


Next: Formal Concept Analysis
Up: Learning Concept Hierarchies from
Previous: Introduction
Overall Process
The overall process of automatically deriving concept hierarchies
from text is depicted in Figure 1. First, the corpus
is part-of-speech (POS) tagged1
using TreeTagger [53] and parsed using LoPar2
[54], thus yielding a parse tree for each sentence. Then,
verb/subject, verb/object and verb/prepositional phrase dependencies are
extracted from these parse trees. In particular, pairs are extracted
consisting of the verb and the head of the subject, object or prepositional
phrase they subcategorize. Then, the verb and the heads are lemmatized,
i.e. assigned to their base form. In order to address data sparseness,
the collection of pairs is smoothed, i.e. the frequency of pairs which
do not appear in the corpus is estimated on the basis of the frequency of
other pairs.
The pairs are then weighted according to some statistical measure and
only the pairs over a certain threshold are transformed into a formal
context to which Formal Concept Analysis is applied. The lattice
resulting from this, (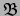 ,
,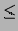 ), is transformed into a partial order
(
), is transformed into a partial order
( ,
,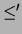 ) which is closer to a concept hierarchy in the
traditional sense. As FCA typically leads to a proliferation of concepts,
the partial order is compacted in a pruning step, removing abstract concepts and leading to a compacted partial order (
) which is closer to a concept hierarchy in the
traditional sense. As FCA typically leads to a proliferation of concepts,
the partial order is compacted in a pruning step, removing abstract concepts and leading to a compacted partial order ( ,
,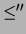 ) which is the resulting
concept hierarchy. This process is described in detail in Section
3. The process is described more formally by Algorithm 1.
) which is the resulting
concept hierarchy. This process is described in detail in Section
3. The process is described more formally by Algorithm 1.

Figure 1:
Overall
Process
 |
Next: Formal Concept Analysis
Up: Learning Concept Hierarchies from
Previous: Introduction
Philipp Cimiano
2005-08-04