In the previous section we described how variational transformations are derived for individual findings in the QMR model; we now discuss how to utilize these transformations in the context of an overall inference algorithm.
Conceptually the overall approach is straightforward. Each transformation involves replacing an exact conditional probability of a finding with a lower bound and an upper bound:
![]()
Given that such transformations can be viewed as delinking the ith finding node from the graph, we see that the transformations not only yield bounds, but also yield a simplified graphical structure. We can imagine introducing transformations sequentially until the graph is sparse enough that exact methods become feasible. At that point we stop introducing transformations and run an exact algorithm.
There is a problem with this approach, however. We need to decide at each step which node to transform, and this requires an assessment of the effect on overall accuracy of transforming the node. We might imagine calculating the change in a probability of interest both before and after a given transformation, and choosing to transform that node that yields the least change to our target probability. Unfortunately we are unable to calculate probabilities in the original untransformed graph, and thus we are unable to assess the effect of transforming any one node. We are unable to get the algorithm started.
Suppose instead that we work backwards. That is, we introduce transformations for all of the findings, reducing the graph to an entirely decoupled set of nodes. We optimize the variational parameters for this fully transformed graph (more on optimization of the variational parameters below). For this graph inference is trivial. Moreover, it is also easy to calculate the effect of reinstating a single exact conditional at one node: we choose to reinstate that node which yields the most change.
Consider in particular the case of the upper bounds (lower bounds
are analogous). Each transformation introduces an upper bound
on a conditional probability ![]() . Thus the likelihood
of observing the (positive) findings
. Thus the likelihood
of observing the (positive) findings ![]() is also upper bounded
by its variational counterpart
is also upper bounded
by its variational counterpart ![]() :
:
![]()
We can assess the accuracy of each variational transformation after
introducing and optimizing the variational transformations for all
the positive findings. Separately for each positive finding
we replace the variationally transformed conditional probability
![]() with the corresponding exact conditional
with the corresponding exact conditional ![]() and compute the difference between the resulting bounds on the
likelihood of the observations:
and compute the difference between the resulting bounds on the
likelihood of the observations:
![]()
where ![]() is computed without transforming the
is computed without transforming the
![]() positive finding. The larger the difference
positive finding. The larger the difference ![]() is, the
worse the
is, the
worse the ![]() variational transformation is. We should therefore
introduce the transformations in the ascending order of
variational transformation is. We should therefore
introduce the transformations in the ascending order of ![]() s.
Put another way, we should treat exactly (not transform) those conditional
probabilities whose
s.
Put another way, we should treat exactly (not transform) those conditional
probabilities whose ![]() measure is large.
measure is large.
In practice, an intelligent method for ordering the transformations
is critical. Figure 2 compares the calculation of likelihoods
based on the ![]() measure as opposed to a method that chooses the
ordering of transformations at random. The plot corresponds to a representative
diagnostic case, and shows the upper bounds on the log-likelihoods of
the observed findings as a function of the number of conditional
probabilities that were left intact (i.e. not transformed).
Note that the upper bound must improve (decrease) with fewer
transformations. The results are striking--the choice of
ordering has a large effect on accuracy (note that the plot is on
a log-scale).
measure as opposed to a method that chooses the
ordering of transformations at random. The plot corresponds to a representative
diagnostic case, and shows the upper bounds on the log-likelihoods of
the observed findings as a function of the number of conditional
probabilities that were left intact (i.e. not transformed).
Note that the upper bound must improve (decrease) with fewer
transformations. The results are striking--the choice of
ordering has a large effect on accuracy (note that the plot is on
a log-scale).
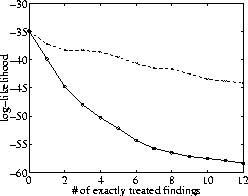
Figure 2: The upper bound on the log-likelihood for the delta
method of removing transformations (solid line) and a method
that bases the choice on a random ordering (dashed line).
Note also that the curve for the proposed ranking is convex; thus the bound improves less the fewer transformations there are left. This is because we first remove the worst transformations, replacing them with the exact conditionals. The remaining transformations are better as indicated by the delta measure and thus the bound improves less with further replacements.
We make no claims for optimality of the delta method; it is simply a useful heuristic that allows us to choose an ordering for variational transformations in a computationally efficient way. Note also that our implementation of the method optimizes the variational parameters only once at the outset and chooses the ordering of further transformations based on these fixed parameters. These parameters are suboptimal for graphs in which substantial numbers of nodes have been reinstated, but we have found in practice that this simplified algorithm still produces reasonable orderings.
Once we have decided which nodes to reinstate, the approximate inference algorithm can be run. We introduce transformations at those nodes that were left transformed by the ordering algorithm. The product of all of the exact conditional probabilities in the graph with the transformed conditional probabilities yields an upper or lower bound on the overall joint probability associated with the graph (the product of bounds is a bound). Sums of bounds are still bounds, and thus the likelihood (the marginal probability of the findings) is bounded by summing across the bounds on the joint probability. In particular, an upper bound on the likelihood is obtained via:
and the corresponding lower bound on the likelihood is obtained similarly:
In both cases we assume that the graph has been sufficiently simplified by the variational transformations so that the sums can be performed efficiently.
The expressions in Eq. (29) and Eq. (30) yield upper
and lower bounds for arbitrary values of the variational parameters ![]() and
q. We wish to obtain the tightest possible bounds, thus we optimize these
expressions with respect to
and
q. We wish to obtain the tightest possible bounds, thus we optimize these
expressions with respect to ![]() and q. We minimize with respect
to
and q. We minimize with respect
to ![]() and maximize with respect to q. Appendix 6
discusses these optimization problems in detail. It turns out that the
upper bound is convex in the
and maximize with respect to q. Appendix 6
discusses these optimization problems in detail. It turns out that the
upper bound is convex in the ![]() and thus the adjustment of the variational
parameters for the upper bound reduces to a convex optimization problem
that can be carried out efficiently and reliably (there are no local
minima). For the lower bound it turns out that the maximization can be
carried out via the EM algorithm.
and thus the adjustment of the variational
parameters for the upper bound reduces to a convex optimization problem
that can be carried out efficiently and reliably (there are no local
minima). For the lower bound it turns out that the maximization can be
carried out via the EM algorithm.
Finally, although bounds on the likelihood are useful, our ultimate goal
is to approximate the marginal posterior probabilities ![]() .
There are two basic approaches to utilizing the variational bounds
in Eq. (29) and Eq. (30) for this purpose. The first
method, which will be our emphasis in the current paper, involves using the
transformed probability model (the model based either on upper or lower
bounds) as a computationally efficient surrogate for the original probability
model. That is, we tune the variational parameters of the transformed model
by requiring that the model give the tightest possible bound on the likelihood.
We then use the tuned transformed model as an inference engine to provide
approximations to other probabilities of interest, in particular the
marginal posterior probabilities
.
There are two basic approaches to utilizing the variational bounds
in Eq. (29) and Eq. (30) for this purpose. The first
method, which will be our emphasis in the current paper, involves using the
transformed probability model (the model based either on upper or lower
bounds) as a computationally efficient surrogate for the original probability
model. That is, we tune the variational parameters of the transformed model
by requiring that the model give the tightest possible bound on the likelihood.
We then use the tuned transformed model as an inference engine to provide
approximations to other probabilities of interest, in particular the
marginal posterior probabilities ![]() . The approximations
found in this manner are not bounds, but are computationally efficient
approximations. We provide empirical data in the following section that
show that this approach indeed yields good approximations to the marginal
posteriors for the QMR-DT network.
. The approximations
found in this manner are not bounds, but are computationally efficient
approximations. We provide empirical data in the following section that
show that this approach indeed yields good approximations to the marginal
posteriors for the QMR-DT network.
A more ambitious goal is to obtain interval bounds for the marginal
posterior probabilities themselves. To this end, let ![]() denote
the combined event that the QMR-DT model generates the observed findings
denote
the combined event that the QMR-DT model generates the observed findings
![]() and that the
and that the ![]() disease takes the value
disease takes the value ![]() . These bounds
follow directly from:
. These bounds
follow directly from:
![]()
where ![]() is a product of upper-bound transformed
conditional probabilities and exact (untransformed) conditionals.
Analogously we can compute a lower bound
is a product of upper-bound transformed
conditional probabilities and exact (untransformed) conditionals.
Analogously we can compute a lower bound
![]() by applying the lower bound transformations:
by applying the lower bound transformations:
![]()
Combining these bounds we can obtain interval bounds on the posterior marginal probabilities for the diseases (cf. Draper & Hanks 1994):
where ![]() is the binary complement of
is the binary complement of ![]() .
.