executing application-specific code. There is no
virtual memory and no file system.
Once you have implemented the three device drivers, you will use the three of them to support Adventure, a game of cave exploration. A detailed explanation of the desired behavior is presented later in this handout.
Goals
Despite the fact that this is a small project relative to the kernel,
it is important to pay attention to the key concepts in Project 1. The
ideas taught here will provide the foundation for the next three
projects. In particular, we would like you to be comfortable with:
Writing clean code in C. Many people like the C programming language because it gives the programmer a lot of freedom (pointers, casting, etc). It is very easy to hang yourself with this rope. Developing (and sticking with) a consistent system of variable definitions, commenting, and separation of functionality is essential.
People have asked about using C++ in this class. This is probably much harder than you think, since you would need to begin by implementing your own thread-safe (or, at least, interrupt-aware) versions of new and delete. In addition, you would probably find yourself implementing other pieces of C++ runtime code; this could turn into quite a hobby. We strongly recommend that you do this program in C as a way of re-familiarizing yourself with the language you'll be using for the remainder of the course.
- Writing pseudocode or code outlines. For systems programming, it is very important to think out crucial data structures and algorithms ahead of time since they become important primitives for the rest of the system.
- Commenting. Though you will not be working with a partner for the first project, you will be on all subsequent projects. It is important to include comments so someone else looking at or maintaining your code can quickly understand what your code is doing without having to look at its internals. We will be using a system called doxygen that creates documents similar to javadoc.
- Debugging/testing operating system code. We will be using Simics, an instruction set simulator with a built-in debugger to debug and test; it is similar to gdb, but has some important differences and will take some getting used to.
- Using common development tools (gcc, ld).
- Understanding device drivers: their role in the system, and their requirements.
- Communicating with the TAs using various channels of communication
(
 , course web page,
office hours).
, course web page,
office hours).
In addition to these primary goals, mundane details such as software installation (e.g., getting AFS installed on a personal Linux machine) should be taken care of by the end of Project 1.
Technology Disclaimer
Because of the
availability, low cost, and widespread use of the x86 architecture, it
was chosen as the platform for this sequence of projects. As its
creator, Intel Corporation has provided much of the documentation used
in the development of these projects. In its literature, Intel uses
and defines terms like interrupt, fault, etc. On top of this the x86
architecture will be the only platform used in these projects.
The goal of this project set is certainly not to teach the idiosyncrasies of the x86 architecture (or Intel's documentation). That said, it will be necessary to become accustomed to the x86 way of doing things, and the Intel nomenclature, for the purposes of completing this project set. Just keep in mind that the x86 way of doing things is not the only way of doing things. It is the price to be paid for learning the principles of operating systems on a real world system instead of a simulated architecture.
Header Files
In many places within this document, we will refer to #defines in several .h files. The directories mentioned will be created when you untar the project tarball and follow the "getting started" directions.
As was the case with Project 0, we have once again included contracts.h for those students who wish to use it. Note the contracts will be enforced only when DEBUG is #defined (which is not true by default; see config.mk for how to turn DEBUG on).
According to august standards bodies, assert() is required to do nothing (be compiled out) when NDEBUG is defined (which is not true by default; see config.mk for how to turn NDEBUG on). However, some predicate checks should always be made, even in "production code", even if assert() and/or the contracts.h macros are disabled. It is especially true of kernel code that some predicate checks should always be made. To that end, we have extended assert.h with four macros that always evaluate the specified expressions, regardless of "debug settings", and tastefully invoke panic() as required. Examples follow:
- affirm(3 > 0);
- affirm_msg(3 > 0, "arithmetic broken around %d and %d", 3, 0);
- reject(0 > 3);
- reject_msg(0 > 3, "arithmetic broken around %d and %d", 0, 3);
Important Dates
- Monday, January 31st
- Project 1 assigned.
- Wednesday, February 2nd
- You should at least: be familiar with using Simics, have console output working, and have started on the keyboard and timer interrupts.
- Monday, February 7th
- Project 1 is due at 11:59pm.
Welcome to x86 Kernel Programming
These projects will be a new experience for many of you because they are special in two ways. The first is that, as kernel programmers, you are subject to a number of constraints that do not show up in user-level programming. The second is that you will need to look down at the hardware you are running on and manipulate device registers/processor data structures to get your kernel to work. Because this is new for many of you, the following section is devoted to saying a few things about kernel programming, and then summarizing some of the important features of the x86 architecture which you will need to know.
Kernel Programming: Always Assuming the Worst
Programming in the kernel is quite different from writing user level applications. As has been emphasized in class, safety is a priority in kernel code - that is, checking pointers passed to you by user code before you dereference them, testing all possible cases to ensure there are no infinite loops, etc. Kernels need to be as absolutely bulletproof as possible. For example, the following line will happily execute as part of your kernel:
*(unsigned int *)0x0 = 0x1badd00d;
Wild pointer accesses are much more dangerous in kernel mode because valuable kernel data structures are not protected by the user mode/kernel mode protection schemes of the processor (discussed here shortly). Dereferencing and writing to a bad pointer like this within the kernel can overwrite crucial kernel data, or reboot the (simulated) machine, or worse!
Privilege Levels
The x86 architecture uses privilege levels to make defending the kernel against wild user processes easier. There are four privilege levels ranging from zero to three, with zero being the most privileged and three being the least. At any given time, the processor is "executing" in one of these four privilege levels. As you might have already guessed, your kernel code will execute at privilege level zero, while user code should execute at privilege level three. We will not be using privilege levels one or two in these projects. We will refer to privilege levels zero and three as PL0 and PL3 respectively. Because of the way privilege levels are explained in section 4.5 of intel-sys.pdf, privilege levels are often called "rings" (as in ring zero or ring three), though we will try to avoid that notation in these projects.
The processor checks the privilege level (PL) in a number of circumstances, such as when an attempt is made to execute a privileged instruction. These are instructions that modify control registers or change how the processor is running (a list of these instructions can be found in section 4.9 of intel-sys.pdf). These are instructions we would want only the kernel to be able to execute, so they are only allowed only while the processor is running in more privileged levels (such as PL0). If you try to execute such instructions at other privilege levels, a fault occurs.
Segmentation
While we will try to avoid using segmentation as much as possible for the duration of these projects, the x86 architecture requires at least minimal use of segmentation. In order to install interrupts and manage processes you will need to understand what a segment is. Luckily, it is simpler to set up segmentation for Project 1 than it will be for you to set up virtual memory in Project 3 (especially since we have done much of the work for you).
A segment is simply a portion of the address space. Once defined, we can associate important characteristics with the segment, like the privilege level required to access the segment or whether it contains code or data. A segment does not need to represent memory that actually exists - for example, we could define a segment ranging from 0 to 4GB (the entire 32 bit address space), even though we might have only 128MB of physical memory.
Because your kernels are going to be complicated enough as it is, we will steer clear of segmentation by using only four segments. These four segments all span the entire 32 bit address space (overlapping each other completely). Two of them require privilege level 0 to be accessed, and two of them require only privilege level 3. Of each privilege level pair, one segment represents code and the other data. We have set up these segments for you.
In this project, since no code will execute in user mode, we will use
only the two PL 0 segments. To refer to these segments when
configuring kernel data structures (such as IDT entries), use the
SEGSEL_KERNEL_CS
and
SEGSEL_KERNEL_DS
constants defined in 410kern/x86/seg.h. These numbers are
segment selectors, which are simply indices into another processor
data structure, the global descriptor table (GDT). The GDT is the
place we have defined our segments. You do not have to reconfigure it
or know its format, however.
Please refer to our online document x86 Segmentation for the 15-410 Student for a more detailed explanation of segmentation. Do not worry if parts of it do not make sense at the moment as they will become clearer later in the course.
Communicating with Devices
There are two ways to communicate with a device on the x86 architecture. The first is to send bytes to an I/O port. The second is through memory-mapped I/O.
Most devices in the x86 architecture are accessed through I/O ports.
These ports are controlled by special system hardware that has access
to the data, address, and control lines on the processor. By using
special hardware instructions to read and write from these ports, we
can use I/O ports without infringing upon the normal address space of
the kernel or user applications. This is because these special
instructions tell the hardware that this "memory" reference is
actually an I/O port, not a location in actual memory. For more
information on I/O ports, consult chapter 10 of intel-arch.pdf. Both
the timer and the keyboard use I/O ports. For convenience, an
assortment of C wrapper functions are provided to you to save you from
having to break into assembly language to read or write I/O
ports. These are located in 410kern/x86/asm.h. The various
in functions read from an I/O port while the out
functions write to an I/O port. The letter after the name indicates
the size of the data being sent (b - byte, w - word/short, l -
long/int). For this project, in which you will be talking only to
primeval 8-bit I/O devices which date to the 1980's, you will probably
need only the byte-wide versions of these instructions, i.e.,
outb() and inb().
There are also some devices which are accessed by reading and writing particular addresses in traditional memory. This is called "memory-mapped I/O". This kind of memory is part of the regular address space and therefore needs to be carefully managed. The video display hardware uses both memory-mapped I/O and I/O ports, so you must clearly understand the distinction.
Hardware Interrupts
A kernel programmer often uses either I/O ports or memory-mapped I/O to send commands to devices (ranging in size from single byte commands to many words). How do hardware devices communicate with the kernel? When a packet arrives at a network interface, the user presses a key on the keyboard or moves the mouse, or any other type of event occurs at a hardware device, that device needs a way of getting the attention of the kernel. One way is for the kernel to keep asking the device if it has something new to report (either periodically or continuously). This is called polled I/O. However, this is wasteful of CPU time, and there is a better mechanism. That mechanism is the hardware interrupt.
When a device wants to raise a hardware interrupt, it communicates this desire to one of two programmable interrupt controllers (PICs) by asserting some control signals on interrupt request (IRQ) lines. The PICs are responsible for serializing the interrupts (taking possibly simultaneous interrupts and ordering them), and then communicating the interrupts to the processor through special control lines. The PICs tell the processor that a hardware interrupt has occurred and which request line the interrupt occurred on so the processor knows how to handle the interrupt. How devices are assigned to particular interrupt request lines is extremely complicated, but there are some conventions which are usually followed, displayed below.
|
|
The PIC chip used in old IBM compatibles had only 8 interrupt request (IRQ) lines. This proved to be limiting, so a second PIC was daisy-chained off of the first one. When an interrupt is triggered on the second PIC, it in turn triggers an interrupt on the first PIC (on IRQ 2). The interrupt is then communicated to the processor.
Once the processor receives an interrupt from the PIC, it needs to know how to respond. The processor reads a data structure called the interrupt descriptor table (IDT). There is a descriptor in this table for each interrupt. A descriptor contains various information about how to resolve the interrupt, most importantly where the interrupt handler is located. The interrupt handler is a piece of code that the author of the device driver writes that gets executed when that device issues an interrupt. The IDT also stores the privilege level that is required to call the handler (DPL) and the segment to use while running the handler (which determines the privilege level to run under). Once the processor locates the appropriate entry in the IDT, it saves some information about what it was doing before the interrupt occurred, then starts executing at the address of the interrupt handler. Once the interrupt handler has run to completion, the processor uses the saved information to resume its previous task. Note that IRQ numbers do not necessarily correspond to matching indices into the IDT. The PICs have the ability to map their IRQ lines to any entry in the IDT. You will be given information on which IDT entries correspond to interrupts pertaining to your projects. For Project 1, the IDT entries will correspond to the timer interrupt and the keyboard interrupt. These IDT entries are further discussed in their respective sections.
Interrupt handlers typically need to execute as quickly as possible so that the processor is free to accept future interrupts. When an interrupt is sent by the PIC, the PIC will not send another interrupt from that same source until it gets acknowledged through an I/O port. This is because interrupt handlers usually manipulate critical data structures and would not withstand being interrupted by new invocations of themselves (i.e. they are not reentrant). In particular, an interrupt handler must never block on anything. Most interrupt handlers simply make a note of work that must be done as a result of the interrupt, clear the interrupt, then terminate, leaving the work to be done at a more convenient time. Note that it may be possible for one interrupt handler to be interrupted by a different interrupt handler, so long as they do not share data structures.
Traps and Exceptions
Actual interrupts are issued by hardware asynchronously to the
instruction stream. If a program wishes to voluntarily
depart from its normal execution path to invoke a kernel service,
it can enter the mysterious underworld through a "trap door" by
issuing a trap instruction. Because Intel refers to traps as
"software interrupts", the x86 instruction is INT n,
which causes the processor to execute the n'th handler in the
IDT.
In addition to hardware and software interrupt handlers, the IDT also contains information about exception handlers. Exceptions are conditions in the processor that are usually unintended and need to be addressed. Page faults, divide-by-zero, and segmentation faults are all types of exceptions.
In Project 2 you will use system calls (and accidentally invoke exception handlers, to your sorrow). In Project 3 you will implement both system calls and exception handlers. For Project 1 our concern will be installing interrupt handlers.
Configuring Interrupts
As mentioned previously, an x86 processor uses the interrupt descriptor table (IDT) to find the address of the proper interrupt handler when an interrupt occurs. To install your keyboard (and timer) interrupt handler, you will have to install an entry in this table.
An entry in the IDT can be one of three different types: a task gate, an interrupt gate, or a trap gate (a "gate" is just a descriptor that contains information about a transition to a different piece of code - think "gate to new procedure"). We will not be using task gates because they make use of the processor's hardware task switching functionality (which we also will not use for reasons we will discuss later in the course). The difference between an interrupt gate and a trap gate is that when the processor accesses an interrupt handler through an interrupt gate, it clears a flag in one of the processor's registers to defer all further interrupts until the current handler returns. Handling interrupts through trap gates does not do this. (Why might you not want to defer all other interrupts?)
For the interrupts in this project, we will be using trap gates (in later projects you will probably use a mixture of trap and interrupt gates). Note that a single interrupt source (timer, keyboard, etc.) will not signal a new interrupt to the processor until the processor has indicated that handling of the previous interrupt from that source is ``done'', even if the system-wide interrupt-enable flag is on. You will need to give careful consideration to how long it is reasonable to defer interrupts globally and how long it is reasonable to wait before acknowledging a particular interrupt.
The format of the trap gate is given on page 151 of
intel-sys.pdf. Note that regardless of the type of the gate, the
descriptor is 64 bits long. Each gate is stored as two consecutive
32-bit words, with the first representing the least significant 32
bits of the gate. You can use this fact to index into the IDT without
knowing the type of the other gates in the table. To get the base
address of the IDT, we use an instruction called SIDT. We
have provided a C wrapper function, idt_base(), for this
instruction so you do not have to break into assembly. This is
supplied in 410kern/x86/asm.h.
Some fields in the trap gate are self-explanatory, however others are not so they are summarized here:
| DPL | The privilege level required to call the handler. If it is set to 3, then user processes can call the handler directly. For gates that handle hardware interrupts (like the keyboard and timer), it should be set to 0. |
| Offset | The offset into the segment of the interrupt handler. Since all of our segments take up the whole address space, this is simply the address of your function handler. This can be obtained in C by typing the name of the function (without any parenthesis or arguments). |
| Present (P) | Must be set to 1 for a working gate. |
| Segment Selector | The segment selector for the target code segment. This defines the privilege level the handler will run at. The interrupt handler is going to be executed at PL0 and it is code, so this needs to be set to SEGSEL_KERNEL_CS. |
| D | Size of the gate. All our gates are 32 bits (D = 1). |
This may be the first time you are required to write code which packs a data structure into a hardware-defined memory format. There are several different ways to write this kind of code. Please make sure that, regardless of the approach or style you use, your code is structured in a reasonable way.
Writing an Interrupt Handler
As
mentioned above, when the processor receives an interrupt it uses the
IDT to start executing the interrupt handler. Before the interrupt
handler executes, however, the processor pushes some information onto
the stack so that it can resume its previous task when the handler has
completed. The exact contents and order of this information is
presented on page 153 of intel-sys.pdf. In Project 1 there are no user
tasks, so the processor will be executing in PL0 all the time. This
means interrupts will not cause a privilege level change, so the
EFLAGS (a system register containing an assortment of important
flags), current code segment, and the instruction pointer will be
pushed on the stack. For Project 1 there is no error code - this is
for exception handlers.
This information is indeed enough to resume executing whatever code was running when the interrupt first arrived. However, in order to service the interrupt we need to execute some code; this code will clobber the values in the general purpose registers. When we resume executing normal code, that code will expect to see the same values in the registers, as if no interrupt had ever occurred. So the first thing an interrupt handler must do is save all the general purpose registers, plus %ebp. We need not save the stack pointer because if there is no stack change (as is the case in this project since we have no user processes), the stack pointer will be correct once we pop off all of our interrupt-related information. If there is a stack change (as there will be in Project 3 when you do have user processes), the interrupt saves the stack pointer for us. So, to recap, the registers you need to save are %eax, %ebx, %ecx, %edx, %esi, %edi, and %ebp.
The easiest way to save these registers is to just save them on the
stack. This is easily done with the PUSHA and
POPA instructions (more information on these can be found
on pages 624 and 576 of intel-isr.pdf). To save the registers before
anything else occurs, part of your interrupt handler, which we will
call a "wrapper", will be written in assembly language. All you must
do in assembly is save the registers, call your C handler (try the
CALL instruction), then restore the registers. To return
from an interrupt, we recommend the IRET instruction,
which you doubtless will wish to read up on. It uses the information
initially saved on the stack by the interrupt (EFLAGS, code segment,
instruction pointer) to return to the code executing when the
interrupt occurred. PLEASE THINK ABOUT WHY AN ASSEMBLY WRAPPER IS
USED HERE.
A final note about writing assembly. Comment your assembly profusely. One
comment per instruction is not a bad rule of thumb. Assembly code should
be grouped into files according to function according to the same principles
you use to group C code into files.
To export a symbol
(e.g., asm_timer_wrapper)
so it is visible outside the file containing it, use the .globl
directive:
.globl asm_timer_wrapper
For those of you who have not written assembly before, here is the expected form:
.globl function_name
function_name:
assembly_instruction1 #comment
assembly_instruction2 #comment
assembly_instruction3 #comment
...
Assembly files normally have a .s or .S extension. The two extensions have different meanings to gcc; gcc will run the preprocessor on assembly files named with .S, while it passes files ending in .s to the assembler unaltered. Since you'll probably want to use #defines and other preprocessor statements within your assembly code, we strongly suggest naming your assembly with the .S extension. Note that the C preprocessor will swallow C-style comments in your .S files so they won't annoy the assembler.
For C code to call your assembly-language functions, you should declare them in a header (.h) file. This is a good place for you to place doxygen comments for the assembly-language code.
Console Device Driver Specification
The job of the console device driver seems simple: take characters and print
them on the screen. For the most part, it is that simple. Keep in mind that
this console will be the front end of your kernel for the rest of the semester,
however. For this reason you will probably want it to do a few basic things
like scroll when the output reaches the bottom of the console, line wrap when a
line exceeds the width of the console, etc. The first thing to do is to
understand how to print a single character to the console.
Writing a Character to the Console
When operating in primeval text mode, the job of a PC graphics adaptor and
an attached CRT display is to
convert a rectangular array of character-display information into a rectangular
array of beta
radiation, which is beamed toward your face by a linear accelerator. Much
of this radiation is converted to photons by a layer of toxic phosphorous
compounds. Starting Project 1 early will afford you the opportunity to take
occasional breaks from exposure to this complex mixture of subatomic particle
radiation.
(If you use an LCD display instead of a CRT, you will be taking a break
from exposure to UV from the fluorescent backlight.)
The pixel pattern displayed by the graphics adaptor is controlled by a region of main memory (memory mapped I/O). Each character on the console is represented in this region by a byte pair. The first byte in this pair is simply the character itself. The second byte controls the foreground and background colors used to draw the character. These byte pairs are stored in row-major order. We have configured your graphics controller to paint a screen consisting of 25 rows of 80 characters each. The location of video memory, as well as the color codes used for the second byte of each pair, are defined in 410kern/x86/video_defines.h.
Writing a character to the console is as simple as writing a byte pair to video memory. For example to write the character 'M' on the third character of the second line (since we will number from 0, this is row 1, column 2), you would do something like this:
*(char *)(CONSOLE_MEM_BASE + 2*(CONSOLE_WIDTH + 2)) = 'M';
*(char *)(CONSOLE_MEM_BASE + 2*(CONSOLE_WIDTH + 2) + 1) = console_color;
where CONSOLE_MEM_BASE is the start location of the console
memory, CONSOLE_WIDTH is the width of the console in characters
(defined to be 80), and console_color is a variable containing the current
foreground and background color specification of your choice.
While our support code has already put the hardware in 80x25 format, you will also need to reposition or hide the hardware cursor. The hardware cursor is controlled by the Cathode Ray Tube Controller (CRTC), an important device on the video card. Communication with the CRTC is accomplished with a special pair of registers. Accessing these registers is a little different from writing to console memory as they use the I/O ports (discussed earlier).
Communicating with the CRTC
The CRTC is one of the devices which is accessed through I/O ports. It has two
registers, an index register and a data register. The index register tells the
CRTC what function you are performing on it, such as setting the hardware
cursor position. The data register then accepts a data value associated with
the operation. Because the data register is only one byte long, and the offset
of the hardware cursor (which is measured in single bytes, not two-byte pairs)
is a 16-bit integer, setting the hardware cursor position is done in two steps.
The commands to send to the CRTC, as well as the location of the CRTC I/O
ports, are defined in 410kern/x86/video_defines.h. To hide the
hardware cursor completely, simply set the position to an offset greater than
the size of the console.
Console Device Driver Interface
Now that you know how to write characters to the console and move/hide the
hardware cursor, you have the primitives you need to build a console device
driver. Here is the API that you need to implement for the driver. Note that
the API description refers to a logical cursor, a sometimes-visible
indicator of where the next character will be placed on the screen. You are
responsible for manipulating the hardware cursor-offset register as necessary
to make sure the logical cursor's visual appearance on the screen is correct.
This is a design issue: understanding what is being asked of you will
require some analysis; there is more than one solution; the clarity and quality
of your solution will influence your grade.
int putbyte(char ch);
Description: Prints character ch at the current location of the cursor. If
the character is a newline ('\n'), the cursor should be moved to the first
column of the next line (scrolling if necessary). If the character is a
carriage return ('\r'), the cursor should be immediately reset to the beginning
of the current line, causing any future output to overwrite any existing output
on the line. If backspace ('\b') is encountered, the previous character should
be erased (write a space over it and move the cursor back one column). It is
up to you how you want to handle a backspace occurring at the beginning of a
line.
Returns: The input character.
void putbytes(const char *s, int len);
Description: Prints the character array s, starting at the current location of
the cursor. If there are more characters than there are spaces remaining on the
current line, the characters should fill up the current line and then continue
on the next line. If the characters exceed available space on the entire
console, the screen should scroll up one line, and then printing should
continue on the new line. If '\n', '\r', and '\b' are encountered within the
string, they should be handled as per putbyte. If len is not a positive integer
or s is null, the function has no effect. When you scroll the screen, you are
not required to remember characters which are "pushed off" of the screen.
const char *s: The character array to be printed.
int len: The number of characters to print from the array.
Returns: Void.
void draw_char(int row, int col, int ch, int color);
Description: Prints character ch with the specified color at position (row, col). If any argument is invalid, the function has no effect.
int row: The row in which to display the character.
int col: The column in which to display the character.
int ch: The character to display.
int color: The color to use to display the character.
Returns: Void.
char get_char(int row, int col);
Description: Returns the character displayed at position (row, col).
int row: Row of the character.
int col: Column of the character.
Returns: The character at (row, col)
int set_term_color(int color);
Description: Changes the foreground and background color of future characters printed on the console. If the color code is invalid, the function has no effect.
int color: The new color code.
Returns: 0 on success, or integer error code less than 0 if color code is invalid.
void get_term_color(int *color);
Description: Writes the current foreground and background color of characters printed on the console into the argument color.
int *color: The address to which the current color information will be written.
Returns: Void.
int set_cursor(int row, int col);
Description: Sets the position of the cursor to the position (row, col). Subsequent calls to putbyte or putbytes should cause the console output to begin at the new position. If the cursor is currently hidden, a call to set_cursor() must not show the cursor.
int row: The new row for the cursor.
int col: The new column for the cursor.
Returns: 0 on success, or integer error code less than 0 if cursor location is invalid.
void get_cursor(int *row, int *col);
Description: Writes the current position of the cursor into the arguments row and col.
int *row: The address to which the current cursor row will be written.
int *col: The address to which the current cursor column will be written.
Returns: Void.
void hide_cursor(void);
Description:
Causes the cursor to become invisible, without changing its location.
Subsequent calls to putbyte or putbytes must not cause the cursor
to become visible again.
If the cursor is already invisible, the function has no effect.
Returns: Void.
void show_cursor(void);
Description:
Causes the cursor to become visible, without changing its location.
If the cursor is already visible, the function has no effect.
Returns: Void.
void clear_console(void);
Description: Clears the entire console and resets the cursor to the home position (top left corner). If the cursor is currently hidden it should stay hidden.
Returns: Void.
Timer Device Driver Specification
Unlike the console, the timer generates interrupts that must be handled
properly. If you do not handle timer interrupts quickly enough, the timer will
generate the next timer interrupt before the PIC has been reset by your timer
interrupt handler, and a timer interrupt will be lost. This may not seem like
a big deal, but even if you miss just 0.1% of the interrupts, after one day
your clock would already be minutes off.
The actual timer interrupt handler in this project is quite simple, although in
Project 3 you will be using the timer interrupt to trigger your scheduler. For
this project, you'll be using the timer interrupt to measure elapsed times.
Configuring the Timer
Communicating with the timer is done through I/O ports. These I/O ports are
defined in 410kern/x86/timer_defines.h. Also defined in that file
is the internal rate of the PC timer,
1193182 Hz (please memorize this number, as it will be used as an encryption
key in a final exam question). Fortunately, we can configure the timer to give
us interrupts at a fraction of that rate. For Project 1, you should configure
the timer to generate interrupts every 10 milliseconds.
To initialize the timer, first set its mode by sending
TIMER_SQUARE_WAVE (defined in
410kern/x86/timer_defines.h) to the
TIMER_MODE_IO_PORT. The timer will then expect you to send it the
number of timer cycles between interrupts. This rate is a two-byte quantity, so
first send it the least significant byte, then the most significant byte. These
bytes should be sent to the TIMER_PERIOD_IO_PORT.
When the timer interrupt occurs the processor consults the IDT to find out
where the timer handler is. The index into the IDT for the timer is
TIMER_IDT_ENTRY. You will need to fill in this IDT entry for your
timer handler to execute properly.
Your timer interrupt handler should save and restore the general purpose
registers. You also need to tell the PIC that you have processed the most
recent interrupt that the PIC delivered. This is done by sending an
INT_ACK_CURRENT to one of the PIC's I/O ports,
INT_CTL_PORT. These are defined in
410kern/x86/interrupt_defines.h.
Note: You will be testing this on an instruction set simulator. Even
though you are simulating an older processor on relatively fast machine, Simics
does not make an effort to exactly correlate the simulation to real wall clock
time. If you have it set up properly, it will run in real time on real
hardware.
Timer Device Driver Interface
Your timer interrupt handler is required to call an application-provided
clock-tick callback function each time the timer interrupt fires.
This callback function will be passed an unsigned integer
numTicks
containing the total number of timer interrupts your handler has caught
since the game kernel began running.
Your driver will know the address of the callback function because
it will be passed as a parameter
to the handler_install() function (see below).
Each application linked against your device-driver library will provide its
own callback function (which could be as simple as immediately returning
to your handler). Timer callbacks should run "quickly", meaning that
they should return long before the next timer interrupt will
arrive.
Keyboard Device Driver Specification
Like the timer, the keyboard is also interrupt driven. Unlike timer
interrupts, keyboard interrupts signify the availability of data
which needs to be processed. The two functions of the keyboard driver
are buffering data from the interrupt handler and converting the
the keyboard's messages into a convenient format.
Interacting with the Keyboard
The keyboard hardware doesn't speak in characters--pressing the "A"
key doesn't result in an 'A' (or 'a') byte being sent to the CPU.
For one thing, the keyboard reports not only key presses but also
key releases (so if you want to type an uppercase "A" the keyboard
will typically report this sequence of four events:
shift-pressed, a-pressed, a-released, shift-released).
A further complication is that while most events fit into one byte,
some events related to "advanced" or "special" keys, such as the
arrows, cause the keyboard hardware to transmit several bytes to
the CPU. In general, a logical event such as "A" or "right arrow"
involves the keyboard controller sending approximately four
one-byte "scan codes" to the processor,
including the delivery of one interrupt per scan code.
Luckily the 410 support code includes a function, process_scancode(), declared in 410kern/x86/keyhelp.h, which encapsulates a complicated state machine. Each time you pass a scancode to process_scancode(), it will return a 4-byte "augmented character" describing the state of the keyboard's world after the scan code has been processed. The "augmented character" may be broken down by a family of helper macros to determine whether a key was pressed or released, which "modifier keys" (shift, control, alt) were held down at the time, and whether the most recent scancode completed the specification of a particular character. The augmented-character interface is discussed further below.
The index into the IDT for the keyboard is KEY_IDT_ENTRY (defined in
410kern/x86/keyhelp.h). When you receive a keyboard interrupt,
your keyboard handler needs to read the scancode from the keyboard by reading a
byte from the keyboard's I/O port (KEYBOARD_PORT, also from
keyhelp.h). You also need to tell the PIC that you
have processed the keyboard interrupt. This is done by sending a
INT_ACK_CURRENT to one of the PIC's I/O ports,
INT_CTL_PORT (see 410kern/x86/interrupt_defines.h).
So that your device driver library might be used by the widest range of applications, such as a real-time game, we will ask you to structure your keyboard interrupt handler so it does as little work as reasonably possible. In particular, you should postpone processing the scan code until you are no longer inside an interrupt handler. In other words, you should assume in Project 1 that the process_scancode() function is computationally expensive, so that performing that processing in the keyboard interrupt handler might disrupt the application. Please note: this restriction is specific to Project 1, not an eternal fact about all software in the universe!
Do not forget that your keyboard interrupt handler needs to save and restore the general purpose registers! Also, we have included functions that enable and defer interrupts in 410kern/x86/asm.h (namely enable_interrupts() and disable_interrupts() respectively). You may need to use them in your keyboard driver to ensure there are no interrupt-related concurrency problems. Certain implementations may not need them. Be sure to document the reasoning behind your use or non-use of interrupt deferral.Keyboard Device Driver Interface
The keyboard device driver has a simple interface - two functions, readchar() and readline().
int readchar(void);
Description: Returns the next character in the keyboard buffer.
This function does not stall if there are no characters in the keyboard buffer.
Returns: The next character in the keyboard buffer,
or -1 if the keyboard buffer does not currently contain a valid character.
- KH_HASDATA(augchar) returns true if the augmented character specifies a particular character value (for example, feeding process_scancode() a "left-shift-down" scancode will probably return an augmented character which does not specify a character value).
- KH_ISMAKE(augchar) returns true if the augmented character specifies a press event instead of a release event. Recall that when "a" is typed, the keyboad will generate both a "make" (press) event and a "break" (release) event.
- If a character is specified, KH_GETCHAR(augchar) returns the character itself--for example, 0x41 for an "A". Some keys, such as arrows, are represented by "extended character" values defined in the kh_extended_e enumeration in keyhelp.h.
int readline(char *buf, int len);
Description: Reads a line of characters into a specified buffer.
If the keyboard buffer does not already contain a line of input,
readline() will spin until a line of input becomes available.
If the line is smaller than the buffer, then the complete line,
including the newline character, is copied into the buffer.
If the length of the line exceeds the length of the buffer, only
len characters should be copied into buf.
Available characters should not be committed into buf until
there is a newline character available, so the user has a
chance to backspace over typing mistakes.
Characters not placed into
the specified buffer
should remain
available for other calls to readline() and/or readchar().
While a readline() call is active, the user should receive
ongoing visual feedback in response to typing, so that it
is clear to the user what text line will be returned by
readline().
Returns: the number of characters
stored into the specified buffer,
or -1 if there is an error,
such as len being invalid or unreasonably large.
In the case of an error, readline() makes no
changes to the specified buffer.
It is important to consider the interaction between readline() and readchar() while designing your implementation. Since we are operating in a single-threaded environment, only one of readline() or readchar() can be executing at any given point. However, it is valid for a program to call both readline() and readchar() in various patterns in accordance with its own logic. It is legal for your readline() implementation to use your readchar() implementation, though other code patterns are also legal.
Additional documentation, for the enthusiastic, is available at 410 Documentation For The Enthusiast.
Floating-Point Unit (FPU)
The base code which runs before your
kernel_main() function
has disabled the floating-point unit.
FPU's are fascinating and complex and the x86 FPU
is particularly fascinating (difficult to manage).
Because we will not require your kernel to correctly
implement floating point,
now is a good time to get in the habit of writing
integer-only code.
Skeleton Kernel
There is a lot of functionality missing in our bare kernel - there is no
virtual memory and no filesystem, and none of the devices are initialized.
However, we have taken care of some of these things for you, such as
bootstrapping. We also have provided many of the standard C library functions
you know and love (see the next section). The entrypoint into the kernel is
the kernel_main() function in kern/game.c,
which is called after bootstrapping.
This function does various setup work and then calls your device library's
handler_install() function to specify the address of the
timer-tick callback routine and request activation of the driver
library.
In addition, we have provided kern/fake.c containing
empty versions of functions which you must implement and spec/p1kern.h
containing the prototypes for those functions to get you started.
Provided C Functions
We have provided many of the standard C library functions for you. To see
which functions, feel free to look at the following header files in the
410kern/stdlib directory:
ctype.h
malloc.h
stdio.h
stdlib.h
string.h
Although various printing functions are provided in stdio.h (namely printf(), putchar(), and puts()) they will not work until you implement putbyte() and putbytes(). (Note, though, that implementing only one or the other will cause those functions to behave unpredictably; it will not prevent them from making output!)
Also, we have provided a function called lprintf()
and a MAGIC_BREAK macro (in 410kern/simics/simics.h)
that you may find useful for debugging purposes.
lprintf() works like printf(), but will send its
output to Simics (not to the console you're writing) and to the kernel.log file.
Unlike printf(), lprintf() does not depend on any
of your console device driver functions.
Whenever a MAGIC_BREAK is encountered within your
code, Simics will act as if it has reached a previously-set breakpoint and will
enter debugging mode.
Testing
It is important that your console, timer, and keyboard driver code
are well tested by the time you submit this assignment.
In a regular semester,
we would ask you to
write a game according to a specification we provide,
but this semester is a week shorter than a typical
semester,
so we will not ask you to write game code.
We have provided you with three ways to test your driver code; each time you boot up a PC with your code, you will use the boot loader's menu to run one test kernel.
If you select "Console Test Program", the code found in 410kern/p1test/410_test.c will lightly exercise your drivers. This will NOT be a complete test; when grading, we will run a more-extensive tester.
If you select "kern/ mini test kernel", code you provide in kern, by default kern/game.c, will run. What the non-driver code you place in kern does is up to you. The kern/game.c we initially provide you with does very little. You may wish to upgrade it to contain some mixture of driver calls to exercise your driver code as you see fit.
Finally, if you select "Adventure", the code found in 410kern/advent will run on top of your drivers. This is a bare-machine-kernel version of the venerable "Colossal Cave Adventure" game. Adventure is arguably the first work of interactive fiction. Developed in the late 1970's by Will Crowther and Don Woods as ADVENT, a FORTRAN program running on PDP-10 machines (which had 36-bit words!), it was later ported to C and Unix by Jim Gillogly, and recently further ported to the 15-410 P1 build environment by an alumni TA, Cyrus Bomi Daruwala. Another distinguished-alumni TA, Zach Snow, benevolent dictator of the popular sv2v SystemVerilog-to-Verilog transpiler, ported the save-game/restore-game code so that it works even without a file system (maybe the games are saved in "the cloud"?).
Adventure is a game from a distant era, so some of its explanations may leave a modern reader befuddled. For example, the documentation "helpfully" explains that the brief command "saves paper". This made sense when the original ADVENT was developed, because many computer users then literally did not have screens. Users would type commands on a keyboard, but responses from the computer were printed onto paper by an integrated character-by-character printer. A popular printing terminal was the Teletype Model 33. Back in the mists of the 20th century, Professor Eckhardt used an ASR-33.
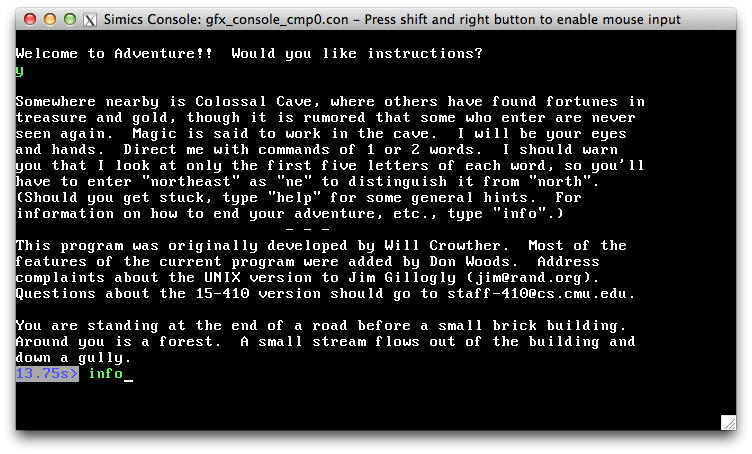
An
Adventure
game in progresss.
Tying it All Together
Congratulations. By now you should have a console driver, a timer driver, and a keyboard driver. These can now be used by any application which is linked against them, as described above. It is each application's responsibility to provide a kernel_main() function and a clock-tick callback function as described above. When you launch Simics, the boot loader will let you choose which kernel to boot.
Note about the timer:
It is useful for many kernels, including game kernels, to
have some notion of real time. We have asked you to program the timer
to interrupt the processor once every 10 milliseconds. When executed
directly on hardware (e.g., when booting a PC from a floppy drive
containing your program), an interrupt will indeed occur once every 10
milliseconds with a fair degree of precision, provided that the timer
has been programmed correctly. When emulated in Simics however, a
timer programmed to generate an interrupt every 10 milliseconds will
usually generate interrupts at a much slower rate
For example,
when measured in real time, the timer may generate an interrupt only
every 500 milliseconds.
However, depending on exactly how you write your code, Simics might
run faster instead of slower!
(If time permits, the curious may wish to read
the notes about simulation time or other emulators at The 410
Documentation For The Enthusiast.) One of the ways to test your timer
configuration is to boot your code on real hardware.
There is a "crash box"
configured for this purpose. Information about trying this is available here.
If your game runs much too fast in Simics, you can tell Simics to
avoid running faster than real time by setting the
SIMICS_REALTIME
environment variable.
However, if Simics runs your code more slowly than real time,
setting that environment variable won't help (for example,
it won't time-dilate you so that you experience time slower
than real time to match Simics!) and may well hurt.
Documenting
As mentioned in the goals section, commenting is an important part of writing code. We will be using doxygen, which generates HTML documents similar to javadoc. Please see our doxygen documentation to see how to include comments in your code that can be read by doxygen. We also expect you to submit a top-level "readme" file called README.dox that describes key design decisions. When we grade your projects, this is the first thing we will look at. Lack of documentation will be reflected in your grade. The provided game.c and p1kern.h files contain example doxygen comments with the sort of information we are expecting to see. While doxygen is equally happy to extract documentation from .c and .h files, documentation should live with program text when possible. For Project 1 this means that assembly functions should be documented in a .h file and that we are providing you with documentation for the console functions in a .h file, but otherwise documentation should appear in .c files. In addition, we have provided a rule in the Makefile to take care of generating the documents for you. This rule is make html_doc and will be how we generate your documents.Novice users often fall into the trap of believing that if they document every procedure and get Doxygen to make pretty documentation that they have adequately documented their program. It is imperative that you also document design decisions, rationale, algorithms, and invariants. In general, you want to tell the reader a story that makes logical connections from top-level requirements down to implementation details.
Coding Standard
In your documentation, please state which coding standard
(one we suggest or another one) most inspired the style of
your code.
Other Important Notes
- Since we will be running and testing your code on Andrew Linux machines,
your code will be compiled, linked, and run under gcc
9.3.0.
If you are
working on AFS, then you don't have to worry about anything: the Makefile will
run
410-gcc ,410-ld , etc. These wrapper scripts are found in the 410bin/directory, which you should have on your$PATH. If you are working on some other machine, you can copy and adjust these shell scripts. Check the version of gcc you are using by running gcc --version on the command line. If your gcc version is not the same as ours, you must make sure that your code compiles, links, and runs fine under the version we will use for grading. - Please do not change any of the provided files in the 410kern/ subdirectory. We will run your code using our versions of the files, so any changes you make will be lost. Also, please do not add any files to 410kern/. The README file in the tarball goes into more detail.
- Be sure that
handler_install()completely installs and initializes your driver code (and only your driver code) when it is invoked. Our test code will be linked against and will invokehandler_install()before using the driver library. - By long-standing tradition, in the Unix programming environment, the compiler toolchain defines certain symbols with reserved names. Avoid calling anything in your program etext, edata, or end.
- You should read the Software Setup Guide for more information on the software setup for this class and for information on files commonly found in the project tarballs.
Testing and Debugging with Simics
Debugging operating system code is typically quite difficult. One of way of doing it is to have two machines, one running a standard production OS like Linux, and the other running (and presumably crashing) the OS being developed. A serial cable is used to attach the two machines and special serial handlers installed on the development OS allow a debugger on the production OS to debug the development code. Fortunately, you will not have to deal with this. For the duration of this course, you will be testing and debugging your projects with Simics. Simics is an instruction set simulator. This means that every instruction that Simics runs is simulated, rather than run on real hardware as in VMware. For this reason Simics generally runs quite a bit slower than VMware.Because Simics simulates every instruction executed, it has some powerful debugging capabilities. It allows, for example, breakpoints to be set on memory accesses to certain locations (specifically reads, writes, executes, or any combination thereof). It also allows temporal breakpoints - breakpoints that occur after a certain number of instructions have been executed. Like the popular debugger GDB (which most of you should be familiar with from 15-213) it has some symbolic debugger capabilities as well.
By typing help at the Simics prompt, you will be presented with a list of different categories of commands. To see the commands in a specific category, type help CATEGORY. To get help on any of these specific commands, type help COMMAND. Please see our Simics Commands Guide for a list of important commands to know. Pro tip: any time you are at an impasse, you should re-read that Guide to see if you are using all the tools you have at your disposal. Please be sure to remember this tip, and apply it any time this semester that you are stuck.
Note: If you experiment with the VGA "blink" attribute, please be aware that, while most hardware implementations will obey it, Simics does not.
Getting Started with Simics
Simics has been installed on AFS and thus may be used from any Linux machine connected to AFS, subject to licensing restrictions. If you have added the 15-410 bin directory to your path, you can execute Simics on your kernel by executing simics46
If you are SSH'ing into an Andrew Linux machine with X forwarding, you should be aware that recent versions of SSH will shut down the remote machine's access to your X display after a very brief period of inactivity. In some sense this increases security, but not all that much, and it definitely reduces usability. You may wish to specify a longer inactivity timeout when you connect. There are two ways you can do this:
- You can specify a longer timeout on the command line every time you
connect, e.g.:
ssh -X -o 'ForwardX11Timeout 20m' LINUX.ANDREW.CMU.EDU
(for a 20-minute timeout), or - You can make an entry in your $HOME/.ssh/config file on the machine you are connecting from:
host linux.andrew.cmu.edu ForwardX11Timeout 20m
Further instructions on getting Simics to work within your development environment are on the Projects section of the course website. If you find that Simics updates the screen very slowly, please check out the performance hints on the setup page.
A Note on "Triple Faults"
At some point in your Simics career, you will probably encounter a "triple fault" condition. This means that while your operating system was running it ran into an exception, and while that exception was being handled a second exception was raised, and while that exception was being handled a third one was raised. At this point your average PC would just blank the screen and reboot, leaving you eternally mystified about the cause (in contrast, most non-PC computer systems provide a way to view an exception traceback). One of the nice things about Simics is that it lets you easily debug this most difficult situation.
Triple faults are easy to run into in Project 1. Since you are not installing many fault handlers, most IDT entries are invalid. If, for example, your Project 1 code makes a ferociously invalid memory reference, a machine check exception could be raised. Since you have not installed a handler for that, there is a good chance that referencing the nonexistent handler will cause a "segment not present" exception to be raised. Since you have not installed a "segment not present" handler...
When a triple fault happens, it is probably a good idea to use the Simics debugger to determine which exception or interrupt the processor encountered, figure out why that event took place, and come up with a plan for dealing with the situation. One way (but there are plenty more!) to end up in this situation is to receive a timer interrupt before your timer driver is complete (what could you do to avoid receiving timer interrupts?).
If you are lucky you may not get all the way to a triple fault--you may end up in our "purple screen of sadness" double-fault handler. But the place to go for advice is the same... see the 410 Triple Fault Page. The meaning of each fault condition is described in Chapter 5 of intel-sys.pdf.
Grading Makefile and Triple Images
Your code should (already) be structured so that the kernel_main() function in your game.c file (your testing "scratch space"), links with the console API, the keyboard API, and the timer device driver, which are implemented by code contained in the external modules (.o files) specified as $KERNEL_OBJS in your config.mk. Don't forget game.c must provide the callback function required by the timer API.
The 410test program provides a different kernel_main() function
which will link against the same $OBJS list and will call
your console and keyboard API functions. Before it does
that, however, it will call handler_install()
so you can set up your interrupt handlers and initialize
global variables your drivers might need.
Likewise the code in 410kern/advent will link against your
driver objects and call handler_install().
For development purposes two and a half C compilers will be available.
In your project's build configuration file,
config.mk,
you will be able to set the CC makefile variable
to one of these three values:
- gcc
- This will invoke the traditional 410 gcc,
410-gcc - clang
- This will invoke the our configuration of the "Clang" C-language front-end for the LLVM compiler suite
- clangalyzer
- This will invoke Clang, but with extra code-criticism infrastructure turned on.
Note that using more of these options during development
is unlikely to uncover more bugs.
You should assume that when we grade your project
we will use CC=gcc.
Hand-in Instructions
You will be required to hand in all your .c, .S, .h, and any other files necessary to run your code. Minimally this will include the code for your console driver, timer driver, and keyboard driver. Don't forget your config.mk file! When we run your code, it should display the behavior described in the Tying It All Together section above.See http://www.cs.cmu.edu/~410-s22/p1/handinP1.html for details.
Disorientation/Becoming Powerful
In the course of this semester, you will run into problems you've never run into before, which won't be solvable by applying only techniques you've used before. This can be disorienting, but it is totally expected and not an indication that you're stuck until you get our help.
The new problems you will run into are solvable, if you deploy new tools, techniques, and "business models".
Thus, any time you run into a problem which seems completely unfamiliar, your first response should be to identify two or three class-provided information sources, class-suggested design processes, class-documented debugger tools, etc., that you've never used before, and try applying them to this novel problem. Then, if you still need help, tell us not only the problem you're having, but also what you've tried and learned while working on it. This handout includes links to at least three new reference-material documents, conceptual briefings, and strategy guides. You'll probably need to consult at least one of them.
Investing in becoming more powerful is a necessity for doing well in this class, and it has the pleasant side effect that your new powers will keep working even after the class is over.
Where Do I Start???
Up to you! But here are some suggestions.
- As you start each assignment, it's probably a good idea to review the relevant parts of the syllabus. Remember, this is a design class, not a Google-copy-paste class. It is a particularly good idea to review the syllabus material about Stack Overflow, Chegg, and Instagram.
- You'll probably need to read this assignment document and the lecture notes more than once.
- You might want to write down a brief outline in a text file, specifying which files you intend to organize your code in and which functions will be written in each. If you don't want to outline each function, you might want to write down, for each function, a list of issues you don't know how to solve.
- Set yourself an initial goal, such as displaying your name in the middle of the screen in some approximation of your favorite color. This will take longer to accomplish than you think.
- Don't defer managing the cursor until the last minute, because figuring that part out often takes more than a minute.
Software license notice
Some of the library software used in this class is used under license (more info).
[Last modified Monday January 31, 2022]