An aDPCSP is similar to valued CSPs as presented by Schiex, Fargier and Verfaillie [37] and also to semiring based CSPs [2]. However, it extends both approaches with activity constraints and involves different underlying presumptions in its valuation structure. The preference valuations in this work are allowed to be ordered partially, as opposed to the valued CSPs.
An aDPCSP represents an important type of constraint satisfaction optimisation problem [41]. In order to tackle the optimisation of preferences an A* type algorithm is employed [13,34]. A* algorithms are known to be efficient in terms of the total number of nodes explored in an effort to find optimal solutions, with a given amount of information. On the downside, they have an exponential space complexity. Naturally, a number of alternative approaches could have been explored, including conventional constraint-based solving methods such as depth first branch and bound search. However, the use of an A*-like algorithm is sufficient for solving the aDPCSPs in the domain of the present interest. In particular, algorithm 1 implements an A* search strategy that is capable of handling activity constraints, which involves the use of basic CSP techniques such as constraint propagation and backtracking.
An A* algorithm maintains the explored attribute-value assignments by
means of a priority queue ![]() of nodes. Each node
of nodes. Each node ![]() in
in ![]() corresponds to a set of attribute-value assignments:
solution
corresponds to a set of attribute-value assignments:
solution![]() . The search proceeds through a number of
iterations. At each iteration, a node
. The search proceeds through a number of
iterations. At each iteration, a node ![]() is taken from
is taken from ![]() , and
replaced by nodes that extend
solution
, and
replaced by nodes that extend
solution![]() with an additional
attribute-value assignment. More specifically, for each node
with an additional
attribute-value assignment. More specifically, for each node ![]() in
in
![]() , a set
, a set ![]() of remaining active but unassigned attributes is
maintained. At each iteration, the possible assignments of the first
attribute
of remaining active but unassigned attributes is
maintained. At each iteration, the possible assignments of the first
attribute
![]() , where
, where ![]() is the node taken from
is the node taken from ![]() at the
current iteration, are processed. For every assignment
at the
current iteration, are processed. For every assignment ![]() that is
consistent with
solution
that is
consistent with
solution![]() (i.e.
solution
(i.e.
solution![]() ), a new child
node
), a new child
node ![]() , with
solution
, with
solution![]() solution
solution![]() and
and
![]() , is created and added to
, is created and added to ![]() .
.
The activity constraints are processed via propagation rather than
constraint satisfaction. Whenever a node ![]() is taken from
is taken from ![]() such
that
such
that ![]() is empty, the activity constraints are fired in order to
obtain a new set of active but unassigned attributes. That is,
is empty, the activity constraints are fired in order to
obtain a new set of active but unassigned attributes. That is, ![]() is assigned
is assigned
In the priority queue ![]() , nodes are maintained by means of two
heuristics: committed preference
, nodes are maintained by means of two
heuristics: committed preference ![]() and potential preference
and potential preference
![]() . Here, given a node
. Here, given a node ![]() ,
,
The following theorem shows that algorithm 1 is guaranteed to find the set of attribute-value pairs with the highest combined preferences, within the set of solutions that satisfy the constraints.
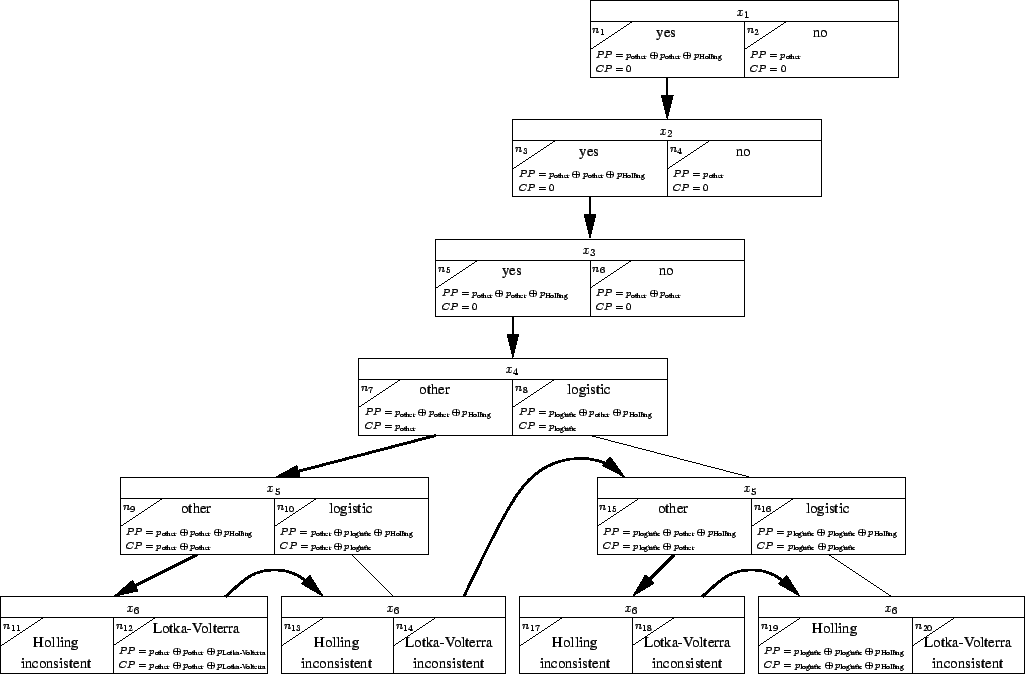
To illustrate algorithm 1, consider the problem of finding an ecological model that describes the behaviour of two populations, one of which predates on the other. An aDPCSP is constructed for the compositional modelling problem with the following attributes and domains. Note that section 3 demonstrates how the attributes, domains and constraints of this problem can be constructed automatically and that section 4 illustrates these ideas in the context of a larger example.
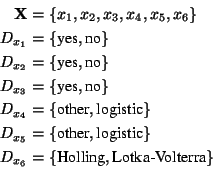 |
The attributes ![]() ,
, ![]() and
and ![]() respectvely describe the
relevance of the following phenomena: the change in size of the
predator population, the change in size of the prey population and the
predation of the prey by the predator. The attributes
respectvely describe the
relevance of the following phenomena: the change in size of the
predator population, the change in size of the prey population and the
predation of the prey by the predator. The attributes ![]() and
and ![]() represent the choice of type of population growth model. Two types of
such models are incorporated in the problem: the logistic one and the
``other''. Finally, attribute
represent the choice of type of population growth model. Two types of
such models are incorporated in the problem: the logistic one and the
``other''. Finally, attribute ![]() is associated with the choice of
model type of the predation phenomenon. Here, two types of model, the
Holling model and the Lotka-Volterra model, are included.
is associated with the choice of
model type of the predation phenomenon. Here, two types of model, the
Holling model and the Lotka-Volterra model, are included.
Because the Holling predation model presumes that logistic models are
employed to describe population growth, and because the Lotka-Volterra
Model incorporates its own population growth model, the combinations
of assignments to ![]() ,
, ![]() , and
, and ![]() are restricted. Hence, the
aDPCSP contains a set
are restricted. Hence, the
aDPCSP contains a set
![]() of compatibility constraints, with:
of compatibility constraints, with:
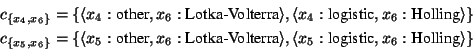 |
Furthermore, a model type of predator/prey growth must be selected if
and only if the corresponding population growth phenomenon is deemed
relevant. Also, a model type of predation must be selected if and
only if both population growth phenomena and the predation phenomenon
are deemed relevant (because ecological models describing predation
rely on submodels describing population growth of the predator and the
prey). Hence, the aDPCSP contains a set
![]() of activity constraints, with:
of activity constraints, with:
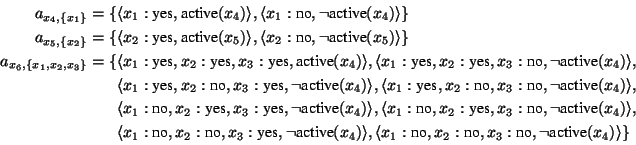 |
Finally, let the preference calculus consist of two orders of
magnitude
![]() and
and
![]() , with
, with
![]() , where
, where
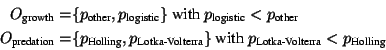 |
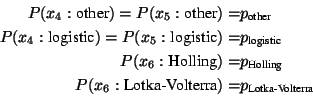 |
When applied to this problem, algorithm 1 initialises the
search by creating a node ![]() , where:
, where:
This initial node is enqueued in ![]() . Next, the algorithm proceeds
through a number of iterations. At each iteration, the node with most
potential (as measured by
. Next, the algorithm proceeds
through a number of iterations. At each iteration, the node with most
potential (as measured by ![]() and
and ![]() ) is dequeued, and its children
are generated and enqueued in
) is dequeued, and its children
are generated and enqueued in ![]() . The nodes that are created in this
way are depicted in Figure 2. The number
. The nodes that are created in this
way are depicted in Figure 2. The number ![]() in
the subscript of each node
in
the subscript of each node ![]() indicates the order of node
generation, and the thick arrows show the order in which the search
space is explored.
indicates the order of node
generation, and the thick arrows show the order in which the search
space is explored.
Note that there are three important features of the algorithm that
could not be clearly demonstrated within Figure
2. Firstly, at node ![]() , the initial set of
unassigned attributes is exhausted:
, the initial set of
unassigned attributes is exhausted:
![]() . Therefore, the
activity constraints are fired when
. Therefore, the
activity constraints are fired when ![]() is explored. Because
is explored. Because ![]() corresponds to the assignment
corresponds to the assignment
![]() yes
yes![]() yes
yes![]() yes
yes![]() , the remaining
attributes are activated and
, the remaining
attributes are activated and ![]() is reset to
is reset to
![]() .
.
Secondly, node ![]() corresponds to an assignment of all (active)
attributes that is consistent with the activity and compatibility
constraints:
corresponds to an assignment of all (active)
attributes that is consistent with the activity and compatibility
constraints:
Thirdly, node ![]() does correspond with an optimal solution.
After its creation,
does correspond with an optimal solution.
After its creation, ![]() equals:
equals:
If the user is interested in finding multiple alternative solutions,
the search may proceed until ![]() contains no more nodes with a
contains no more nodes with a ![]() value that is not smaller than the maximum preference of the first
solution. In this case,
value that is not smaller than the maximum preference of the first
solution. In this case,
![]() and hence, there
is only one solution to this aDPCSP.
and hence, there
is only one solution to this aDPCSP.