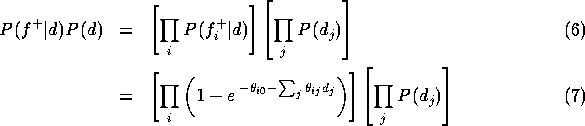Carrying out diagnostic inference in the QMR model involves
computing the posterior marginal probabilities of the diseases given a
set of observed positive ( ![]() ) and negative (
) and negative ( ![]() )
findings. Note that the set of observed findings is considerably smaller
than the set of possible findings; note moreover (from the bi-partite
structure of the QMR-DT graph) that unobserved findings have no effect on
the posterior probabilities for the diseases. For brevity we
adopt a notation in which
)
findings. Note that the set of observed findings is considerably smaller
than the set of possible findings; note moreover (from the bi-partite
structure of the QMR-DT graph) that unobserved findings have no effect on
the posterior probabilities for the diseases. For brevity we
adopt a notation in which ![]() corresponds to the event
corresponds to the event ![]() , and
, and
![]() refers to
refers to ![]() (positive and negative findings
respectively). Thus the posterior probabilities of interest are
(positive and negative findings
respectively). Thus the posterior probabilities of interest are
![]() , where
, where ![]() and
and ![]() are the vectors of positive and
negative findings.
are the vectors of positive and
negative findings.
The negative findings ![]() are benign with respect to the inference
problem--they can be incorporated into the posterior probability in
linear time in the number of associated diseases and in the number of
negative findings. As we discuss below, this can be seen from the fact
that the probability of a negative finding in Eq. (4) is the
exponential of an expression that is linear in the
are benign with respect to the inference
problem--they can be incorporated into the posterior probability in
linear time in the number of associated diseases and in the number of
negative findings. As we discuss below, this can be seen from the fact
that the probability of a negative finding in Eq. (4) is the
exponential of an expression that is linear in the ![]() . The positive
findings, on the other hand, are more problematic. In the worst case
the exact calculation of posterior probabilities is exponentially
costly in the number of positive findings (Heckerman, 1989;
D'Ambrosio, 1994). Moreover, in practical diagnostic situations
the number of positive findings often exceeds the feasible limit for
exact calculations.
. The positive
findings, on the other hand, are more problematic. In the worst case
the exact calculation of posterior probabilities is exponentially
costly in the number of positive findings (Heckerman, 1989;
D'Ambrosio, 1994). Moreover, in practical diagnostic situations
the number of positive findings often exceeds the feasible limit for
exact calculations.
Let us consider the inference calculations in more detail. To find
the posterior probability ![]() , we first absorb the evidence
from negative findings, i.e., we compute
, we first absorb the evidence
from negative findings, i.e., we compute ![]() . This is just
. This is just
![]() with normalization. Since both
with normalization. Since both ![]() and P(d)
factorize over the diseases (see Eq. (1) and Eq. (2)
above), the posterior
and P(d)
factorize over the diseases (see Eq. (1) and Eq. (2)
above), the posterior ![]() must factorize as well. The
normalization of
must factorize as well. The
normalization of ![]() therefore reduces to independent
normalizations over each disease and can be carried out in time linear
in the number of diseases (or negative findings). In the remainder of
the paper, we concentrate solely on the positive findings as they pose the
real computational challenge. Unless otherwise stated, we assume that
the prior distribution over the diseases already contains the evidence
from the negative findings. In other words, we presume that the updates
therefore reduces to independent
normalizations over each disease and can be carried out in time linear
in the number of diseases (or negative findings). In the remainder of
the paper, we concentrate solely on the positive findings as they pose the
real computational challenge. Unless otherwise stated, we assume that
the prior distribution over the diseases already contains the evidence
from the negative findings. In other words, we presume that the updates
![]() have already been made.
have already been made.
We now turn to the question of computing ![]() , the
posterior marginal probability based on the positive findings. Formally,
obtaining such a posterior involves marginalizing
, the
posterior marginal probability based on the positive findings. Formally,
obtaining such a posterior involves marginalizing ![]() across
the remaining diseases:
across
the remaining diseases:
where the summation is over all the possible configurations of the
disease variables other than ![]() (we use the shorthand summation index
(we use the shorthand summation index
![]() for this). In the QMR model
for this). In the QMR model ![]() has
the form:
has
the form:
which follows from Eq. (4) and the fact that
![]() . To perform the summation in Eq. (5)
over the diseases, we would have to multiply out the terms
. To perform the summation in Eq. (5)
over the diseases, we would have to multiply out the terms
![]() corresponding to the conditional probabilities for
each positive finding. The number of such terms is exponential
in the number of positive findings. While algorithms exist
that attempt to find and exploit factorizations in this expression,
based on the particular pattern of observed evidence
(cf. Heckerman, 1989; D'Ambrosio, 1994), these algorithms
are limited to roughly 20 positive findings on current
computers. It seems unlikely that there is sufficient
latent factorization in the QMR-DT model to be able to
handle the full CPC corpus, which has a median number
of 36 positive findings per case and a maximum number
of 61 positive findings.
corresponding to the conditional probabilities for
each positive finding. The number of such terms is exponential
in the number of positive findings. While algorithms exist
that attempt to find and exploit factorizations in this expression,
based on the particular pattern of observed evidence
(cf. Heckerman, 1989; D'Ambrosio, 1994), these algorithms
are limited to roughly 20 positive findings on current
computers. It seems unlikely that there is sufficient
latent factorization in the QMR-DT model to be able to
handle the full CPC corpus, which has a median number
of 36 positive findings per case and a maximum number
of 61 positive findings.