The interaction between dynamics and reward certainly affects the
performance of the different approaches, though not so strikingly as
other factors such as the reward type (see below). We found that under
the same reward scheme, varying the degree of structure or uncertainty
did not generally change the relative success of the different
approaches. For instance, Figures 10 and 11 show the average run time of the methods as
a function of the degree of structure, resp. degree of uncertainty,
for random problems of size 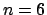 and reward
and reward
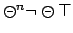 (the state encountered at stage
(the state encountered at stage  is rewarded,
regardless of its properties11).
Run-time increases slightly with both degrees, but there is no
significant change in relative performance. These are typical of the
graphs we obtain for other rewards.
Clearly, counterexamples to this observation exist. These are most
notable in cases of extreme dynamics, for instance with the
SPUDD-EXPON domain. Although for small values of , such as ,
PLTLSTR approaches are faster than the others in handling the
reward
for virtually any type of dynamics
we encountered, they perform very poorly with that reward on
SPUDD-EXPON. This is explained by the fact that only a small fraction
of SPUDD-EXPON states are reachable in the first steps. After
steps, FLTL immediately recognises that reward is of no consequence,
because the formula has progressed to
is rewarded,
regardless of its properties11).
Run-time increases slightly with both degrees, but there is no
significant change in relative performance. These are typical of the
graphs we obtain for other rewards.
Clearly, counterexamples to this observation exist. These are most
notable in cases of extreme dynamics, for instance with the
SPUDD-EXPON domain. Although for small values of , such as ,
PLTLSTR approaches are faster than the others in handling the
reward
for virtually any type of dynamics
we encountered, they perform very poorly with that reward on
SPUDD-EXPON. This is explained by the fact that only a small fraction
of SPUDD-EXPON states are reachable in the first steps. After
steps, FLTL immediately recognises that reward is of no consequence,
because the formula has progressed to  . PLTLMIN discovers
this fact only after expensive preprocessing. PLTLSTR, on the
other hand, remains concerned by the prospect of reward, just as
PLTLSIM would.
. PLTLMIN discovers
this fact only after expensive preprocessing. PLTLSTR, on the
other hand, remains concerned by the prospect of reward, just as
PLTLSIM would.
Figure 10:
Changing the Degree of Structure
|
![\includegraphics[width=0.65\textwidth]{figures/structure}](img388.png) |
Figure 11:
Changing the Degree of Uncertainty
|
![\includegraphics[width=0.65\textwidth]{figures/uncertainty}](img389.png) |
Sylvie Thiebaux
2006-01-20