
| Home |
| People |
| Publications |
| Software |
| News |
| Internal |
Reconfigurable Hardware
 |
Reconfigurable hardware devices are hardware devices in which the functionality of the logic gates is customizable at run-time. The connections between the logic gates are also configurable. |
| The main ingredient used in building today's reconfigurable hardware fabrics is the memory cell. Memories are used as look-up tables to implement the universal gates, and are used to control the configuration of the switches in the interconnection network. The program that indicates the functionality of each gate and the switch state is called a configuration. | 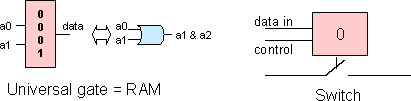
|
The most common type of
reconfigurable hardware device is an FPGA, or Field
Programmable Gate Array. The world market for FPGAs in
1999 was 2.6B$.
 Today's systems use reconfigurable hardware to augment a CPU-based system. Using reconfigurable hardware requires a laborious manual process: the application has to be manually decomposed into parts running on the CPU and on the RH part, compiling them separately and synthesizing the communication interfaces. |
 In our vision, reconfigurable hardware will be the main computation core; each application will be translated into hardware (Application-Specific Hardware) automatically. The CPU will only be relegated to support tasks. |
Because a gate implemented from a small memory is rather bulky, conventional reconfigurable devices are less dense and slower (i.e. can achieve lower clock rates) than regular integrated circuits. However, nanotechnologies promise to offer reconfigurable hardware devices with densities of up to 1010 gates/cm2.
Properties of the Spatial Model of Computing
We have carried a preliminary study to assess the properties of the spatial model of computation. Our study shows that this paradigm has some non-intuitive properties, which are different from the classical model of computation, in which a processor interprets a program in machine-code.
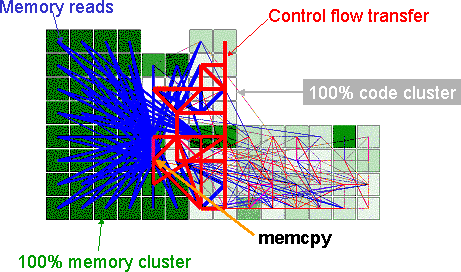 In this image we see the
spatial layout of a program from the Mediabench benchmark
suite; the layout was automatically generated by a placer
tool, based on the profiled execution of the code. Each
square is a cluster of computation and memory having 100
units of area, where 1 unit is roughly one 32-bit integer
operation or one 32-bit memory word. Green indicates
memory, white program code. The edges indicate
communication: red is control-flow transfers, while blue
is memory access. The thickness of an edge is
proportional to the logarithm of the number of times the
edge is used during the program execution. Communication
along one edge takes time proportional to the length of
the edge.
In this image we see the
spatial layout of a program from the Mediabench benchmark
suite; the layout was automatically generated by a placer
tool, based on the profiled execution of the code. Each
square is a cluster of computation and memory having 100
units of area, where 1 unit is roughly one 32-bit integer
operation or one 32-bit memory word. Green indicates
memory, white program code. The edges indicate
communication: red is control-flow transfers, while blue
is memory access. The thickness of an edge is
proportional to the logarithm of the number of times the
edge is used during the program execution. Communication
along one edge takes time proportional to the length of
the edge.
In all the programs we have analyzed we noticed the existence of some very large "stars" in the layout: nodes which have a lot of neighbors. These nodes will impair the timing, because there is no 2D layout which can place all the neighbors close to the center.
By analyzing the program we discovered that one of the star centers it the memcpy library function. This function touches most of the memory of this program.
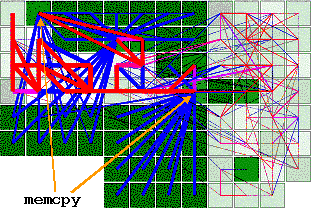
By applying a very simple classical optimization we have dramatically improved the program layout, and implicitly its performance. What we did is to inline the body of the memcpy function into some of its callers. This has effectively caused the star to break into several smaller stars, which can have a much better layout.