|
|
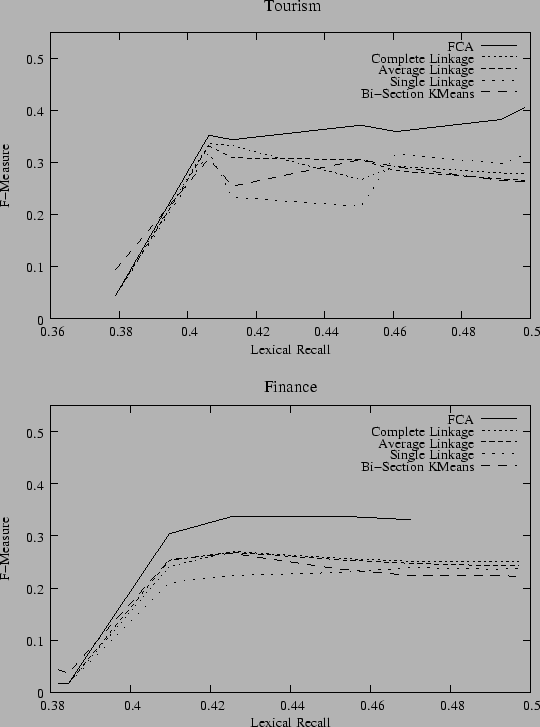
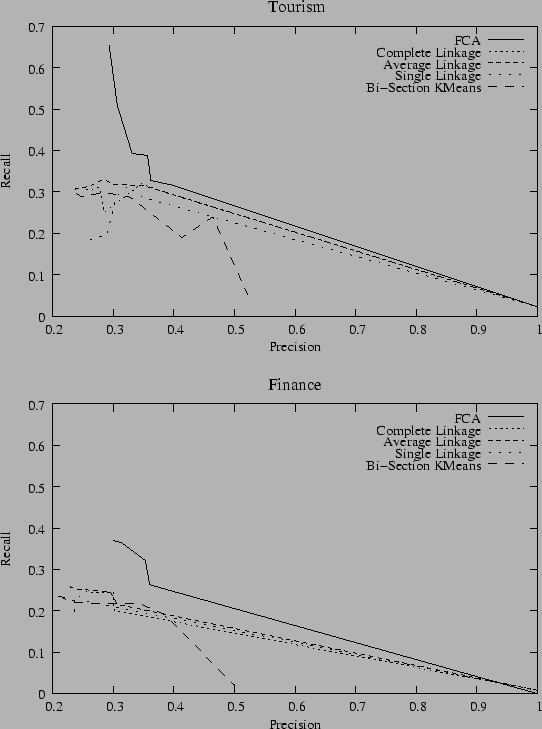
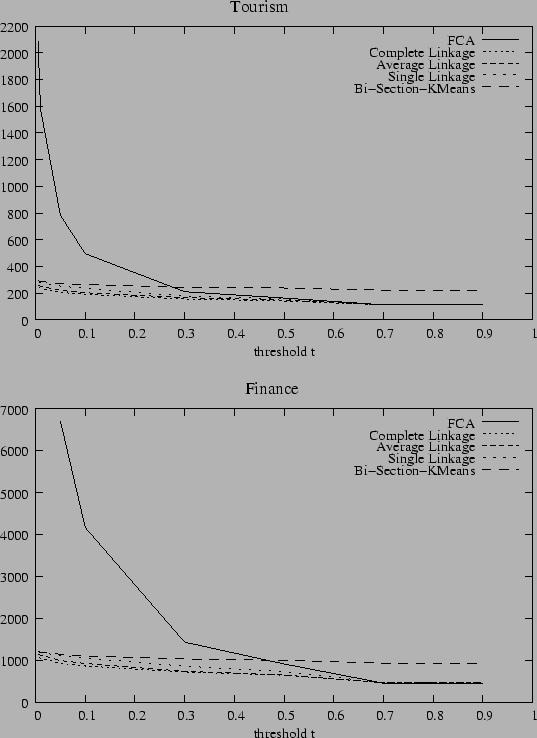
Tourism |
Finance |
|
|
P |
R |
F |
F' |
P |
R |
F |
F' |
|
FCA |
29.33% |
65.49% |
40.52% |
44.69% |
29.93% |
37.05% |
33.11% |
38.85% |
|
Complete Link |
34.67% |
31.98% |
33.27% |
36.85% |
24.56% |
25.65% |
25.09% |
33.35% |
|
Average Link |
35.21% |
31.45% |
33.23% |
36.55% |
29.51% |
24.65% |
26.86% |
32.92% |
|
Single Link |
34.78% |
28.71% |
31.46% |
38.57% |
25.23% |
22.44% |
23..75% |
32.15% |
|
Bi-Sec. KMeans |
32.85% |
28.71% |
30.64% |
36.42% |
34.41% |
21.77% |
26.67% |
32.77% |
|