ACM Multimedia 95 - Electronic Proceedings
November 5-9, 1995
San Francisco, California
Automating the Creation of a Digital Video Library
- Michael A. Smith
-
- Smith Hall
- Carnegie Mellon University
- Pittsburgh, PA 15213
- (412) 268-8424
- msmith@cs.cmu.edu
-
http://www.ius.cs.cmu.edu/~msmith
- Michael G. Christel
- Software Engineering Institute
- Pittsburgh, PA 15213
- (412) 268-7799
- mac@sei.cmu.edu
-
http://www.cs.cmu.edu/afs/andrew/usr/mc6u/www/
The InformediaTM Project has established a large on-line
digital video library, incorporating video assets from WQED/Pittsburgh.
The project is creating intelligent, automatic mechanisms for populating
the library and allowing for its full-content and knowledge-based search
and segment retrieval. An example of the display environment for the system
is shown in Figure 1. The
library retrieval system can effectively process natural queries and deliver
relevant video data in a compact, subject-specific format, based on
information embedded with the video during library creation. Through the
combined efforts of Carnegie Mellon's speech, image and natural language
processing groups, this system provides a robust tool for utilizing
all modes of video data [Christel95]. The Informedia Project uses the
Sphinx-II speech recognition system to transcribe narratives
and dialogues automatically [Hwang94].
The resulting transcript is then processed through methods of natural
language understanding to extract subjective descriptions and mark potential
segment boundaries where significant
semantic changes occur [Mauldin91]. Comparative
difference measures are used in processing the video to mark potential segment
boundaries. Images with small histogram disparity are considered to be
relatively equivalent. By detecting significant changes in the weighted
histogram of each successive frame, a sequence of images can be grouped
into a segment. This simple and robust method for segmentation is fast
and can detect 90% of the scene changes in video.
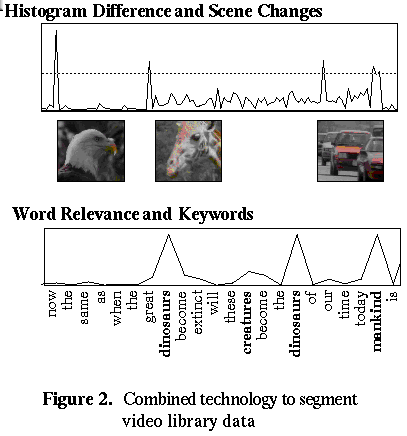
Segment breaks produced by image processing are examined along with the
boundaries identified by the natural language processing of the transcript,
and an improved set of segment boundaries are heuristically derived to
partition the video library into sets of segments,
or "video paragraphs" [Hauptmann95]. The technology for this process is
shown in Figure 2.
An initial use of the combined technology is the development of the video
skim [Smith95]. By only displaying significant regions,
a short synopsis of the
video paragraph can be used as a preview for the actual segment. Compression
rates as high as 20:1 make it possible to "skim" large amounts of data in a
short time. A transcript is created by Sphinx-II from the audio track.
Keywords are extracted from this transcript based on word frequency/inverse
document frequency weightings [Mauldin91],
and separated from the audio track [Hauptmann95].
Significant image frames are identified through the use of various image
understanding techniques which interpret camera motion and object presence.
At regular speed, the identified subset of image and audio information is
combined to produce the skim with only a small number of selected regions
displayed. Figure 3 shows an
example of a video region isolated during skim creation from
the "Destruction of Species" documentary (WQED/Pittsburgh).
The demonstration shows the exploration of a digital video library
consisting of various material from WQED's scientific video collection.
Video paragraphing and alternate representations of the video such as text
transcripts, image overviews, and skims allow the user of the library to
retrieve relevant information more efficiently and easily.
The system utilizes the automated methods of image and audio segmentation
for creating the video paragraphs. Image processing is used to create
alternate representations for a video paragraph, from a single
representative image or "poster frame" to a family of poster frames or
"paragraph filmstrip" to a skim with a temporal component. Speech
processing is used to create and augment these representations as well,
from synchronizing text transcripts to the video to assisting in the
creation of skims. At present, many of the other components used in the
system are created in a computer assisted manner. Future library creation
will be streamlined through improved integration of image and natural
language processing for automated scene characterization and speech
recognition for automated transcript generation. Forthcoming improvements
will also include access to data transmitted by high speed networks, and
empirically validated, age-appropriate user interfaces with multimodal
query support.
- [Christel95]
-
Christel, M., Stevens, S., Kanade, T., Mauldin, M., Reddy, R., Wactlar, H.,
"Techniques for the Creation and Exploration of Digital Video Libraries,"
to appear as Chapter 17 in Multimedia Tools and Applications
(Volume 2), B. Furht, ed. Boston, MA: Kluwer Academic Publishers, 1995.
- [Hauptmann95]
-
Hauptmann, A., and Smith, M.,
"Text, Speech, and Vision for Video Segmentation: The Informedia
TM Project,"
AAAI Fall 1995 Symposium on Computational Models for Integrating
Language and Vision, in press.
- [Hwang94]
-
Hwang, M., Rosenfeld, R., Thayer, E., Mosur, R., Chase, L., Weide, R.,
Huang, X., Alleva, F.,
"Improving Speech Recognition Performance via Phone-Dependent VQ Code-books
and Adaptive Language Models in SPHINX-II,"
ICASSP-94, vol. I, pp. 549-552.
- [Mauldin91]
-
Mauldin, M.,
"Information Retrieval by Text Skimming,"
PhD Thesis, Carnegie Mellon University. August 1989. Revised edition
published as
"Conceptual Information Retrieval: A Case Study in Adaptive
Partial Parsing," Kluwer Press, Sept. 1991.
- [Smith95]
-
Smith, M., Kanade, T.,
"Video Skimming for Quick Browsing Based on Audio and Image
Characterization,"
Carnegie Mellon University technical report CMU-CS-95-186, July 1995.
Also submitted to PAMI Journal (Pattern Analysis and Machine
Intelligence), 1995.
{kind=link}