int max = Integer.MIN_VALUE;
for (int i=0; i<a.length; i++)
if (a[i] > max)
max = a[i];
We can easily examine the machine language instructions that Java produces for this code by using the debugger. If we specify Mixed on the bottom control of its window, Java shows us the Java code interspersed with the machine language instructions.

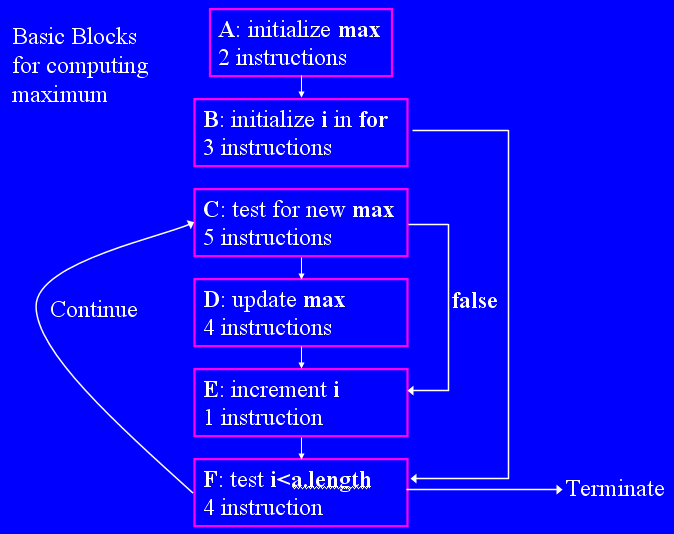
Below, I have duplicated this information, but reformatted it to be more understandable. I have put comments at the end of every line and put blank lines between what compiler folks call basic blocks.
int max = Integer.MIN_VALUE; : A 051E6B3D: 1209 ldc (#9)051E6B3F: 3D istore_2 for (int i=0; i<a.length; i++) 051E6B40: 04 iconst_0 //get 0 : B 051E6B41: 3E istore_3 // store it in i 051E6B42: A70011 goto 0x051E6B53 //go to test near bottom if (a[i] > max) 051E6B45: 2B aload_1 //get a's base address : C 051E6B46: 1D iload_3 // get i 051E6B47: 2E iaload // get a[i] 051E6B48: 1C iload_2 //get max 051E6B49: A40007 if_icmple 0x051E6B50 //go to test near bottom if <= max = a[i]; 051E6B4C: 2B aload_1 //get a's base address : D 051E6B4D: 1D iload_3 // get i 051E6B4E: 2E iaload // get a[i] 051E6B4F: 3D istore_2 //store it in max 051E6B50: 840301 iinc 3 1 //increment i : E 051E6B53: 1D iload_3 //get i : F 051E6B54: 2B aload_1 //get a's 051E6B55: BE arraylength // length 051E6B56: A1FFEF if_icmplt 0x051E6B45 //go to if above if <
Each basic block can be entered only at the top and exited only at the bottom. once a basic block is entered, all its instructions are executed. There may be multiple ways to enter and exit blocks. This code is a bit tortuous to read and hand simulate, but you can trace through it. An easier way to visualize the code in these basics blocks is as a graph, which I will annotate with all the information needed to understand computing instruction counts from it.