
| Introduction |
This lecture covers the details of how the collection classes in the standard
Java library (all in the java.util package) are defined, implemented,
and used.
Recall that the ordered collections, while modelled on these collection
classes, are not really defined in Java (I wrote them and put them in my
edu.cmu.cs.pattis.cs151xx package).
There is a bit more structure here in Java's collection classes: they are categorized according to the interfaces they implement: List, Set, and Map; both the List and Set interfaces extend the superinterface Collection, while Map extends no interface but is extended by the subinterface OrderedMap. We will examine these interfaces, as well as various abstract classes that partially implement them, and which are ultimately extended to create concrete classes for these interfaces (using arrays). When used together properly, all these collections (and the ordered ones discussed previously) provide a powerful library with which to define and manipulate complex data structures. Once you are familiar with the process of using collection classes, it is easy to translate a problem into a representation that is a combination of collection classes, and an algorithm for solving the problem into a combination of operations (often involving iterators) on this data structure. In fact, we have previous described collection classes as a capstone for the first half of the semester: they involve interfaces, exceptions, classes, abstract classes, inheritance, iterators, and analysis of algorithms. The programming assignment accompanying these lectures is a suite of programs, each solving an interesting problem, and doing so compactly with collection classes. By solving these problems, you will become familar with the way collection classes are used in Java. In fact, we will use one of these programs as our mid-term programming exam, and we will see similar (but simpler) collection class problems (using them, not implementing them) on the final programming exam, given coursewide to all 15-111 and 15-200 students. |
| Design of the Collection Classes | In this section we will examine in detail the common design for all classes that implement the Collection interface. We will examine the relationship between this interface and the abstract class that implements it. In the following sections we will study furthr interfaces, abstract classes, and finally the concrete classes that implement this interface. Throughout our study, these features naturally arrange themselves into three vertical levels in a hierarchy. The following legend explains the three levels and some of the notation used. |
|
For lists and sets, we will explore the following hierarchy of interfaces, abstract classes, and concrete classes. Note that some concrete List classes also implement the RandomAcesss interface; and some concrete Set classes also implement the SortedSet interface. |

|
These interfaces are implemented by abstract classes (two or three levels,
which supply some but not all of the needed methods) which are extended by
concrete classes that inherit some behvaior from the abstract classes and
concretely define all their abstract methods.
Recall that concrete subclasses automatically implement the interfaces that
their superclasses implement, and [abstract]classes can implement more
than one interface (but can extend only one superclass); again, this is a
fundamental difference between interfaces and classes.
In the next two sections, we will examine the Javadoc of the Collection interface and AbstractCollection abstract class that implements it |
| Interfaces | The methods specified in the Collection interface are summarized in the following Javadoc (you can read the full Javadoc online, using the Javadoc of Course API link). The semantics of most methods should be somewhat intuitive. Primarily, objects can be added and removed from a collection, and checked for membership. Methods like add, contains, and remove which have Object parameters, have counterparts addAll, containsAll, and removeAll which use another Collection as a parameter, adding, removing, or checking for containment each of the values in the parameter. Iterators will also play an important role in classes implementing this interface. |

|
Note that this interface knows nothing about the OrderedCollection
interface, because I wrote the OrderedCollection interface long
after this one.
On the other hand, my OrderedCollection interface does include methods
that process objects constructed from classes implementing the
Collection interface, again because I wrote the
OrderedCollection interface long after this one was finalized by
Sun Microsystems.
Fundamentally, the add method adds an object to the collection. The addAll method iterates through every object in its parameter collection, and uses add to add each one to this collection. The contains and containsAll, and the remove and removeAll pairs of methods work similarly. Note that the "add" and "remove" methods also return boolean values, indicating whether the required element was actually added/removed from the collection (e.g., no duplicates are added to a set). The size method returns the number of elements in the collection, and the clear method empties the collection (its size becomes 0, at which point the isEmpty methods returns true). The iterator method returns an iterator whose next method iterates over the collection; note that unlike ordered collections, there is no inherent order (e.g., FIFO, LIFO) that you can expect the iterator to use. Finally, there are various to... methods that return this collection as an array and String. Now we will examine an abstract class that implements a large number of these methods, leaving another abstract subclass and then the concrete subclass to implement/override the rest. Remember that there are 15 methods specified in this interface. |
| Abstract Classes |
Now we will examine the Javadoc of an abstract class that implement the
interface specified above (although some of its methods are abstract).
The Collection interface specified 15 methods.
The AbstractCollection class specifies one protected constructor
and 14 methods; it doesn't define equals or hashCode which are
inherited from the Object class that this one implicitly extends
(and overridden is the abstract subclass in the next section); it adds the
specification of a toString method (which, of course, all classes
inherit from their superclass, even if it is only Object).
Of these 14 (=15-2+1) methods, all but two iterator and size are defined here (these two are defined to be abstract), although operations like add, contains, and remove are implemented just to throw UnsupportedOperationException. Yet the addAll, containsAll, and removeAll methods are completely written here, using the promised iterator and eventually-working add, contains, and remove methods: they iterate through the parameter collection, calling the appropriate method for each element. Here is the Javadoc of AbstractCollection (because of size constraints, it appears in a smaller font). |

| All the to... methods (toArray and toString) can be implemented by the iterator as well, which is promised to be defined in the concrete subclass. |
| Design of the List Classes | In this section we will start examining in detail the design for one class that ultimately implements the Collection interface: list, which also implements the List subinterface. We will examine the overall relationships among these interfaces, the abstract classes that implement them, and the concrete classes that extend these abstract classes. |
| List Interfaces |
The List subinterface repeats all the methods in the Collection interface and adds many methods that apply to collections that are sequences of elements: the elements are said to occupy certain indexes, in a sequence, similarly to arrays. Operations on sequences preserve the relative order of the elements (often shifing blocks of elements when new ones are added or removed at some index). The methods specified in the List interface are summarized in the following Javadoc; in the case of respecified methods (say add) the comments explain how they apply to lists: for add, "Appends the specified element to the end of this list." The semantics of most methods should be somewhat intuitive for programmers familiar with arrays. Primarily, the extension relates to performing operations whose prototypes refer to int indexes. The get and set methods implement the fundamenal operations that we can perform on a sequence of values: get the value at index i and change the values at index i. |


|
Here, the add method is further defined to add the element as the last
one in the list; in addition, it is overloaded to add a value at a certain
index, shifting all the elements at that index and beyond, up by one
index (like someone cutting into a line), keeping their relative order.
The get method returns the value stored at a specified index; for a
list l, l.get(i) is equivalent to a[i] (appearing in an
expression) for array a.
The indexOf method performs a search (from lowest to highest index) and
returns the first index that is equal to (.equals, NOT ==)
the parameter Object (or -1 if none are equal).
The remove method is further defined to shift every element after the
removed one down by one index (as when someone is taken out of a line),
keeping their relative order; in addition, it is overloaded to remove a
value at a certain index: in fact l.remove(o); is equivalent to
l.remove(l.indexOf(o)); (although it probably runs a bit faster).
The set method stores an element at a specified index (removing the
previous element stored there); for a list l, l.set(i,e); is
equivalent to a[i]=e; for array a.
Finally, the sublist method allows us to construct a new list from
a selected subsequence of indexes (similar to what substring does
in the String class).
The List interface also specifies two overloaded methods named listIterator that return special ListIterator objects: one for the whole list, one for all values at, and after, a specified index. Such iterators extend the standard ones in two main dimensions: we can iterate both forwards and backwards in a list (interleaving forward and backward movement) and we can ask for the index of the next (or previous) element. The methods specified in the ListIterator interface are summarized in the following Javadoc. |

| Pragmatically, I have never used a ListIterator (standard iterators have always been powerful enough for what I want to do). But some methods are implemented below in the AbstractList class using this special type of iterator. |
| List Abstract Classes | The AbstractList class extends AbstractCollection and also implements the List interface, which specifies extra methods. Here is the Javadoc of AbstractList (because of size constraints, it appears in a smaller font). |

This abstract class provides concrete implementations for all of the methods
using indexes, although many are implemented by just throwing
UnsupportedOperationException.
Others, such as equals or indexOf, are implemented by using a
ListIterator.
Such implementations run slowly, and are typically overridden in the concrete
classes extending this one.
For example, the AbstractList class defines equals as follows.
All equals methods look similar to this one.
Two lists are equal if their sequence of values is the same.
Notice the use of .equals NOT ==.
public boolean equals(Object o)
{
if (o == this) //== objects are .equals
return true;
if (!(o instanceof List)) //o must impelement List too
return false;
ListIterator e1 = listIterator();
ListIterator e2 = ((List) o).listIterator();
while(e1.hasNext() && e2.hasNext()) {
Object o1 = e1.next();
Object o2 = e2.next();
if (!(o1==null ? o2==null : o1.equals(o2)))
return false;
}
return !(e1.hasNext() || e2.hasNext()); //both done at the same time?
}
Likewise, the AbstractList class defines indexOf as follows.
public int indexOf(Object o)
{
ListIterator e = listIterator();
if (o==null) { //Determine whether to use
while (e.hasNext()) // == for comparing agains null
if (e.next()==null)
return e.previousIndex();
}else{
while (e.hasNext()) // .equals for non null
if (o.equals(e.next()))
return e.previousIndex();
}
return -1;
}
Here is a case where a ListIterator is actually useful, because of its previousIndex method. Note that this method returns e.previousIndex() because it has already tested (thus it has already bypassed) the index that equals o. Next we will examine the Javadoc and implementation a concrete class that extends AbstractList. |
| List Concrete Classes | Now we will examine the Javadoc of a concrete class that extends AbstractList. The ArrayList class is implemented with an array backing the list (we will examine the other implementation, LinkedStack, in detail after we discuss linked lists). The ArrayList class defines 3 public constructors; it overrides many inherited methods that throw UnsupportedOperationException and others that were inefficient; and, it defines two new methods, not mentioned previously: ensureCapacity and trimToSize, which relate only to array implementations of list (not to lists theselves). Here is the Javadoc of ArrayList (because of size constraints, it appears in a smaller font). |


|
Note that we can construct an empty list (with some small backing array),
an empty list with a backing array whose length starts at some initial
capacity, and a non-empty list with values added from a Colection.
We can call ensureCapacity to increase the length of the backing array
to any value, or trimToLength to decrease it to the mininmum
length needed to store all its current values.
The other methods here just do what we expect. There is a clone method which does some interesting things that we will discuss towards the end of the semester. For now, if we want to make a copy of a list l (or any collection or ordered collection), we will use it in a constructor: List l2 = new ArrayList(l) will create a copy of list l such that l.equals(l2) returns true. Actually these two lists are represented by separate objects, but these separate objects share all the element objects between them: if an object is mutated through one list, it appears mutated in the other list as well. True copying, with the more complicated clone method does not have this mutate/sharing behavior. So, the structure leading from the Collection interface to the ArrayList concrete classes involve all sorts of interesting inheritance of interfaces, abstract, and concrete methods. Again, we can USE all these classes without knowing this information, mostly by examining just the List interface, and the constuctors for this class, and knowing that it implements its methods efficiently.
Finally, note that the toString method for a list returns a
String with all the list's values in their correct sequence
(ordred by increasing indexes) enclosed in brackets, separated by commas:
e.g.,
Now we discuss the iterators for this class and then the performance of all its methods in terms of big O notation, where N is typically the number of elements stored in the collection. |
| Iterators for List |
Unlike ordered collections, sometimes it is useful to remove elements from a
collection.
Thus, the remove methods for list iterators actually remove the element
just returned by next.
Here is an example that illustrates how to remove all the odd elements in a
list l of Integers.
for (Iterator i = l.iterator(); i.hasNext(); ) {
Integer next = (Integer)i.next();
if (next.intVal() % 2 == 1)
i.remove();
}
When the remove method is called on an iterator, it removes the
element just iterated over; so at least one call to next must have
been made before remove.
This means that to remove the last value in a list, we must call remove
after calling next, once hasNext returns false
Notice that the following two code fragments both print all the elements from
any List l in sequential order: the first used an iterator, the last
uses the individual indexes.
for (Iterator i = l.iterator(); i. hasNext(); )
System.out.println(i.next());
for (int i = 0; i<l.size(); i++; )
System.out.println(l.get(i));
|
| Complexity Classes for List |
The following table summarizes the complexity classes of all the methods
in the classes that implement the List interface.
In the table below * means amortized complexity. That is, when we add a value in an array, most of the time we perform some constant number of operations, independent of the size of the array. But every so often, we must construct a new array object with double the length, and then copy all the array's current elements into it. If we pretended that each add did more operations (but still a constant number, just a bigger constant), that number would dominate the actual number of operations needed for all the doubling/copying. In the table below ** means that the parameter to the method is some collection (or array) storing M elements.
|
| Using backing arrays, and length doubling (actually, most "empty" collections start with an initial capacity of 10 and increase by 1.5 times), the array length for storing N elements is never more than 1.5N words of memory; using linked lists, storing N elements always requires 2N words of memory. So array implementations of list always are better, in storage capacity, than linked implementations. |
| Array vs. ArrayList |
So far, we have seen that ArrayList uses a backing array to store all
its data.
So, is it better to just write our own arrays or construct an ArrayList
object?
Here are the major points of contention.
Recall that arrays can be declared to store any type, including primitives too (not just Object, which is what all collection classes stores), which means by using arrays we can cut down on casting. Also, the syntax to access arrays while special, is often simpler to read, write and understand. For an example that combines both advantages: a[i]++ vs. l.set(i, new Integer( ((Integer)l.get(i)).intValue()+1)); Are these inherent problems? No. In Java 1.5 we will be able to write the latter using generic collection classes and autoboxing (impliicit use of wrapper classes around primitives) as l.set(i, l.get(i)+1);, although this still is harder to read than a[i]++; or even a[i] = a[i]+1 With the ArrayList collection class (in fact, any implementation of List), we get lots of functionality for free: as a primary example, don't needed to write code that manipulates the backing array's length: we just add elements and this method increases the array's length if necessary. Also, we can use methods that correctly check whether an element is contained in the collection (or find its index) and remove an element from the collection; they are immediately avaliable and we don't have to write them. In addition, if other collections are needed (ones that cannot be easily replaced by an array) all the collection classes operate nicely together: e.g., to put all values of a list l into a set we can write just Set s = new HashSet(l); When we study the Collections class (not the Collection interface: notice the plural in the former), we will discover some useful decorators for collection classes that let us restrict their behvaior in intersting ways: unmodifiablity and synchronization among threads. Overall, using collections instead of arrays is probably a good thing, especially if the type of values stored is not a primitive. Finally, it is difficult for programmers who have used arrays so much to switch to using collection classes. Often, they fail to take advantage of the advanced methods available, and still write code that looks like array processing code (which is often much more complicated). Attempt this transition now. |
| Design of the Set Classes | In this section we will start examining in detail the design for another class that ultimately implements the Collection interface: set, which also implements the Set subinterface (and may implement the SortedSet subsubinterface). We will examine the overall relationships among these interfaces, the abstract classes that implement them, and the concrete classes that extend these abstract classes. |
| Set Interfaces |
The Set subinterface repeats all the methods in the Collection interface and adds no new methods The methods specified in the Set interface are summarized in the following Javadoc; in the case of respecified methods (say add) the comments explain how they apply to lists: for add "Adds the specified element to this set if it is not already present." This is as fundamental property of a set: that it stores no duplicate elements. Also, because of the way sets are stored, it is imperative that you do not change the state of an object once you have stored it in a set. As the Javadoc says: Note: Great care must be exercised if mutable objects are used as set elements. The behavior of a set is not specified if the value of an object is changed in a manner that affects equals comparisons while the object is an element in the set. A special case of this prohibition is that it is not permissible for a set to contain itself as an element. If you want to change an object in a set, you must first remove it, then make the change, and then re-add it to the set. Note that this process whole process is still O(1), because remove and add are. This restriction relates to hashing, which we will cover in the next lecture (and further explore this restriction). The methods specified in the Set interface are summarized in the following Javadoc. |

|
Here, the add method is further defined to add the element to the set
only if it is not already there, so the boolean value it returns is
the opposite of contains: if add returns true, it means
that the element was not originally contained in the set (but now is).
The remove method likewise returns the same boolean value as
contains: if remove returns true, it means
that the element was contained in the set (but now isn't).
The SortedSet interface extends Set with operations based on some ordering of the elements in a set; when constructing an object from a class that implements SortedSet (e.g., TreeSet), we must supply an argument constructed from a class that implements Comparator that specifies this ordering (just as we do for priority queues). Then, the SortedSet performs these extra methods based on this Comparator. The methods specified in the SortedSet interface are summarized in the following Javadoc. |

Pragmatically, I have never used TreeSet (nor any other class that
implements SortedSet); the standard Set interface has always
been powerful enough for what I want to do, and often its operations are
more efficient.
If I do want to "order" a set of values, it is often to print them out in
order: to do this I write code similar to the following.
Object[] values = s.toArray();
Arrays.sort(values, some-comparator-object);
for (int i=0, length=values.length; i<length; i++)
System.out.println(values[i]);
I saw this inner declaration of length in some code I read
recently; it more verbose but more efficient than testing the condition
i<values.length (use the Metrowerks debugger to see the Java
code generated for each) although to me, the compiler should perform
this optimzation for us automatically, and some in fact might do so.
|
| Set Abstract Classes | The AbstractSet class extends AbstractCollection and implements the Set interface. It overrides the equals and hashCode methods inherited from Object, and it also overrides the removeAll method inherited from the AbstractCollection (it can improve its peformance knowing something that is true about sets but not collections in general). Here is the Javadoc of AbstractSet, which is very short. |
| Set Concrete Classes | Now we will examine the Javadoc of a concrete class that extends AbstractSet. The HashSet class is implemented with an hash table backing the set (we will examine hash tables, which typically are themselves backed by arrays, in the next lecture). The HashSet class defines 4 public constructors; it overrides some inherited methods that throw UnsupportedOperationException and others that were inefficient. From the constructor, you can read that hash tables have "initial sizes" and "load factors"; you will need to use only the first two constructors this semester; the other parameters relate to fine-tuning the efficiency of the underlying hash table, and is a topic you will study in 15-211. Here is the Javadoc of HashSet (because of size constraints, it appears in a smaller font). |

|
Again, there is a clone method which does some interesting things
that we will discuss towards the end of the semester.
For now, if we want to make a copy of a set s (or any collection or
ordered collection), we will use it in a constructor:
Set s2 = new HashSet(s) will create a copy of set s such
that s.equals(s2) returns true.
Actually these two sets are represented by separate objects, but these
separate objects share all the element objects between them: if an object is
mutated through one set, it appears mutated in the other set as well.
True copying, with the more complicated clone method does not have this
mutate/sharing behavior.
So, the structure leading from the Collection interface to the HashSet concrete classes involve all sorts of interesting inheritance of interfaces, abstract, and concrete methods. Again, we can USE all these classes without knowing this information, mostly by examining just theSet interface, and the constuctors for this class, and knowing that it implements its methods efficiently.
Finally, note that the toString method for a set works just like it does
for a list: it returns a String with all values enclosed in brackets,
separated by commas:
e.g.,
Now, we discuss the iterators for this class and then the performance of all its methods in terms of big O notation, where N is typically the number of elements stored in the collection. |
| Iterators for Set |
Sometimes it is useful to examine every element in a set: to print it, or
selectively remove it from the collection.
Thus, the remove methods for list iterators actually remove the element
just returned by next.
Here is an example that illustrates how to remove all the odd elements in a
set s of Integers.
for (Iterator i = s.iterator(); i.hasNext(); ) {
Integer next = (Integer)i.next();
if (next.intVal() % 2 == 1)
i.remove();
}
You will note that this code is identical for that we used to remove all
the odd elements from a List: the iterators impose this uniformity.
|
| Complexity Classes for Set |
The following table summarizes the complexity classes of all the methods
in the classes that implement the Set interface.
In the table below * means amortized complexity. That is, when we add a value in a hash table, most of the time we perform some constant number of operations, independent of the size of the hash table. But every so often, we must construct a new hash table with a bigger length, and then copy all the hash table's elements into it. If we pretended that each add did more operations (but still a constant number, just a bigger constant), that number would dominate the actual number of operations needed for all the doubling. In the table below ** means that the parameter to the method is some collection (or array) storing M elements.
|
| Using hash tables (backed by arrays), the entire hash table must be reallocated and all the elements must be re-added (re-hashed) when its load factor is exceeded (discussed in the next lecture). |
| Design of the Map Classes | In this section we will start examining in detail the design for one class that ultimately implements the Map interface (and may implement the SortedMap interface). For maps, we will explore the following hierarchy of interfaces, abstract classes, and concrete classes. |

| We will examine the overall relationships among these interfaces, the abstract classes that implement them, and the concrete classes that extend these abstract classes. |
| Map Interfaces |
Maps are the most useful and versatile collection class; other collection
classes are often used in conjunction with (as parts of) maps.
We can think of maps as generalizing mathematical functions: if we know
that f(a) = b, then we can put the pair consisting of the key
a and its value b into the map.
We also say that a is a value from the domain of the function/map
and b is its correpsonding value in the range.
For example, if f were the "antonym" function, then its domain and
range would be String, with f("good") = "bad".
We can also think of maps as generalizing arrays by allowing us to associate any object (the one stored in the array) with an index (not necessarily an int). Although such associative arrays use method-call syntax (e.g., antonym.put("good","bad");, which is like the set method for arrays), we can THINK of them in standard array syntax: antonym["good"] = "bad" The methods specified in the Map interface are summarized in the following Javadoc. Primarily, this interface allows us to manipulate the key/value pairs in a map: to add them, to remove them (based on the key), to locate the value for a given key, to check whether a key or a value is in the map, to get a set of the keys (or a collection of the values), etc. Note: great care must be exercised if mutable objects are used as map keys. The behavior of a map is not specified if the value of an object is changed in a manner that affects equals comparisons while the object is a key in the map. A special case of this prohibition is that it is not permissible for a map to contain itself as a key. While it is permissible for a map to contain itself as a value, extreme caution is advised: the equals and hashCode methods are no longer well defined on a such a map. On the other hand, chaninging the infomation associated with a key is no problem, and in fact happens frequently. |

The Map interface also defines a nested interface named
Entry (so its full name becomes Map.Entry), which is used to
represent each key/value pair (also called an association) in a map.
Technically, although the Javadoc calls it an inner class, it is not:
because, it is declared static.
Such nested classes, unlike inner classes,
|

|
Putting all this information together, we can picture a simple map
for storing and computing the antonyms of words.
We can picture an antonym map, implemented by a HashMap, with
four values as follows.
|

|
Here, we call the put method to put a key/value pair into a map; if
that key is already present in the map, its value is replaced by this one.
(putAll allows us to copy all pairs from one map to another).
We call the remove method (with just the key as an argument) to remove
a pair from the map.
And, we call the get method (with just the key as an argument) to
retrieve its assocated value (or return null if they key is not
contained in the map).
The methods clear, isEmpty, and size perform as they did for collections. Finally, there are various methods that return sets specifically, or collections generally, which we can use to iterate over: keySet returns a set of all the keys; values returns a collection of all the values; entrySet returns a set of all the key/value pairs (each of type MapEntry). The SortedMap interface extends Map with operations based on some ordering of the elements in a map; when constructing an object from a class that implements SortedMap (e.g., TreeMap), we must supply an argument constructed from a class that implements Comparator that specifies this ordering. Then, the SortedMap performs these extra methods based on this Comparator. The methods specified in the SortedMap interface are summarized in the following Javadoc. |

Pragmatically, I have never used TreeMap (nor any other class that
implements SortedMap); the standard Map interface has always
been powerful enough for what I want to do, and often its operations are
more efficient.
If I do want to "order" the keys/values, it is often to print them out in
order: to do this I write code similar to the following.
Object[] keys = m.keySet().toArray();
Arrays.sort(keys, some-comparator-object);
for (int i=0, length=keys.length; i<length; i++)
System.out.println(keys[i] + " -> " + m.get(keys[i]));
Which prints each pair in the form key -> value.
An alternative way to write this code follows: by using entrySet
instead of keySet, the comparator will be a bit more complicated
(but can be a bit more general, since it can look at both the key and
value of an entry) but the println statements is simpler
(it does no get operation in the map).
|
| Map Abstract Classes | The AbstractMap class implements the Map interface. Here is the Javadoc of AbstractMap (because of size constraints, it appears in a smaller font). |

| This abstract class provides many concrete implementations for the methods by using iterators. These methods run very slow and are overridden by its concrete subclasses. |
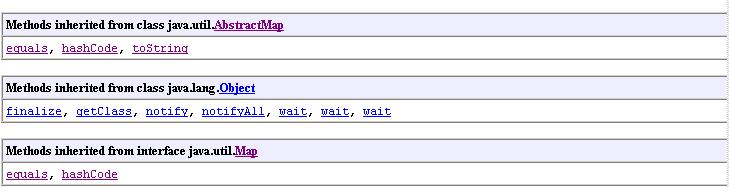
| Concrete Classes | Now we will examine the Javadoc of a concrete class that extends AbstractMap. The HashSet class is implemented with an hash table backing the map (we will examine hash tables, which typically are themselves backed by arrays, in the next lecture). The HashMap class defines 4 public constructors; it overrides many inherited methods that were inefficient. From the constructor, you can read that hash tables have "initial sizes" and "load factors"; you will need to use only the first and last constructors this semester; the other parameters relate to fine-tuning the efficiency of the underlying hash table, and is a topic you will study in 15-211. Here is the Javadoc of HashMap (because of size constraints, it appears in a smaller font). |

|
Again, there is a clone method which does some interesting things
that we will discuss towards the end of the semester.
For now, if we want to make a copy of a map m, we will use it in a
constructor:
Map m2 = new HashMap(m) will create a copy of map m such
that m.equals(m2) returns true.
Actually these two maps are represented by separate objects, but these
separate objects share all the element objects between them: if an object is
mutated through one map, it appears mutated in the other set as well.
True copying, with the more complicated clone method does not have this
mutate/sharing behavior.
So, the structure leading from the Map interface to the HashMap concrete classes involve all sorts of interesting inheritance of interfaces, abstract, and concrete methods. Again, we can USE all these classes without knowing this information, mostly by examining just the Map interface, and the constuctors for this class, and knowing that it implements its methods efficiently.
Finally, note that the toString method for a map returns a
String with all pairs enclosed in braces, separated by commas
(and a space), with an equal sign between each key and its value:
e.g.,
Now we discuss the iterators for this class and then the performance of all its methods in terms of big O notation, where N is typically the number of elements stored in the collection. |
| Iterators for Map |
Maps do not directly implement iterators; instead, they define methods
that returns specific sets (or general collections) with which we can
use iterators.
The entrySet method returns a set consisting of all the key/value
pairs (each represented by objects implementing the Map.Entry
interface).
As with other collections, sometimes it is useful to remove values from a
map.
Thus, the remove methods for list iterators actually remove the element
just returned by next.
Here is an example that illustrates how to print all the pairs in a
map m, with the key and value separated by an arrow.
|
| Complexity Classes |
The following table summarizes the complexity classes of all the methods
in the classes that implement the Map interface.
Notice the assymetry between keys and values: it is fast to check the
properities of single keys but slow to check the properities of single
values.
In the table below * means amortized complexity. That is, when we add a value in a hash table, most of the time we perform some constant number of operations, independent of the size of the hash table. But every so often, we must construct a new hash table with a bigger length, and then copy all the hash table's elements into it. If we pretended that each add did more operations (but still a constant number, just a bigger constant), that number would dominate the actual number of operations needed for all the doubling. In the table below ** means that the parameter to the method is some collection (or array) storing M elements.
|
| Using hash tables (backed by arrays), the entire hash table must be reallocated and all the elements must be re-added (re-hashed) when its load factor is exceeded (discussed in the next lecture). |
| Simple Examples of Using Collection Class |
In this section we will illustrate a few interesting uses of collection
classes, focussing on how they are combined to represent and process
complex information easily.
During this discussion, we will examine a useful notation for describing the
interrelated collections needed to specify these data structures.
We call this modeling the data structure by collection classes.
For a first task, assume that we want to store the antonym (singular) and synonyms (plural) for a large collection of words. Each word will have a single best antonym and an arbitrary number of synonyms. Given a word, we want to be able to retrieve its antonym and synonyms quickly and easily. So, we will model the data structure by first using a map from a word (a String) to its antonym/synonym information. We start by writing Map[String] -> antonym-synonyms-value. Next, we will refine this description by representing the value associated with a word by using a list: its first position stores the antonym (a String) and its second position stores all the synonmyms; we now write model as Map[String] -> List[String,synonyms]. Finally, we will refine this model by representing all of the synonyms in a set of Strings; we write this last refinement as Map[String] -> List[String,Set[String]]. We read this model as a map from a String to a two element list, whose first element is a String and whose second element is a set of Strings. Before proceeding, we should note that this is not the only way to model this data. We could also use Map[String] -> List[String,List[String*]]. Here we model all the synonyms as a list, not a set; the word String and the superscript star indicates that every position in the list is a String and that there are zero or more of them (alot like braces in EBNF). So, which is better to model this aspect of the data, a set or a list? It depends whether the synonyms have any sequential properties: are they ordered (would they need to be inserted in order; would removing one need to retain the order)? is there some logical notion of one synonym following another? I answered these questions no, so I chose the simpler set collection to model this aspect of the problem. If I needed to print the synonyms in order, I could always copy the set into a temporary list and then sort the list.
As a first task, let's assume that we have already built this map, called
thesaurus.
Now, let's do a simple operation on it: lets choose a word, look up its
antonym, and then look up and print all the synoynms of its antonym
(this is why we don't have to store more than one antonym: because we
can store it as a word in the data structure, along with its synonyms).
So, if we choose the word big, we might retrieve the antonym
small, and then retrieve its synonyms little, tiny,
short, and minute.
The code for doing this is shown below.
Recall that collection classes all use Object, so we must
cast the results (using interface names) frequently.
Actually, we could just define Object synOfAnt = ((List)thesaurus.get(antonym)).get(1); because all we are doing with this object is catentating it, so Java will automatically call its toString method, which all objects have. The principle is not to cast unless it is really necessary for subsequent operations.
Now, let's write some more complicated code: the code to build this data
structure.
Lets start with a method that takes a String of tokens representing
a word, followed by its antonym (there must be one), followed by any
number of synonyms (including zero).
This method will build a new entry and put it in the map (so it must be
called repeatedly to build all the entries in thesaurus).
We could write a different but equivalent version that builds entries outside
in.
|
| Cross Reference |
As a second and final example we will present the major code fragments of a
cross reference program (the full program can be downloaded below).
This program prompts for a file name, reads each of the words it contains
(stripping out punctuation), and produces a cross reference (or concordance)
of the text: it prints every word in the text (sorted alphabetically, case
insensitive), followed by all the lines that it appears on (each line number
appears just once for a word, even if that word appears multiple times on the
line).
All this information is written in a file whose name is derived from the
input file's name.
We model the main data structure as Map[String] -> List[Integer*]. By checking the last entry in a non-empty list, we can see whether to add the current line number (only if it is different; of course, if the list is empty we always add it). You can download, unzip, run, and examine all this code in the Cross Reference.
Assume that input stores a TypedBufferReader that uses
white-space and punctuation to separate tokens and that xref
stores a Map (initially empty).
The following code, which appears in the read-loop, processes each word and
its line number.
There are many ways write the code needed to accomplish this goal, some
simpler or more efficient tha others.
I happen to think that the approach shown above is best overall.
But, I have seen the following code too, which is a bit shorter (if we don't
compress the put above into one line), but
examines the xref map twice (once by calling containsKey and
once by calling get).
Of course, both these methods are O(1); but, when I measured the execution
times for each approach, I found that this second one was about 15% slower
than the approach I showed first, which examines the xref map only
once for each word.
After the xref map is filled, we must sort the information and then
print it.
The following code accomplishes this goal.
|
| Problem Set |
To ensure that you understand all the material in this lecture, please solve
the the announced problems after you read the lecture.
If you get stumped on any problem, go back and read the relevant part of the lecture. If you still have questions, please get help from the Instructor, a CA, or any other student. The programming assignment will throroughly test your ability to use all the collecton classes.
|
