
Code Conversion in Distributed Storage Systems
 Figure 1: diagram showing the code conversion process in a distributed storage system.
Figure 1: diagram showing the code conversion process in a distributed storage system.
Introduction
Today’s society is data-driven, and many of the applications that society relies on require storing ever-increasing amounts of data. To this end, distributed storage systems have become the foundation of the data infrastructure, for example cloud storage systems. These large-scale systems are typically run on massive clusters which have thousands to millions of disks, and store amounts of data on the scale of exabytes (\(10^{18}\) bytes). At this large scale, failures become a common ocurrence. Given the fundamental role that distributed storage systems play in supporting other applications, they must guarantee high levels of reliability despite these failures. One common way to ensure reliability is through replication. However, duplicating (or triplicating) the amount space used with replication is prohibitively expensive. Instead, most current large-scale storage systems primarily employ erasure codes . An erasure code encodes data in a way that makes it resilient against failures with lower overhead than replication.
The level of fault tolerance and the storage space consumed by an erasure code are determined by its parameters. For example, the popular Reed-Solomon codes (and other traditional maximum-distance separable codes) have two main parameters: code length (\(n\)) and dimension (\(k\)). These parameters are typically set based on the failure rate of storage devices, the required degree of reliability, and some additional requirements on system performance and storage overhead.
In practice, there are multiple reasons which necessitate changing the parameters of an erasure code for already-encoded data . The process of transforming the data from the old encoding to the new encoding is known as code conversion (see figure 1 ). One of the reasons for doing code conversions is disk-adaptive redundancy ( Kadekodi et al. 2019 ): it has been shown that the failure rate of disks can vary drastically across make/models and over time ( Schroeder and Gibson, 2007 ), and that significant savings in storage space (and hence operating costs) can be achieved by tuning the code parameters to the observed failure rates. For example, on production cluster traces from Google, disk-adaptive redundancy can lead to up to 25% space savings ( Kadekodi et al. 2020 ). Due to the large scale, this translates to savings of millions of dollars and significant reductions in the carbon footprint. Another reason for code conversion is the changes in the popularity of data. More popular data is typically encoded with higher redundancy (to support faster reads) and less popular data is encoded with less redundancy (for storage efficiency). Thus, as popularity of the data changes, it is beneficial to change the parameters of the code used to encode the data ( Xia et al. 2015 ). In this case, data needs to be redistributed to make use of the new disks I/O throughput.
The default approach to code conversion is to read all data, re-encode it, and write it back. This approach requires a large amount of disk I/O access and bandwidth which, due to inherent physical limitations of hard disk drives, are very scarce resources. The following figure (from Kadekodi et al. 2020 ) shows the fraction of the total cluster I/O used by code conversion in a simulation using real-world cluster traces.
 Figure 2: Trace-based simulation of a cluster using the default approach to code conversion. X-axis represents calendar date, left Y-axis represents the total fraction of the IO used by conversion, right Y-axis shows the size of the cluster in terms of the number of disks.
Figure 2: Trace-based simulation of a cluster using the default approach to code conversion. X-axis represents calendar date, left Y-axis represents the total fraction of the IO used by conversion, right Y-axis shows the size of the cluster in terms of the number of disks.
Observe that the total IO used by code conversion can use up to 100% of the cluster IO during significant periods of time. Therefore, the default approach to code conversion can easily overwhelm a storage system, interfering with other important (foreground) tasks such as serving user requests. In this post, we summarize our work on convertible codes , which are erasure codes that can be converted more efficiently than the default approach. So far the information theory community has extensively studied various aspects of storage codes such as rate, update cost, repair bandwidth, and repair locality. The conversion problem opens up a new dimension to optimize for when designing storage codes. There are several open problems in this new design space, with a high potential for real-world impact.
We start by providing some background about storage systems, erasure codes, and the way erasure codes are used in storage systems. Then, we introduce and formally define code conversion and convertible codes . Afterwards, we provide a summary of our results and showcase some examples that show how convertible codes can reduce conversion cost. Finally, we conclude with some open problems .
Background on storage systems
Many modern applications require storing large amounts of data; amounts which far exceed the capacity of a single disk drive. In such cases, data needs to be distributed across many disks, attached to many different machines. One immediate problem that emerges in this scenario is that, as the number of components in the system increases, the probability that at least one component fails becomes very high. Because distributed systems need to keep running despite of these failures, reliability is an essential part of their design.
The simplest way of adding reliability to a distributed storage system is to use replication : each piece of data has multiple copies each stored in a different disk, so that if any disk fails, no data is permanently lost. However, replication significantly increases the total amount of space used by the system, which makes it very expensive to use in large-scale systems. For example, three-replication (which tolerates up to two failures) is used in some systems, and it uses 200% additional storage. Storage cost is normally measured as the ratio of the total space used to the size of the original data, and is called storage overhead . So three-replication incurs a storage overhead of 3.
Given the high cost of replication, nowadays most storage systems use erasure coding instead, which can offer the same (or even higher) reliability guarantees while using much less storage space. For example, an \([5, 3]\) MDS code (explained in detail in Background on erasure codes ) can tolerate up to two failures (same as three-replication) and has a storage overhead of \(\frac{5}{3} = 1.66\), i.e., only 66.6% extra storage.
Storage overhead is one of the main cost metrics for distributed storage systems. This is because the top costs of running a system come from the cost of buying all the necessary hardware, and operating it: i.e. providing infrastructure, power, cooling, networking, etc. Such is the scale of these systems, that even a single-digit percentage reduction in storage overhead is significant.
There are many other costs and metrics apart from storage overhead. Among them, disk I/O resources come first, because it is important for the performance of the system. HDDs offer relatively low I/O bandwidth compared to the total amount of storage space, so this is often the bottleneck of the system’s throughput. Due to the mechanical overheads involved in moving the read head to the right place within a disk, the number of I/O operations (called accesses) is also an important metric. Similarly, the amount of network I/O operations, CPU, and memory usage are also important.
Distributed storage system design
One of the most well-known types of distributed storage systems is RAID . A RAID system typically consists of an array of \(n\) disks with same capacity attached to a single machine. Data is encoded with an \([n, k]\) MDS (maximum distance separable) code and for each codeword, each of the \(n\) codeword symbols is placed on a different disk.
Modern distributed storage systems require to scale past a single machine, and thus have a different design from RAID. An example of such a system is HDFS , which also supports erasure coding. These systems manage a large number of nodes and disks: sometimes thousands or tens of thousands of them. As in RAID, data is encoded with an \([n, k]\) MDS code, and each codeword symbol is placed on a different disk, but \(n\) is much smaller than the number of disks (typically \(n \leq 50\)). The disks where a codeword is placed are chosen by a semi-random placement algorithm, which tries to avoid choosing disks that might fail at the same time (e.g., by choosing disks in different racks).
Background on erasure codes
While many types of erasure codes exists, in this post we will focus specifically on linear erasure codes with the MDS property, which we explain in the following. An \([n, k]\) MDS (maximum-distance separable) erasure code takes \(k\) symbols of data, and encodes them into \(n\) code symbols with the property that any \(k\) out of the \(n\) code symbols can recover the original \(k\) data symbols. Symbols are elements from a specific finite field (denoted \(\mathbb{F}\)). Many practical applications use the finite field \(\mathrm{GF}(2^8)\), where each symbol is represented as a single byte. Let \(r \coloneqq n - k\), and let \([i] = \{1,2,\ldots,i\}\). Mathematically, an \([n, k]\) erasure code over \(\mathbb{F}\) is a function \(\mathcal{C}: \mathbb{F}^{k} \to \mathbb{F}^{n}\). Elements in the image of \(\mathcal{C}\) are called codewords .
A linear code can be described by the mapping \(\mathbf{m} \to \mathbf{m} \mathbf{G}\), where \(\mathbf{G}\) is the \(k \times n\) generator matrix . A code is MDS iff for any codeword it is possible to recover the original data after erasing any \(r\) arbitrary symbols. For linear codes, this is equivalent to the property that the \(k \times k\) matrix formed by the columns corresponding to any \(k\) code symbols is invertible. In practice, systematic codes are often used, which permit reading data without decoding. A linear code is said to be systematic if its generator matrix contains a \(k \times k\) identity matrix as a submatrix; for such codes, we refer to the \(k \times r\) submatrix defined by the remaining columns as the parity matrix \(\mathbf{P}\).
The code conversion problem
The problem of changing data encoded under an initial code \(\mathcal{C}^I\) to its corresponding encoding under a final code \(\mathcal{C}^F\) is called code conversion . In this section, we describe convertible codes , which are capable of efficiently changing the erasure code parameters from \([n^I, k^I]\) to \([n^F, k^F]\). Let us start by showing an example of convertible codes in action.
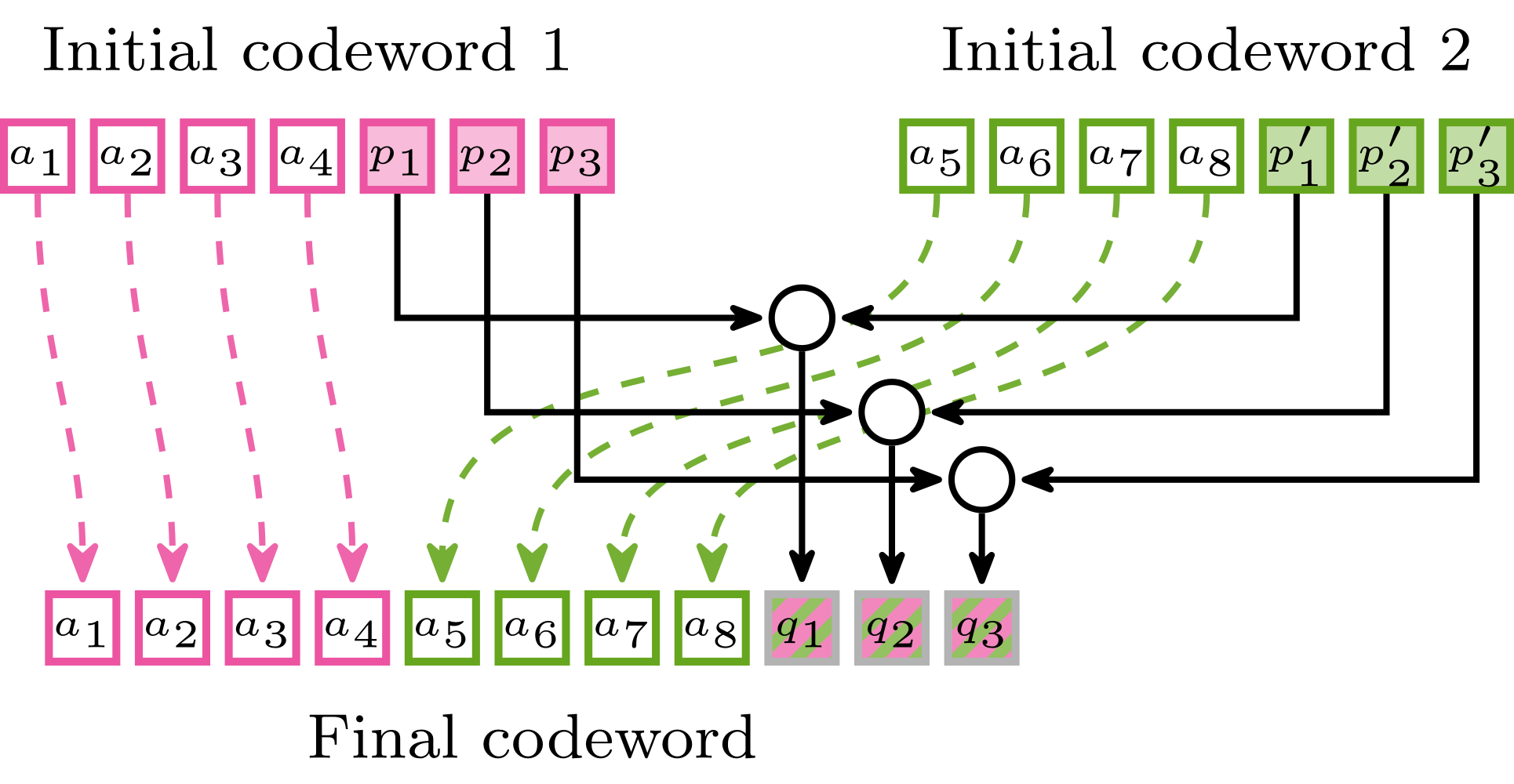 Figure 2: Example of code conversion from a \([7,4]\) MDS code to a \([11,8]\) MDS code.
Figure 2: Example of code conversion from a \([7,4]\) MDS code to a \([11,8]\) MDS code.
Example 1. Consider conversion from \([n^I = 7, k^I = 4]\) to \([n^F = 11, k^F = 8]\). In this example, both codes are systematic (i.e. the data symbols are contained in the codewords), and each box represents a symbol. Two codewords from the \([7,4]\) code are combined to obtain a single codeword from the \([11,8]\) code. The first observation we make is that since both codes are systematic, we can simply keep the data symbols where they are (i.e., unchanged) through the conversion (dashed arrows). Thus, in this case, we only need to define how the new parities are computed.
The default approach to conversion would be to read all of the data symbols \((a_1,\ldots,a_8)\), and use those to compute the new parities \(q_1, q_2\). However, it is possible to reduce that cost. Let the field \(\mathbb{F}\) be the integers modulo 17. When we define the code, we want to ensure two properties: (1) the initial and final codes are MDS, and (2) the new parities can be computed efficiently. To ensure this, we build the code from a Vandermonde matrix . In a Vandermonde matrix, each column is determined by an evaluation point (an element from the field), and row \(i\) corresponds to the evaluation point raised to the power of \(i - 1\). We can carefully choose the evaluation points to ensure the MDS property holds (it does not suffice to just choose distinct point). Choosing evaluation points \((\theta_1 = 1, \theta_2 = 2, \theta_3 = 6)\) we have: \[ \mathbf{P}^F = \begin{bmatrix} 1 & 1 & 1 \\ \theta_1 & \theta_2 & \theta_3 \\ \theta_1^2 & \theta_2^2 & \theta_3^2 \\ \theta_1^3 & \theta_2^3 & \theta_3^3 \\ \theta_1^4 & \theta_2^4 & \theta_3^4 \\ \theta_1^5 & \theta_2^5 & \theta_3^5 \\ \theta_1^6 & \theta_2^6 & \theta_3^6 \\ \theta_1^7 & \theta_2^7 & \theta_3^7 \\ \end{bmatrix} = \begin{bmatrix} 1 & 1 & 1 \\ 1 & 2 & 6 \\ 1 & 4 & 2 \\ 1 & 8 & 12 \\ 1 & 16 & 4 \\ 1 & 15 & 7 \\ 1 & 13 & 8 \\ 1 & 9 & 14 \\ \end{bmatrix}. \] Let \(\mathbf{P}^I\) denote matrix defined by the first 4 rows of \(\mathbf{P}^F\). The parities for the initial code are computed using \(\mathbf{P}^I\), and the parities of the final code are computed using \(\mathbf{P}^F\), i.e., the \((p,p^{\prime},q)\) elements in Figure 2 are defined as: \[ (p_1,p_2,p_3) = (a_1,\ldots,a_4) \mathbf{P}^I \\ (p^{\prime}_1,p^{\prime}_2,p^{\prime}_3) = (a_5,\ldots,a_8) \mathbf{P}^I \\ (q_1,q_2,q_3) = (a_1,\ldots,a_8) \mathbf{P}^F. \] It is straightforward (although tedious) to check that the codes defined with these matrices have the MDS property. During conversion, instead of reading all data we can compute simply compute the new parities from the old ones by scaling them by the appropriate powers of the chosen evaluation points: \[ (a_1,\ldots,a_4)\mathbf{P}^I + (a_5,\ldots,a_8)\mathbf{P}^I \begin{bmatrix} \theta_1^4 & 0 & 0 \\ 0 & \theta_2^4 & 0 \\ 0 & 0 & \theta_3^4 \\ \end{bmatrix} = (a_1,\ldots,a_8)\mathbf{P}^F. \] Notice that this is possible due to the Vandermonde structure of the matrices, which allows us to turn \(\mathbf{P}^I\) into the bottom half of \(\mathbf{P}^F\) by scaling each column. This allows us to compute the final parities by using the existing initial parities, without the need to read the data.
By doing this, we can achieve code conversion by reading (and transferring) just 6 symbols in total. In comparison, the default approach of read-reencode-write would require reading (and transferring) 8 symbols (i.e., all the original data symbols).
The convertible codes framework
 Figure 3: Abstract depiction of a conversion from an \([n^I,k^I]\) MDS code to a \([n^F,k^F]\) MDS code.
Each box represents a symbol, and the boxes are grouped into codewords.
The top row represents initial codewords and the bottom row represents final codewords.
Some symbols are kept unchanged, and reused in the final codewords (denoted with dashed arrows).
The converter (the node labeled “c”), reads data from some symbols in the initial codewords, and computes the new symbols in the final codewords (denoted with solid arrows).
Figure 3: Abstract depiction of a conversion from an \([n^I,k^I]\) MDS code to a \([n^F,k^F]\) MDS code.
Each box represents a symbol, and the boxes are grouped into codewords.
The top row represents initial codewords and the bottom row represents final codewords.
Some symbols are kept unchanged, and reused in the final codewords (denoted with dashed arrows).
The converter (the node labeled “c”), reads data from some symbols in the initial codewords, and computes the new symbols in the final codewords (denoted with solid arrows).
Convertible codes focus on conversions where \(\mathcal{C}^I\) is an \([n^I,k^I]\) code and \(\mathcal{C}^F\) is an \([n^F,k^F]\) code. In this post, we focus on the case where \(\mathcal{C}^I\) and \(\mathcal{C}^F\) are linear and MDS. To achieve the change in code dimension from \(k^I\) to \(k^F\) the conversion procedure needs to consider multiple codewords at a time. Let \(\lambda^I\) be the number of codewords of \(\mathcal{C}^I\) taken as input, and let \(\lambda^F\) be the number of codewords of \(\mathcal{C}^F\) produced as output. To preserve the amount of data, we must have \(\lambda^I k^I = \lambda^F k^F\). In particular, we define \(\lambda^I\) and \(\lambda^F\) as the smallest possible integers that satisfy the above equation, i.e.: \[ \lambda^I \coloneqq \frac{\mathrm{lcm}(k^I,k^F)}{k^I} \text{ and } \lambda^F \coloneqq \frac{\mathrm{lcm}(k^I,k^F)}{k^F}. \] For example, in Example 1 we have \(k^I = 4\) and \(k^F = 8\), which means that we consider a total of \(\mathrm{lcm}(k^I,k^F) = 8\) data symbols in total, which at the beginning form \(\lambda^I = 2\) codewords, and at the end form \(\lambda^F = 1\) codeword.
Since multiple codewords are being converted, we also need to specify how data is distributed across different codewords. This is specified through an initial partition \(\mathcal{P}^I\) and final partition \(\mathcal{P}^F\) of the set \([\mathrm{lcm}(k^I,k^F)]\), which indicate the \(k^I\) data symbols encoded by each initial codeword, and \(k^F\) data symbols encoded by each final codeword. Let \(\mathbf{m} \in \mathbb{F}^{\mathrm{lcm}(k^I,k^F)}\) be the data to be stored, let \(P \subseteq [\mathrm{lcm}(k^I,k^F)]\) be a subset of indexes, and let \(\mathbf{m}_{P} \in \mathbb{F}^{|P|}\) be the entries of \(\mathbf{m}\) indexed by \(P\). Then, the set of initial codewords is \(\{\mathcal{C}^I(\mathbf{m}_P) \mid P \in \mathcal{P}^I\}\), and the set of final codewords is \(\{\mathcal{C}^F(\mathbf{m}_P) \mid P \in \mathcal{P}^F\}\). In the case of Example 1 , the initial partition is \(\mathcal{P}^I = \{\{1,2,3,4\},\{5,6,7,8\}\}\), and the final partition is \(\mathcal{P}^F = \{\{1,2,3,4,5,6,7,8\}\}\), and thus the initial codewords are \(\{\mathcal{C}^I(a_1,\ldots,a_4), \mathcal{C}^I(a_5,\ldots,a_8)\}\) and the final codeword is \(\mathcal{C}^F(a_1,\ldots,a_8)\).
The conversion procedure takes the initial codewords as input, and output the final codewords. Formally, a convertible code is defined as follows.
Definition (Convertible code). A convertible code over \(\mathbb{F}\) is defined by:
- a pair of codes \((\mathcal{C}^I, \mathcal{C}^F)\) where \(\mathcal{C}^I\) is an \([n^I, k^I]\) code over \(\mathbb{F}\) and \(\mathcal{C}^F\) is an \([n^F, k^F]\) code over \(\mathbb{F}\);
- a pair of partitions \(\mathcal{P}^I, \mathcal{P}^F\) of \([\mathrm{lcm}(k^I, k^F)]\) such that each subset in \(\mathcal{P}^I\) is of size \(k^I\) and each subset in \(\mathcal{P}^F\) is of size \(k^F\); and
- a conversion procedure that on input \({\mathcal{C}^I(\mathbf{m}_P) \mid P \in \mathcal{P}^I}\) outputs \({\mathcal{C}^F(\mathbf{m}_P) \mid P \in \mathcal{P}^F}\), for any \(\mathbf{m} \in \mathbb{F}^{\mathrm{lcm}(k^I,k^F)}\).
Conversion procedure
The objective of the conversion procedure is to convert the initial codewords into the final codewords efficiently. This is modeled with a converter which reads data from some symbols in the initial codewords, and computes new symbols in the final codewords. As seen in the figure above, not all symbols in the final codewords need to be new; some symbols can be kept unchanged from the initial codewords, which incurs no cost. Since our objective is to minimize cost, we will focus only on the so-called stable convertible codes, which have \(k^F\) unchanged symbols in each final codeword (which was proven in Maturana & Rashmi, 2022a to be the maximum possible).
To decide whether a conversion procedure is efficient, we need to measure its cost. Since each final codeword has exactly \(r^F\) new symbols, the cost of writing the new symbols is fixed, regardless of the conversion procedure. Therefore, we will focus only the read costs of conversion. Two types of cost have been considered in the literature.
Definition (Access cost). The total number of symbols read by the converter.
Definition (Conversion bandwidth). The total size of the data read by the converter (note that the converter may read only part of a symbol).
In this post, we will focus only on access cost .
Conversion regimes
To facilitate the study of convertible codes, two special subcases have been identified in the literature.
Definition (Merge regime). Code conversions which merge multiple codewords into a single one, i.e., \(\lambda^I \geq 2\), \(\lambda^F = 1\), and \(k^F = \lambda^I k^F\), with arbitrary \(n^I\) and \(n^F\).
Definition (Split regime). Code conversions which split a single codeword into a multiple one, i.e., \(\lambda^I = 1\), \(\lambda^F \geq 2\), and \(k^I = \lambda^F k^F\), with arbitrary \(n^I\) and \(n^F\).
The case where all parameters \((n^I,k^I,n^F,k^F)\) are arbitrary is referred to as the general regime .
The benefit of studying the merge regime and the split regime separately, is that in these two subcases one need not worry about defining the partitions \(\mathcal{P}^I\) and \(\mathcal{P}^F\), which simplifies the analysis. This is because in these two subcases all data gets mapped to the same codeword (either in the initial or final configuration). Thus, all partitions are equivalent by just relabeling the symbols.
Minimizing the access cost of conversion
The following table shows the known lower bounds for the access cost of conversion. In this section, we will describe the constructions that achieve each of the non-trivial bounds.
Table. Summary of known lower bounds on access cost (assuming \(r^F = n^F - k^F \leq \min\{k^I, k^F\}\)).
| Regime | \(r^I < r^F\) | \(r^I \geq r^F\) |
|---|---|---|
| Merge | \( \lambda^I k^I \) (1) | \( \lambda^I r^F \) (1) |
| Split | \( \lambda^F k^F \) (2) | \( (\lambda^I - 1) k^F + r^F \) (2) |
| \( k^I = k^F \) | \( k^I \) | 0 |
| \( k^I \neq k^F\) | \(\mathrm{lcm}(k^I,k^F)\) (2) | \(\lambda^I r^F + (\lambda^I \bmod \lambda^F) (k^I - \max\{k^F \bmod k^I, r^F\})\) (2) |
(1) : Maturana & Rashmi, 2022a . (2) : Maturana et al., 2020 .
Merge regime
Recall that, in this case, \(\lambda^I\) codewords are merged into a single one. During conversion, all the data nodes are kept unchanged. To meet the bound in the table above, the converter can access \(r^F\) symbols from each initial codeword. As we saw in example 1 , this is possible by designing the parity matrices in a way that allows the converter to compute the new parities using only the old parities. This can be done, for example, by using a Vandermonde matrix, although Vandermonde parity matrices are not guaranteed to produce MDS codes. However, Maturana & Rashmi (2022a) provide a method for constructing access-optimal codes that are guaranteed to be MDS over large enough field sizes.
Split regime
Achieving the bound in table above is simple: during conversion, the converter reads the data symbols from all initial codewords except one, along with \(r^F\) initial parity symbols. Then, the read data symbols are used to compute the corresponding parity symbols, and to remove their interference from the read initial parities.
Example 2. Consider the conversion from \([n^I = 11, k^I = 8]\) to \([n^F = 7, k^F = 4]\) over \(\mathrm{GF}(17)\). Suppose we use the same \(\mathbf{P}^I\) and \(\mathbf{P}^F\) from example 1 but swapped. During conversion, the converter reads \((a_5,\ldots,a_8)\) and the 3 initial parities \((a_1,\ldots,a_8)\mathbf{P}^I\). The parity symbols of the second final codeword can be computed directly from the data; the parity symbols of the first final codeword are computed as follows: \[ (a_1,\ldots,a_8)\mathbf{P}^I - (a_5,\ldots,a_8) \begin{bmatrix} 1 & 16 & 4 \\ 1 & 15 & 7 \\ 1 & 13 & 8 \\ 1 & 9 & 14 \\ \end{bmatrix} = (a_1,\ldots,a_4)\mathbf{P}^F. \] Thus, in total 7 symbols are read, compared to the default approach of reading all 8 data symbols.
General regime
In the general regime, partitions need to specified; Maturana et al., 2020 show the optimal way of choosing them. At a high level, the optimal partition keeps data from the same initial codeword together in the final codeword whenever possible; that way, parity symbols can be used more effectively.
 Figure 4: Code conversion from \([6,5]\) MDS code to \([13,12]\) MDS code.
Figure 4: Code conversion from \([6,5]\) MDS code to \([13,12]\) MDS code.
Example 3. Consider conversion from \([n^I=6, k^I=5]\), to \([n^F=13, k^F=12]\). Thus, there are a total of \(\mathrm{lcm}(5,12)=60\) data symbols, organized into \(\lambda^I=12\) initial codewords or \(\lambda^F=5\) final codewords. The parity matrices of the codes are designed as if the final code was \([16,15]\) (which combines 3 codewords into 1). The conversion procedure splits two of the initial codewords into “intermediate codewords” (which are not materialized, but only used to describe the construction). Then, two initial codewords are merged along with two data symbols from the intermediate codewords. The split and merge are executed with the same techniques we showcased for the merge and split regime, and thus only 18 symbols need to be read (marked by a dot in the figure). Compare this the default approach of reading all 60 data symbols.
Conclusion
The code conversion problem adds a new dimension to the design of codes. This new dimension not only opens a variety of interesting theoretical questions, but has a huge potential for real-world impact in distributed storage systems. In this post, we only scratched the surface of the code conversion problem: other work on code conversion has focused on minimizing conversion bandwidth instead of access cost ( Maturana & Rashmi, 2022 , Maturana & Rashmi, 2023 ) and on codes with better repair properties ( Xia et al., 2015 , Wu et al. 2022 , Maturana & Rashmi, 2023 ) Even when considering these additional works, there are still many open questions in this nascent area of research.
References
- S. Kadekodi, K. V. Rashmi, and G. R. Ganger, “Cluster storage systems gotta have HeART: improving storage efficiency by exploiting disk-reliability heterogeneity,” FAST 2019 .
- S. Kadekodi, F. Maturana, S. J. Subramanya, J. Yang, K. V. Rashmi, and G. R. Ganger, “PACEMAKER: Avoiding HeART attacks in storage clusters with disk-adaptive redundancy,” OSDI 2020 .
- F. Maturana, V. S. C. Mukka, and K. V. Rashmi, “Access-optimal linear MDS convertible codes for all parameters,” ISIT 2020 .
- F. Maturana and K. V. Rashmi, “Bandwidth cost of code conversions in distributed storage: fundamental limits and optimal constructions,” IEEE Transactions on Information Theory , 2023.
- F. Maturana and K. V. Rashmi, “Convertible codes: enabling efficient conversion of coded data in distributed storage,” IEEE Transactions on Information Theory , 2022.
- F. Maturana and K. V. Rashmi, “Bandwidth cost of code conversions in the split regime,” ISIT 2022 .
- F. Maturana and K. V. Rashmi, “Locally repairable convertible codes: erasure codes for efficient repair and conversion,” ISIT 2023 .
- B. Schroeder and G. A. Gibson, “Disk Failures in the Real World: What Does an MTTF of 1,000,000 Hours Mean to You?,” FAST 2007 .
- S. Wu, Z. Shen, P. P. C. Lee, and Y. Xu, “Optimal repair-scaling trade-off in locally repairable codes: analysis and evaluation,” IEEE Transactions on Parallel and Distributed Systems , 2022.
- M. Xia, M. Saxena, M. Blaum, and D. Pease, “A tale of two erasure codes in HDFS,” FAST 2015 .