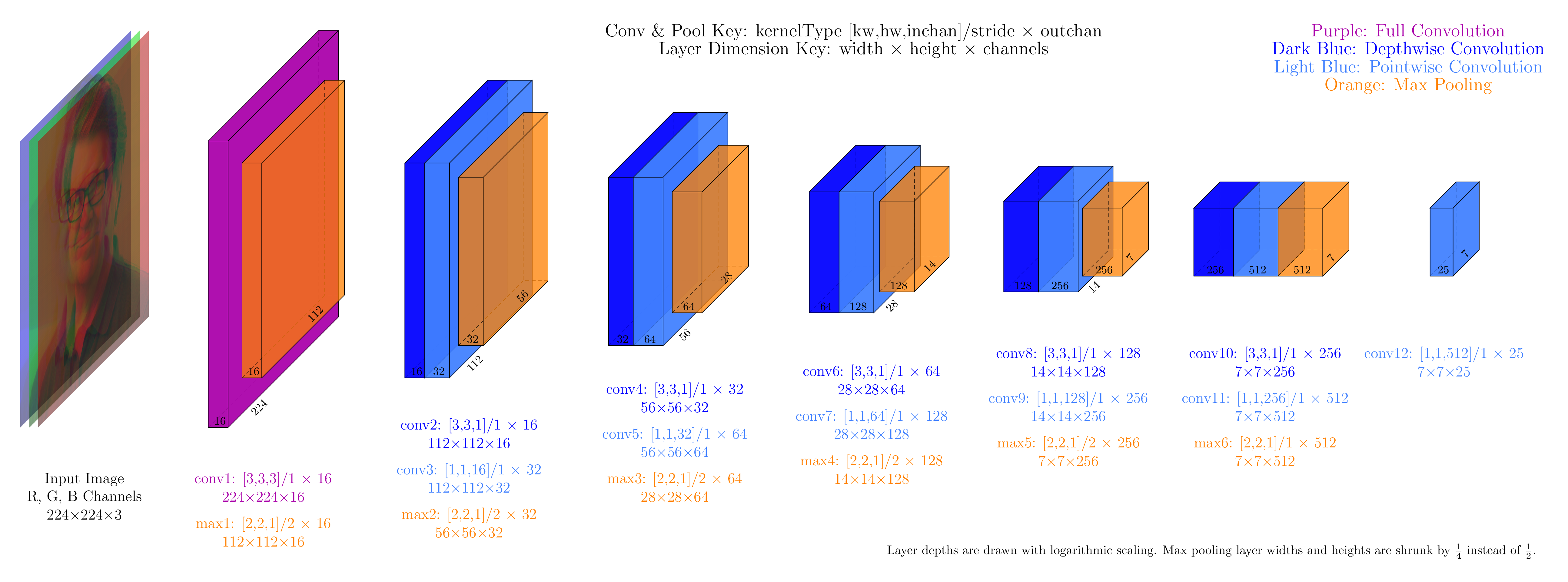
Figure 1: Architecture of TinyYOLOV2 (click for larger version).
The face detector in this demonstration is a deep convolutional neural network. It's "deep" because it has many layers. It's "convolutional" because it applies a collection of templates called "kernels" at every position in the input array, a process called "convolution". Many of these kernels are simple 3x3 arrays; some have a different shape, such as 1x1x16. To learn more about deep convolutional neural networks, see these resources:
The deep convolutional neural network used in this face detection demo is TinyYOLOV2. YOLO, or You Only Look Once, is a neural network architecture for identifying objects in images. TinyYOLO is a scaled-down version that uses fewer units and thus fits more easily on small devices such as cellphones. TinyYOLOV2 is version 2 of the TinyYOLO architecture. Figure 1 below shows the structure of TinyYOLOV2.
Figure 1: Architecture of TinyYOLOV2 (click for larger version).
The input layer of the neural net is a 224 x 224 color image with R, G, and B channels. Hence, the input has dimension 224 x 224 x 3.
You can learn more about TinyYOLOV2 from these sources:
Figure 2 shows the layout of the demo. Only two of the internal layers of the network are displayed: convolutional layer 1, and max-pooling layer 4. We also display the input layer (as an RGB image) and the output layer (as bounding boxes).

Figure 2: Layout of the Demo
The first convolutional layer, labeled conv1 in Figure 1, uses 3x3 kernels that examine all three input channels, so the kernel size is 3x3x3, or [3,3,3] in our preferred notation. Each kernel is applied to every pixel position in the image, i.e., the spacing or "stride" is 1. And there are 16 such kernels. Thus, the entire description of the conv1 layer is [3,3,3]/1 x 16. The output of the conv1 layer has shape 224 x 224 and is 16 channels deep, so it has shape 224 x 224 x 16.
The demo allows you to examine any three of the sixteen conv1 kernels simultaneously. Each kernel has a 3x3 pattern of weights for each of the three input channels R, G, and B, so a conv1 kernel's shape is 3x3x3. Since weights can be either positive or negative, we use opponent colors to display the kernels graphically. For the R channel we use red for positive weights and cyan (green + blue) for negative weights. Similarly, to show the G channel we use green for positive weights and magenta (red + blue) for negative weights, and for the B channel we use blue for positive weights and yellow (red + green) for negative weights. The output of each kernel is a single numerical value for each pixel, so it is displayed as a grayscale image.
The conv1 kernels are simple feature detectors that appear to be looking for intensity edges or color blobs. It's impossible to say exactly what each kernel is doing because there may be subtleties to the weights that aren't captured by these simplistic descriptions, but here is a summary of all 16 kernels in the conv1 layer:
The first convolutional layer (conv1) layer feeds into the first max-pooling layer (max1). Each unit in max1 examines a 2x2 patch of the conv1 output and computes the max of those 4 values. This is done separately for each of the 16 channels, so the "kernel" size is 2x2x1. (We put "kernel" in quotes because max-pooling layers don't have adjustable weights; all the kernels are effectively 1 and it's the max function that does the work.) The kernel is applied at every other pixel position, so the stride is 2. Thus the full description of the max1 layer configuration is [2,2,1]/2 x 16. With a stride of 2 we are subsampling the image, so the output of the max1 layer is smaller than the input but has the same number of channels; it has shape 112 x 112 x 16.
The first convolutional layer (conv1), shown in purple, is a full convolution. Each kernel examines a 3x3 image patch across all 3 channels (R,G,B). Thus each kernel has 3x3x3 = 27 independent parameters. There are 16 of these kernels.
Later convolutional layers have larger numbers of channels, so the YOLO architecture uses a trick to reduce the number of parameters. The trick, called "separable convolutions", replaces each full convolution with two partial convolutions. A depth-wise convolution (shown in dark blue) applies a 3x3 kernel to a single channel, so it has only 9 parameters. Then, a point-wise convolution (shown in light blue) uses a 1-pixel kernel that examines all channels, so the number of parameters per kernel is equal to the number of input channels.
Let's look at the second and third convolutional layers in Figure 1. The input to conv2 is of size 112 x 112 x 16; the output of conv3 is of size 112 x 112 x 32 because it has 32 output channels. In a full convolution, each kernel would have 3x3x16 = 144 independent parameters, and with 32 such kernels we would have a total of 4,608 parameters. Instead we decompose the problem into a depth-wise and a point-wise convolution. The conv2 depth-wise convolution layer has 16 3x3 kernels, giving it a total of 144 parameters, while the conv3 point-wise convolution layer has 32 1-pixel kernels that each examine all 16 of the channels produced by conv2, giving conv3 32x16 = 512 parameters. Thus conv2 and conv3 together have a combined total of only 656 parameters. Reducing the number of parameters reduces the size of the neural network (so it takes less space and can process images more quickly) and imposes constraints that make it easier to train.
The fourth max-pooling layer operates on the output of conv7, the 7th convolutional layer. Due to the effects of repeated convolutions and max-pooling, at this level of the network each pixel is driven by a 46x46 patch of pixels in the input image, and the features being computed in these 128 channels are more complex and abstract than the conv1 layer features. It's difficult to concisely describe what these features encode, but several of them appear to be eye detectors.
The output layer of TinyYOLOV2 produces a set of bounding boxes for candidate faces. The output is organized as a 7x7 grid. Each grid cell contains 25 units that describe five bounding boxes using five parameters each: x, y, w, h, and c. The x, y values give the center of the bounding box relative to the grid square; the w, h values give the width and height of the bounding box; the c value is the confidence that the bounding box contains a face. Figure 3 shows this output structure.
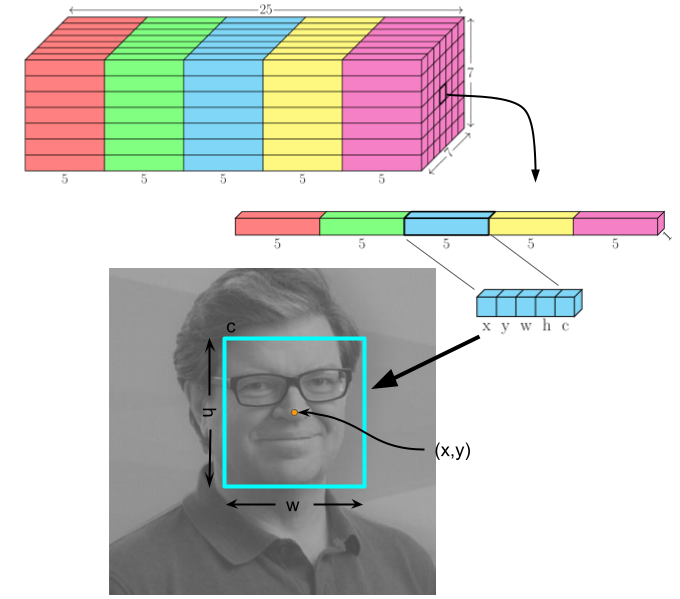
Figure 3: Organization of output layer bounding boxes.
The five bounding box detectors at each grid location are biased for different scales. In the bounding box display, the color of the box tells you which of the five detectors is responding: red for distant (small) faces, cyan for medium distant faces, yellow for medium close faces, green for really close faces, and magenta for faces that are so close they don't completely fit in the image. As you move closer to or further away from the camera, the bounding box color will change.
Social issues raised by facial recognition technology: