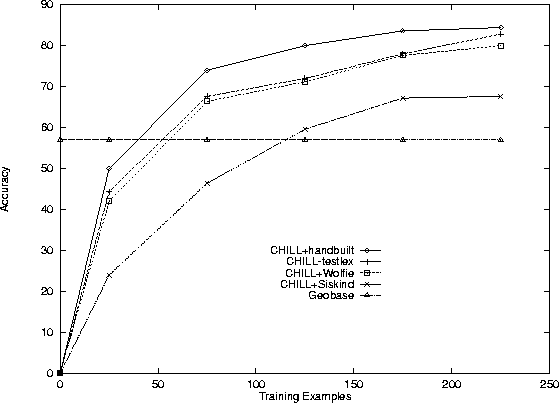
The first experiment was a comparison on the original English corpus.
Figure 9 shows learning curves for CHILL when
using the lexicons learned by WOLFIE (CHILL+Wolfie) and by
Siskind's system (CHILL+Siskind). The uppermost curve (
CHILL+handbuilt) shows CHILL's performance when given the
hand-built lexicon. CHILL-testlex shows the performance when
words that never appear in the training data (e.g., are only in the
test sentences) are deleted from the
hand-built lexicon (since a learning algorithm has no chance of
learning these). Finally, the horizontal line shows the performance of
the GEOBASE benchmark.
Figure 9:
Accuracy on English Geography Corpus
The results show that a lexicon learned by WOLFIE led to parsers that
were almost as accurate as those generated using a hand-built lexicon.
The best accuracy is achieved by parsers using the hand-built lexicon, followed by
the hand-built lexicon with words only in the test set removed,
followed by WOLFIE, followed by Siskind's system. All the systems do
as well or better than GEOBASE by the time they reach 125
training examples. The differences between WOLFIE and Siskind's
system are statistically significant at all training example sizes.
These results show that WOLFIE can learn lexicons that support the learning of
successful parsers, and that are better from this perspective than
those learned by a competing system. Also, comparing to the
CHILL-testlex curve, we see that most of the drop in accuracy from
a hand-built lexicon is due to words in the test set that the system
has not seen during training. In fact, none of the differences
between CHILL+Wolfie and CHILL-testlex are statistically significant.
One of the implicit hypotheses of our problem definition is that
coverage of the training data implies a good lexicon. The results
show a coverage of 100% of the 225 training examples for WOLFIE
versus 94.4% for Siskind. In addition, the lexicons learned by
Siskind's system were more ambiguous and larger than those learned by
WOLFIE. WOLFIE's lexicons had an average of 1.1 meanings per word,
and an average size of 56.5 entries (after 225 training examples) versus
1.7 meanings per word and 154.8 entries in Siskind's lexicons. For
comparison, the hand-built lexicon had 1.2 meanings per word and 88 entries.
These differences, summarized in Table 3,
undoubtedly contribute to the
final performance differences.