The techniques described in this paper have been implemented as a system
called LEONARD and tested on a number of video
sequences. LEONARD successfully recognizes the events pick up, put down,
stack, unstack, move, assemble, and disassemble
using the definitions given in Figure 10.
Figures 1 and 11 through 15 show
the key frames from movies that depict these seven event types.
These movies were filmed using a Canon VC-C3 camera and a Matrox Meteor frame
grabber at 320
LEONARD successfully recognizes the events pick up, put down,
stack, unstack, move, assemble, and disassemble
using the definitions given in Figure 10.
Figures 1 and 11 through 15 show
the key frames from movies that depict these seven event types.
These movies were filmed using a Canon VC-C3 camera and a Matrox Meteor frame
grabber at 320 ![]() 240 resolution at 30fps.
Figures 4 and 16
through 20 show the results of segmentation,
tracking, and model reconstruction for those key frames superimposed on the
original images.
Figures 5 and 21
through 25 show the results of event
classification for these movies.
These figures show LEONARD correctly recognizing the intended event classes
for each movie.
240 resolution at 30fps.
Figures 4 and 16
through 20 show the results of segmentation,
tracking, and model reconstruction for those key frames superimposed on the
original images.
Figures 5 and 21
through 25 show the results of event
classification for these movies.
These figures show LEONARD correctly recognizing the intended event classes
for each movie.

Figure 16: The output of the segmentation-and-tracking and model-reconstruction
components applied to the image sequence from
Figure 11, an image sequence that depicts a
stack event.
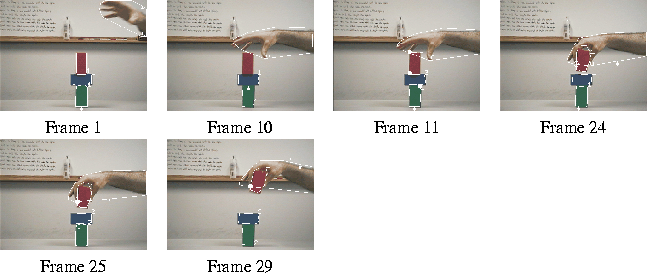
Figure 17: The output of the segmentation-and-tracking and model-reconstruction
components applied to the image sequence from
Figure 12, an image sequence that depicts an
unstack event.

Figure 18: The output of the segmentation-and-tracking and model-reconstruction
components applied to the image sequence from
Figure 13, an image sequence that depicts a
move event.

Figure 19: The output of the segmentation-and-tracking and model-reconstruction
components applied to the image sequence from
Figure 14, an image sequence that depicts an
assemble event.

Figure 20: The output of the segmentation-and-tracking and model-reconstruction
components applied to the image sequence from
Figure 15, an image sequence that depicts a
disassemble event.

Figure 21: The output of the event-classification component applied to the
model sequence from Figure 16.
Note that the stack event is correctly recognized, as well as the
constituent put down event.
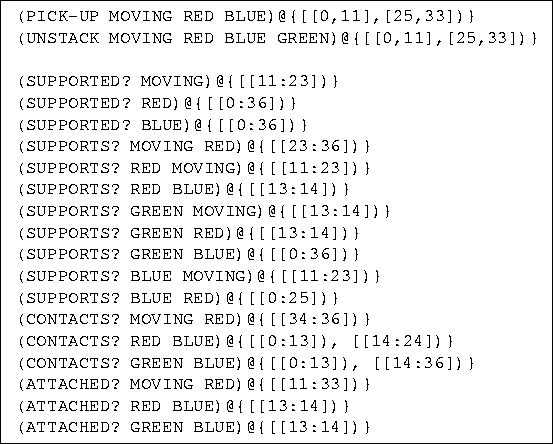
Figure 22: The output of the event-classification component applied to the
model sequence from Figure 17.
Note that the unstack event is correctly recognized, as well as the
constituent pick up event.
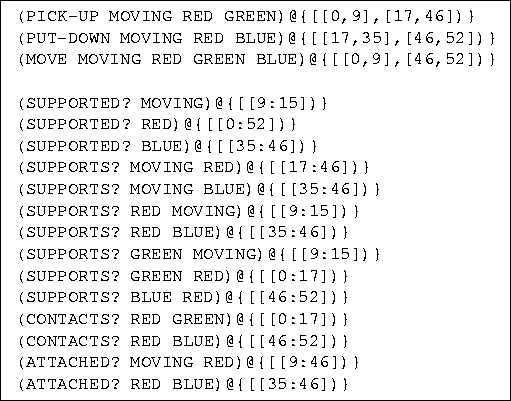
Figure 23: The output of the event-classification component applied to the
model sequence from Figure 18.
Note that the move event is correctly recognized, as well as the
constituent pick up and put down subevents.

Figure 24: The output of the event-classification component applied to the
model sequence from Figure 19.
Note that the assemble event is correctly recognized, as well as the
constituent put down and stack subevents.

Figure 25: The output of the event-classification component applied to the
model sequence from Figure 20.
Note that the disassemble event is correctly recognized, as well as
the constituent pick up and unstack subevents.
In Figure 4(a), Frames 0 through 1 correspond to the first subevent of a pick up event, Frames 2 through 13 correspond to the second subevent, and Frames 14 through 22 correspond to the third subevent. In Figure 4(b), Frames 0 through 13 correspond to the first subevent of a put down event, Frames 14 through 22 correspond to the second subevent, and Frames 23 through 32 correspond to the third subevent. LEONARD correctly recognizes these as instances of pick up and put down respectively. In Figure 16, Frames 0 through 11, 12 through 23, and 24 through 30 correspond to the three subevents of a put down event. LEONARD correctly recognizes this as a put down event and also as a stack event. In Figure 17, Frames 0 through 10, 11 through 24, and 25 through 33 correspond to the three subevents of a pick up event. LEONARD correctly recognizes this as a pick up event and also as an unstack event. In Figure 18, Frames 0 through 8, 9 through 16, and 17 through 45 correspond to the three subevents of a pick up event and Frames 17 through 33, 34 through 45, and 46 through 52 correspond to the three subevents of a put down event. LEONARD correctly recognizes the combination of these two events as a move event. In Figure 19, Frames 18 through 32, 33 through 40, and 41 through 46 correspond to the three subevents of a put down event and Frames 57 through 67 and 68 through 87 correspond to the first and third subevents of a second put down event, with the second subevent being empty. The second put down event is also correctly recognized as a stack event and the combination of these two events is correctly recognized as an assemble event. In Figure 20, Frames 0 through 18, 19 through 22, and 23 through 50 correspond to the three subevents of a pick up event and Frames 23 through 56, 57 through 62, and 63 through 87 correspond to the three subevents of a second pick up event. The first pick up event is also correctly recognized as an unstack event and the combination of these two events is correctly recognized as a disassemble event. These examples show that LEONARD correctly recognizes each of the seven event types with no false positives.
As discussed in the introduction, using force dynamics and event logic to recognize events offers several advantages over the prior approach of using motion profile and hidden Markov models.

Figure 26: The output of the segmentation-and-tracking and model-reconstruction
components on an image sequence depicting a pick up event from the
left instead of from the right.

Figure 27: The output of the segmentation-and-tracking and model-reconstruction
components on an image sequence depicting a pick up event with
extraneous objects in the field of view.

Figure 28: The output of the segmentation-and-tracking and model-reconstruction
components on an image sequence depicting a sequence of a pick up
event, followed by a put down event, followed by another
pick up event, followed by another put down event.

Figure 29: The output of the segmentation-and-tracking and model-reconstruction
components on an image sequence depicting two simultaneous pick up
events.

Figure 30: The output of the segmentation-and-tracking and model-reconstruction
components applied to the image sequences from
Figure 2, image sequences that depict non-events.

Figure 31: The output of the event-classification component applied to the
model sequence from Figure 26.
Note that the pick up event is correctly recognized despite the fact
that it was performed from the left instead of from the right.

Figure 32: The output of the event-classification component applied to the
model sequence from Figure 27.
Note that the pick up event is correctly recognized despite the
presence of extraneous objects in the field of view.
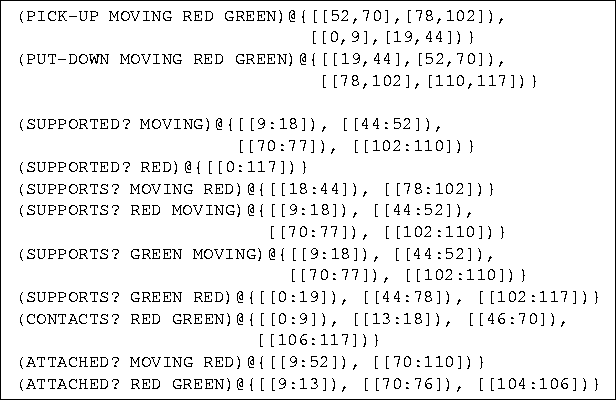
Figure 33: The output of the event-classification component applied to the
model sequence from Figure 28.
Note that LEONARD correctly recognizes a pick up event, followed
by a put down event, followed by another pick up event,
followed by another put down event.

Figure 34: The output of the event-classification component applied to the
model sequence from Figure 29.
Note that the two simultaneous pick up events are correctly
recognized.

Figure 35: The output of the event-classification component applied to the
model sequences from Figure 30.
Note that LEONARD correctly recognizes that no events occurred in these
sequences.
An approach to even classification is valid and useful only if it is robust.
A preliminary evaluation of the robustness of LEONARD was conducted.
Thirty five movies were filmed, five instances of each of the seven event types
pick up, put down, stack, unstack, move,
assemble, and disassemble.
These movies resemble those in Figures 1 and 11
through 15.
The same subject performed all thirty five events.
These movies were processed by LEONARD.
The results of this preliminary evaluation are summarized in
Table 1.
A more extensive evaluation of LEONARD will be conducted in the future.
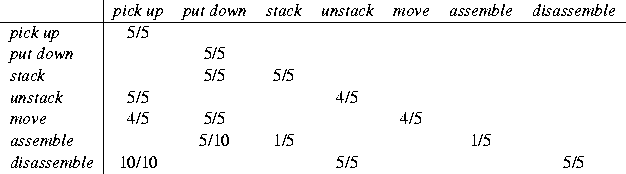
Table 1: An evaluation of the robustness of LEONARD on a test set of five
movies of each of seven event types.
The rows represent movies of the indicated event types.
The columns represent classifications of the indicated event type.
The entries x/y indicate x, the number of times that a movie of the
indicated event type was classified as the indicated event type, and y, the
number of times that the movie should have been classified as the indicated
event type.
Note that stack entails put down, unstack entails
pick up, move entails both a pick up and a
put down, assemble entails both a put down and a
separate stack, and disassemble entails both a pick up
and a separate unstack.
Thus off-diagonal entries are expected in these cases.
There were six false negatives and no false positives.
Four of the false negatives were for the event type assemble.
In three of those cases, LEONARD successfully recognized the constituent
put down subevent but failed to recognize the constituent
stack subevent as well as the associated put down subevent.
In one case, LEONARD failed to recognize both the constituent
put down and stack subevents along with the associated
put down constituent of the stack subevent.
One of the false negatives was for the event type move.
In this case, LEONARD successfully recognized the constituent
put down subevent but failed to recognize the constituent
pick up subevent.
The remaining false negative was for the event type unstack.
In this case, LEONARD successfully recognized the constituent pick up
subevent but failed to recognize the aggregate unstack event.