Discussion autour du travail de bibliographie
 Fabien
FabienProposition de plan d'attaque: fil historique avec à chaque fois les aspects suivants:
- description, pourquoi ça marche / ça a des chances de marcher
- qu'est-ce qui manque / qui a des chances de manquer.
La trame historique à améliorer:
- internet (préhistoire du Web)
- web classique (l'idée de base, pourquoi a-t-elle vu le jour ?)
- web structuré (le premier mouvement: la structure. Parler de XML et comparer avec SGML)
- web sémantique (le deuxième mouvement: la signification. Parler de RDF(S))
- perspectives
Marie et ElodieOk, mais peut-on manipuler des outils ?
FabienAutour de XML et du WS vous pouvez regarder les outils suivants:
- IsaViz
- Xalan & Xerces (XML project de Apache)
- Annotea
- et ceux de la section "Developer Resources" de la page de RDF du W3C
Elodie > XML en résumé : XML est une méthode
pour structurer des données comme des feuilles de calcul, des carnets
d'adresses, des paramètres de configuration, etc. Fabien > OK, XML c'est Extensible Markup Language, tel que
défini dans la
"W3C Recommendation 6 October 2000"
Elodie > Il est représenté sous la forme d'un fichier
texte qui n'est pas destiné à être lu, l'avantage étant
qu'un simple éditeur de texte permet son déboguage. Fabien > Très juste, le format texte est aussi un format
d'échange très pratique entre des plates-formes différentes.
Elodie > Sur certains points, il ressemble à HTML. Il utilise
par exemple un système de balises similaire dans le but de délimiter
les éléments de données, l'interprétation se
faisant par l'application qui les lit. Fabien > En fait on peut dire que c'est un méta-langage
(ou un format) pour définir des langages de balises/marqueurs utilisés
pour structurer des données et des documents. XML permet de définir
des langages tels que XHTML. Elodie > Il a cependant des règles plus strictes:
un simple problème de fermeture de balises toléré par
HTML produit une erreur et l'arrêt de l'application avec XML. Fabien > Quels sont les mécanismes de vérifications
? quelle est, en particulier, la différence entre un fichier bien
formé et un fichier valide ? Elodie > Le fichier créé est "lourd". Cependant,
l'espace disque étant de moins en moins coûteux et les méthodes
de compression de plus en plus efficaces, cela ne représente pas
un problème. Fabien > Oui, on dit que XML est "bavard". Cependant la répétition
d'un tag pour une balise ouvrante et une balise fermante, est quelque chose
qui disparaît bien à la compression Elodie > La version XML1.0 définie les "balises" et
"attributs". Fabien > XML ne définit pas à proprement parler
les balises utilisées, mais comment créer et ajouter de balises.
Le W3C dit " alors que HTML définit la signification de chaque balise
et de chaque attribut (et souvent la manière dont le texte qu'ils
encadrent apparaîtra dans un navigateur), XML utilise les balises seulement
pour délimiter les éléments de données et laisse
l'entière interprétation des données à l'application
qui les lit. En d'autres termes, si vous voyez '<p>' dans un fichier
XML, ne supposez pas qu'il s'agit d'un paragraphe. Selon le contexte, cela
peut être un prix, un paramètre, une personne, un p... (d'ailleurs,
qui a dit qu'il devait s'agir d'un mot commençant par 'p' ?)." Elodie > Il existe un grand nombre de modules facultatifs:* Xlink pour les liens hypertextes dans XML,
* Xpointer/Xfragment pour pointer sur une partie d'un document XML
* ...
 Fabien > Oui, ce serait bien de faire une liste exhaustive
de ces modules en disant en une phrase ce qu'ils font (XPointer, XLink,
XPath, DTD, XML Schema, XSL, FO, XSLT, etc. et autres recommandations comme
DOM, SAX, etc.) Elodie > XML est issu de SGML (créé en 1980,
norme ISO en 1986). Il est créé en 1996, norme W3C en 1998.
Ces deux technologies ont à peu près la même puissance
mais une utilisation différente: SGML est utilisé pour des
documents techniques et beaucoup moins pour d'autres types de données
contrairement à XML. De plus, XML est une technologie plus régulière
et plus facile à utiliser.
Fabien > Oui, ce serait bien de faire une liste exhaustive
de ces modules en disant en une phrase ce qu'ils font (XPointer, XLink,
XPath, DTD, XML Schema, XSL, FO, XSLT, etc. et autres recommandations comme
DOM, SAX, etc.) Elodie > XML est issu de SGML (créé en 1980,
norme ISO en 1986). Il est créé en 1996, norme W3C en 1998.
Ces deux technologies ont à peu près la même puissance
mais une utilisation différente: SGML est utilisé pour des
documents techniques et beaucoup moins pour d'autres types de données
contrairement à XML. De plus, XML est une technologie plus régulière
et plus facile à utiliser.Entre temps, en 1990, HTML est créé. Son successeur XHTML est réalisé à partir des éléments du langage de HTML et de la syntaxe de XML.
Fabien > Ok, il faudrait faire un petit rappel historique
sur Internet, Le Web, etc. Elodie > De plus, XML est le fondement du web sémantique
et de RDF qui est un texte au format XML qui autorise la description des
ressources et l'application des métadonnées (recueil de musiques,
de photographies...) Fabien > Oui, on va creuser ce point: RDF est un langage
de description des ressources du Web, et il est muni d'une syntaxe XML i.e.
un langage de balise permettant de représenter des énoncés
RDF. Une traduction de
sa recommandation est en ligne.
Question qu'est-ce que RDFS ? Elodie > Pour finir, XML est libre de droit: il n'est pas
lié à un seul fournisseur, son utilisation est donc gratuite. Fabien > Yep ! C'est important si on veut assurer la pérennité
des données. Cela permet de changer de soft tout en gardant ses archives.
Je ne sais pas si vous avez regardé la
version française de "XML en 10 points" Marie > J'ai lu l'article
The Semantic Web - Scientific American, May 2001.
Je commence à écrire un résumé sur le
Web Sémantique.Problématique : le contenu du Web est traditionnellement fait pour être lu par des humains, pas par des ordinateurs. Or on veut que des programmes puissent extraire et manipuler les informations diffusées par le Web dont on a besoin. C'est ce que fait le Web sémantique, i.e. créer un environnement où les agents qui parcourent de pages en pages ce web, peuvent effectuer des tâches sophistiquées pour des utilisateurs.
Fabien > Ok la phrase classique pour décrire
la problématique c'est: Le Web est lisible par des humains et par
des machines ( human readable and machine readable) mais il n'est compréhensible
que pour les humains (human understandable). Le Web sémantique vise
à ajouter des annotations sémantiques, à propos des
ressources du Web, qui soient compréhensibles et exploitables par
des logiciels (machine understandable). Marie > Description du Web sémantique : Ce n'est pas
une page Web séparée mais une extension du Web actuel dans
lequel l'info a un sens bien défini.Pour fonctionner, les ordinateurs doivent avoir accès à des collections d'information et à des ensembles de règles d'inférence pour effectuer un raisonnement automatique. La Représentation des connaissances ("knowledge representation"), pour réaliser son potentiel, doit être liée à un système unique et global. Mais si tout le monde partage la même définition pour des concepts communs, cela devient vite étouffant et entraîne une augmentation de taille. Le système devient alors ingérable. Le challenge est donc de produire un langage qui permet aux règles en provenance de n'importe quelle "représentation du savoir" d'être exportée par le Web. La logique doit être assez puissante pour décrire des propriétés complexes d'objet mais pas trop pour que les agents ne s'égarent pas à avoir à considérer un paradoxe.
Fabien > Donc l'un des buts des fondations du Web sémantique
est de fournir un moyen simple d'échanger du sens. On verra aussi
qu'il cherche a être extensible. Marie > Deux technologies sont déjà en place
:- eXtensible Markup Langage (XML),
- Ressource Description Framework (RDF).
XML permet à chacun de créer ses propres balises qui entourent des pages Web ou des sections de texte. Les scripts ou les programmes peuvent alors utiliser ces balises de façon sophistiquée. En clair, XML permet aux utilisateurs d'ajouter des structures arbitraires à leurs documents sans rien dire de leur signification.
RDF exprime le sens de ces balises. C'est encodé sous la forme de triplés, un peu comme sujet-verbe-complément d'une phrase très simple. Dans RDF, un document fait des affirmations : des choses (personnes, pages web ou autres) ont des propriétés (est la soeur de, est l'auteur de ) avec une valeur (autre personne, autre page web). Sujets, verbes et compléments sont identifiés par URI, utilisés exactement comme un lien sur une page web. Cela permet à chacun de définir un nouveau concept, juste en définissant un URI pour lui sur le web.
Fabien > Ok, je reviens un peu sur le modèle de RDF
comme il est décrit dans
sa recommandation est en ligne.
"Les ressources sont identifiées par un identificateur de ressource. Un identificateur de ressource est une URI plus une ancre id optionnelle. Considérez comme un exemple simple, la phrase :
Ora Lassila est le créateur de la ressource http://www.w3.org/Home/Lassila.
Cette phrase est composée des parties suivantes :
Sujet (Ressource) http://www.w3.org/Home/Lassila Prédicat (Propriété) Créateur Objet (littéral) "Ora Lassila"
Elle peut être représentée par le diagramme suivant :
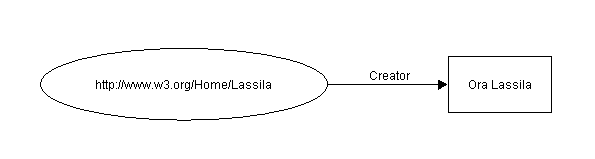
Le triplé - dans notre exemple c'était (http://www.w3.org/Home/Lassila, Créateur, "Ora Lassila") - est l'élément de base d'un énoncé RDF.
 En suite RDF a une syntaxe XML pour exprimer se modèle de triplet.
Dans notre exemple, cela donne:
En suite RDF a une syntaxe XML pour exprimer se modèle de triplet.
Dans notre exemple, cela donne:<rdf:RDF>Pour en savoir plus regardez RDF et RDFS.
<rdf:Description about="http://www.w3.org/Home/Lassila"
s:Créateur="Ora Lassila" />
</rdf:RDF>
Marie > Je ne comprends pas bien le passage suivant. Fabien > Dans le passage suivant, les auteurs expliquent que
rendre explicite la sémantique des annotations permet d'éviter
des difficultés dues à l'ambiguïté du langage. Ils
donnent l'exemple du mot 'adresse' qui peut désigner une adresse routière
(5 rue du général machin) ou purement postale (BP 87). Si les
systèmes ne sont pas capables de comprendre la différence il
se peut que lorsque vous commandez des pizzas elles soient livrées
à votre boîte postale (c'est sympa pour les employés de
la poste) parce que votre système a donné cette adresse au
système du livreur de pizzas. Le fait de définir un concept
et de lui donner un identificateur unique (URI) permet à deux systèmes
de s'assurer qu'ils parlent de la même chose (ex. le système
du livreur de Pizza veut votre adresse routière personnelle et utilise
un URI qui définit cette notion de façon à lever l'ambiguïté).
La structure permettant de définir des concepts et leur relation est
un Schéma RDF. Ce schéma est décrit à l'aide de
primitives donnée par RDF Schema (RDFS). Les schémas RDF sont
une façon de coder une ontologie. Le paragraphe suivant dans l'article
explique justement la notion d'ontologie. Comme cette notion n'est pas évidente,
voici en plus un document ( P1
P2
P3
P4
)qui explique la notion d'ontologie, il est extrait du
livre de mon équipe.{kind=link}
{kind=link}
{kind=link}
{kind=link} Elodie > Brève histoire du World Wide Web (WWW) : Si le World Wide
Web (WWW) est connu de tout le monde depuis seulement quelques années,
il faut faire remonter son origine à la fin de la deuxième
guerre mondiale.
Elodie > Brève histoire du World Wide Web (WWW) : Si le World Wide
Web (WWW) est connu de tout le monde depuis seulement quelques années,
il faut faire remonter son origine à la fin de la deuxième
guerre mondiale.C'est en effet en 1945 qu'apparaît l'idée de lien hypertexte... dans les microfilms ! Des
scientifiques américains ont élaboré un étrange boitier (subtile mélange d'optique, d'électronique et de mécanique), le Memex, capable de créer des liens entre plusieurs microfilms.
Pendant 15 ans environ, aucune amélioration n'a été noté en matière d'hypertexte. C'est dans les années 60 que Doug Engelbart met au point un prototype , le "oNLine System" (NLS), qui est capable de parcourir et créer des pages hypertexte, d'écrire des mails, etc. Chose remarquable, surtout, c'est qu'il en a profité pour inventer la souris.
En 1965, Ted Nelson invente le mot hypertexte.
Fabien > Ok, là cela vaut le coup de parler un peu plus de lui
et du projet Xanadu car il a inventé des concepts qui sont très
proches de ce qui se fait en XML maintenant (ex. la transclusion permettant
de composer un document virtuel en décrivant les morceaux d'autres
documents qu'il inclut) Elodie > Le tournant de l'hypertexte et du web est finalement pris en
1980, où Tim Berners-Lee écrit un programme façon porte-documents,
"Enquire-Within-Upon-Everything", qui permet de créer des liens entre
n'importe quels documents. Chaque document est en fait muni d'un titre, type
et d'une liste de lien. Simple, mais efficace.Mars 1989 : Tim Berners-Lee écrit un document à destination du CERN (là où il travaille à l'époque) qui vise à améliorer le management du système d'information. Ce document, c'est le "Information Management: A Proposal", le document qui servira de base un an plus tard à l'établissement du web tel que nous le connaissons aujourd'hui.
En septembre 1990, Tim écrit un document qui décrit complètement le fonctionnement d'un système hypertexte. Un mois après, Tim écrit le premier navigateur web (qui fonctionnait alors sur station NexT), et le nomme (tout
comme le projet) "World Wide Web". Le 12 novembre 1990, Tim Berners-Lee et Robert Cailliau reformulent le projet hypertexte du départ. Le web est né, et à Noel 1990, on peut surfer sur le net.
Fabien > Yep ! Plusieurs petits trucs sont à souligner car si on
arrive à ce résultat c'est parce que toutes les conditions
sont réunies : on a exploré la notion d'hypertexte et de lien
de navigation (par exemple on peut parler du logiciel hypercard distribué
sur Mac), on a un environnement de développement graphique assez génial
(NeXT Step), on a une bonne couche réseau sur laquelle construire.
Notons que le premier navigateur de Tim était beaucoup plus puissant
que ce que l'on en a gardé dans le début des années
90 (en particulier il avait des capacités d'édition) Elodie > Est il nécessaire de parler de ARPANET dans la histoire
d'Internet? Fabien > C'est bien de dire qu'il a existé, mais contrairement
à ce que disent tous les magazines ce n'est pas l'unique ancêtre
de l'Internet. Tu peux regarder le cours sur l'histoire du Web et de l'Internet
que je donnais en MASS1. Cela te donnera de quoi étoffer certains
points et tu y trouvera un passage (en 1967) qui discute des ancêtres
de l'Internet.A ce propos je fais une distinction entre internet (la technologie d'interconnexion des réseaux et des machines qui peut être utilisée à l'échelle d'un intranet dans une organisation) et Internet (une instance d'un tel réseau qui utilise cette technologie pour une interconnexion à l'échelle mondiale).
Elodie > Bibliographie de Tim Berners-LeeTim Berners-Lee est né à Londres, le 8 juin 1955. Il fait des études à l'Université d'Oxford de 1973 à 1976. Il a profité de ses années d'études pour fabriquer son premier ordinateur sur base d'un M6800 et d'une vieille télévision.
Il travaille, de 1976 à 1980 pour diverses entreprises anglaises. En 1980, alors qu'il travaille comme consultant extérieur au CERN à Genève, il écrit un premier logiciel de stockage d'informations utilisant des associations
aléatoires. Ce projet qu'il avait nommé "Enquire" est abandonné, mais c'est lui qui servira de base plus tard au World Wide Web.
De 1981 à 1984, il travaille dans une entreprise sur les systèmes distribués à temps réel. En 1984, il retourne au CERN.
En 1989, sur base de son vieux système "Enquire", il propose un projet d'hypertexte qu'il appelle "World Wide Web" (il avait pensé aussi à l'appeler "Information Mesh" (maillage d'informations), "Mine of Information", ou encore "Information Mine" (mine d'informations)). Le but est de rassembler les connaissances de tous dans une "toile" de documents hypertexte. Il conçoit alors en octobre 1990 le premier serveur HTTP et le premier client Web (déjà WYSIWYG sur station NeXT). Son logiciel est distribué sur Internet durant l'été 1991.
Pendant 3 ans, de 1991 à 1993, il continue à développer le web, et apporte les notions désormais bien connues d' "internet_uri.php3" , HTTP et HTML
Fabien > Là cela vaut le coût de donner des
définitions de ces notions car elles sont à la base. Elodie > Depuis, Tim est parti aux Etats-Unis où il
dirige la 3Com (Computer Communication Compatibility) au Laboratory for Computer
Science (LCS) du Massachusetts Institute of Technology (MIT). Il dirige également
la W3C (World Wide Web Consortium) dont le but est d'amener le Web à
son potentiel maximum. Fabien > Quelle est la différence entre un fichier "bien
formé" et un fichier "valide" de XML ? Elodie > Un document est dit:- "well-formed" / "bien formé" s'il respecte la syntaxe XML
- "valid" / "valide" si en plus il respecte une grammaire (DTD)
DTD: Document Type Definition
La DTD:
- permet de contraindre la syntaxe d'un document
- est optionnelle
- peut-être incluse dans le document ou externe
Il n'y a pas de typage (expression régulière), ni d'héritage(pas de sous-classes des DTDs). Si une DTD est définie, tout le document doit y obéir sinon il y a pas d'erreur.
Fabien > Heuu... Je dirais plutôt que si un document a une
DTD associée, il doit respecter cette DTD sinon il y a erreur
: le document n'est pas valide. Elodie > Les problèmes et les dangers de la DTD:- formalisme complexe
- peu puissant
- optionnelle
- pas en syntaxe XML
Fabien > Ok (sauf que pour moi l'aspect optionnel n'est pas un
problème), et maintenant avec XML Schema
, (qui va remplacer les DTDs) la validation se fera par rapport à
un schéma. Pour en savoir plus regardez les spec de XML Schema: "
XML Schema Part 0: Primer is a non-normative document intended to provide
an easily readable description of the XML Schema facilities, and is oriented
towards quickly understanding how to create schemas using the XML Schema
language. XML Schema Part 1: Structures and XML Schema Part 2: Datatypes
provide the complete normative description of the XML Schema language."XML Schema part 0/
XML Schema part 1/
XML Schema part 2/
Elodie > XPath : XML Path langage.Ce langage a été créer pour combler les lacunes du langage HTML à propos des HyperLiens. En effet, les liens HTML ont de nombreux problèmes:
* la modification du document source: <a href="doc#section"></a>
* la modification du document de destination: <a name="section"/>
* liens uniques mono-directionnels
* il n'existe pas de pointeurs sur zone
Fabien > Heu... là je pense que c'est trop limité
comme justification si on regarde la spec
, je pense qu'elle se justifie par une problématique plus large :
" XPath is the result of an effort to provide a common syntax and semantics
for functionality shared between XSL Transformations and XPointer. The primary
purpose of XPath is to address parts of an XML document. In support of this
primary purpose, it also provides basic facilities for manipulation of strings,
numbers and booleans. XPath uses a compact, non-XML syntax to facilitate
use of XPath within URIs and XML attribute values. XPath operates on the
abstract, logical structure of an XML document, rather than its surface syntax.
XPath gets its name from its use of a path notation as in URLs for navigating
through the hierarchical structure of an XML document. In addition to its
use for addressing, XPath is also designed so that it has a natural subset
that can be used for matching (testing whether or not a node matches a pattern);
this use of XPath is described in XSLT. " Elodie > Voici les 3 normes qui ont été créées:* XPath est un langage pour décrire des fragments d'un document.
* XPointer spécifie des "cibles" via XPath.
* XLink décrit des liens entre des XPointers.
XPath est une chaîne spécifiant la sélection d'un ensemble de n�uds dans un document.
En conclusion:
XPath est trés puissant, un vrai langage de requète, mais il est:
* difficile à maîtriser, car concis
* trés difficile à implémenter efficacement
Elodie > XSL : eXtensible Stylesheet Langage.XSL est l'héritier de DSSSL (scheme manipulant de SGML). La communauté DSSSL souhaitait un langage permettant le traitement des sources pour imprimer différentes versions d'un document.
XSL est un langage de réécriture pour XML subdivisé en:
* XPath: localisation d'un document ou d'une partie de document
* XSLT: restructuration du document
* XSL-FO: mise en forme du document
C'est un langage de manipulation d'arbres qui change un dialecte XML en un autre.
* XSLT analyse un document XML, trouve les noeuds sur l'arbre en
mémoire(DOM) correspondant aux règles XSL et génère un arbre DOM à
partir des instructions de ces règles et "imprime" le XML résultant.
* XSL-FO est un langage pour le formatage et la présentation de documents mais il est peu utilisé, peu développé et ses besoins sont mal définis.(PDF? WEB? SVG?)
Fabien > L'idée derrière XSL & XML s'était de
faire pour les documents ce que JAVA cherche à faire pour les programmes.
JAVA c'est "Ecrivez votre programme une fois et faites le tourner partout
(quels que soient la machine, le système d'exploitation, etc.)" XSL &
XML c'est "Ecrivez votre document une fois et publiez partout (quels que soient
le support - CDROM, Livre, transparents, etc.-, le format -HTML, PDF, etc.-). Elodie > SAX & DOMSAX : Simple API for XML
En 1997,chaque parseur XML possède sa propre interface. SAX 1.0 apparaît
en mai 1998 comme une tentative d'unifier ces interfaces. A l'origine
basé sur Java il est aujourd'hui basé sur Perl, Python, C, C++,etc...
C'est un modèle à événements qui découpe en lexèmes et émet des
événements. Le processus est rapide et léger car les documents ne sont
pas entièrement chargés en mémoire. De plus, il permet de traiter des
gigas de données avec peu de mémoire. Il lit séquentiellement les
documents et est de bas niveau (convient à tous usages, faible temps de
traitement).
DOM: Document Object Model
Il s'agit d'un arbre d'objets qui représente le document XML. Il est comparable à un arbre de syntaxe abstraite.
L'interface "package org.w3c.dom" est un jeu d'interfaces normalisées
par le W3C. Il existe plusieurs niveaux:
* DOM Level 1: XML + HTML
* DOM Level 2: org.w3c.dom.html
* DOM Level 3: en préparation...
Fabien > J'ai mis SAX et DOM ensemble car ce sont les deux grandes
API offertes au programmeur pour attaquer du XML: soit une version événementielle
(SAX) qui parse le document XML et génère des événements
décrivant ce qu'il rencontre ; soit une version créant
une structure de donnée complète en mémoire (un document
XML est une forêt) et permettant de manipuler cette structure (DOM) Fabien > Au fait, j'ai trouvé sur Webopaedia
(très bon dico de l'info) la définition de l'acronyme : SGML
"Abbreviation of Standard Generalized Markup Language, a system for organizing and tagging elements of a document. SGML was developed and standardized by the International Organization for Standards (ISO) in 1986. SGML itself does not specify any particular formatting; rather, it specifies the rules for tagging elements. These tags can then be interpreted to format elements in different ways.
SGML is used widely to manage large documents that are subject to frequent revisions and need to be printed in different formats. Because it is a large and complex system, it is not yet widely used on personal computers.
However, the growth of Internet, and especially the World Wide Web, is creating renewed interest in SGML because the World Wide Web uses HTML, which is one way of defining and interpreting tags according to SGML rules."