The process of expert-guided subgroup discovery was performed as follows. For every data stage A, B and C, the DMS algorithm was run for values g in the range 0.5 to 100, and a fixed number of selected output rules equal to 3. The rules induced in this iterative process were shown to the expert for selection and interpretation. The inspection of 15-20 rules for each data stage triggered further experiments. Concrete suggestions of the medical expert involved in this study were to limit the number of features in the rule body and to try to avoid the generation of rules whose features would involve expensive and/or unreliable laboratory tests. Consequently, we have performed the further experiments by intentionally limiting the feature space and the number of iterations in the main loop of the SD algorithm (steps 2-12 of Algorithm SD).
In this iterative process, the expert has selected five interesting CHD risk groups. Table 1 shows the induced subgroups, together with the values of g and the rule significance. In the subgroup discovery terminology proposed in this paper, the features appearing in the conditions of rules describing the subgroups are called the principal factors. The described iterative process was successful for data at stages B and C, but it turned out that anamnestic data on its own (stage A data) is not informative enough for inducing subgroups, i.e., it failed to fulfil the expert's criteria of interestingness. Only after engineering the domain, by separating male and female patients, were interesting subgroups discovered. See Section 3.7 for more details on the expert's involvement in this subgroup discovery process.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
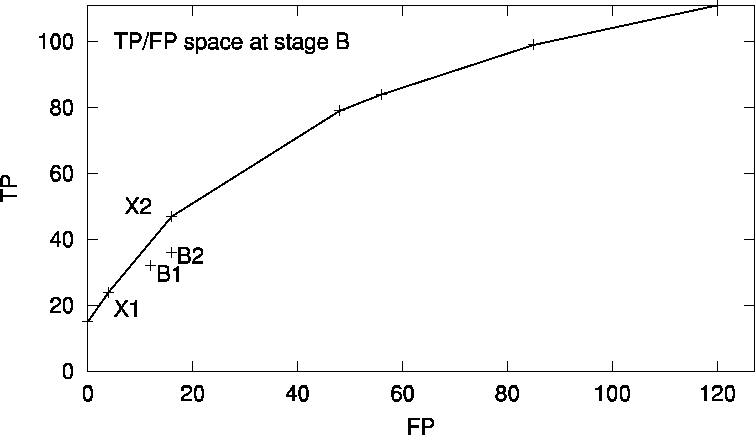
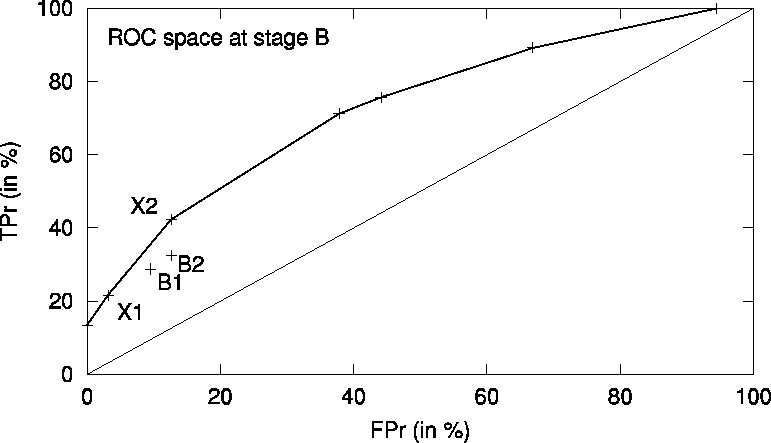
Separately for each data stage, we have investigated which of the induced rules are the best in terms of the ROC space, i.e., which of them are used to define the ROC convex hull. At stage B, for instance, seven rules are on the convex hull shown in Figures 4 and 5 for the TP/FP and the ROC space, respectively. Two of these rules, X1 and X2, indicated in the figures, are listed in Table 2. Notice that the expert-selected subgroups B1 and B2 are significant, but are not among those lying on the convex hull. The reason for selecting exactly those two rules at stage B are their simplicity (consisting of three features only), their generality (covering relatively many positive cases) and the fact that the used features are, from the medical point of view, inexpensive laboratory tests.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|