


Our proposal of external validation criteria for clustering such as error rate and classification cost stem from a larger, often implicit, but long-standing bias of some in AI that learning systems should serve the ends of some artificial autonomous agent. Certainly, the COBWEB family of systems trace their ancestry to systems such as UNIMEM [Lebowitz, 1982] and CYRUS [Kolodner, 1983] in which autonomous agency was a primary theme, as it was in Fisher [1987a]; Anderson and Matessa's [1991] work expresses similar concerns. In short, the view that clustering is a means of organizing a memory of observations for an autonomous agent begs the question of which of the agent's tasks is memory organization intended to support? Pattern completion error rate and simplicity/cost seem to be obvious candidate criteria.
However, an underlying assumption of this article is that these
criteria are also appropriate for externally validating clusterings
used in data analysis contexts,
where the clustering is external to a human analyst, but is nonetheless
exploited by the analyst for purposes such as hypothesis generation.
Traditional criteria for cluster evaluation in such contexts include
measures of intra-cluster cohesion (i.e., observations within the
same clusters should be similar) and inter-cluster coupling
(i.e., observations in differing clusters should be dissimilar).
The criteria proposed in this article and traditional
criteria are certainly related. Consider the following
derivation of a portion of the category utility measure,
which begins with the expected number of variable values
that will be correctly predicted given that prediction is guided by
a clustering  :
:
The final steps of this derivation assume that a variable value is predicted with probability¯# of correct variable predictions

=
¯# of correct variable predictions

=
¯# of correct predictions of variable


=
¯# of times that
is correct prediction of
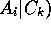
=

=

 and that with the
same probability this prediction is correct -- i.e., the
derivation of category utility assumes a probability matching
prediction strategy [Gluck & Corter,
1985; Corter & Gluck, 1992].
and that with the
same probability this prediction is correct -- i.e., the
derivation of category utility assumes a probability matching
prediction strategy [Gluck & Corter,
1985; Corter & Gluck, 1992]. By favoring partitions that improve prediction along many variables,
hierarchical clustering using
category utility tends to result in hierarchies
with more variable frontiers, as described in Section 4.1,
near the top of the clustering; this tends to reduce post-validation
classification cost.
By favoring partitions that improve prediction along many variables,
hierarchical clustering using
category utility tends to result in hierarchies
with more variable frontiers, as described in Section 4.1,
near the top of the clustering; this tends to reduce post-validation
classification cost.
Thus, category utility can be motivated as a measure
that rewards cohesion within clusters and decoupling across
clusters as noted in Section 2.1, or
as a measure motivated by a desire to reduce error rate
(and indirectly, classification cost).
In general, measures motivated by a desire to
reduce error rate will also favor cohesion and decoupling; this stems
from two aspects of the pattern-completion task [Lebowitz, 1982; Medin, 1983].
First, we
assign an observation to a cluster based on the known variable values
of the observation, which is best facilitated if variable value
predictiveness is high across many variables (i.e., clusters
are decoupled).
Having assigned an observation to a cluster,
we use the cluster's definition to predict the values of
variables that are not known from the observation's description.
This process is most successful when many variables are
predictable at clusters (i.e., clusters are cohesive).
In fact, designing measures with cohesion and decoupling in
mind undoubtedly results in useful clusterings
for purposes of pattern completion, whether or not this was
the explicit goal of the designer.
If external validation criteria of error rate and cost are well correlated with traditional criteria of cohesion and coupling, then why use the former criteria at all? In part, this stems from an AI and machine learning bias that systems should be designed and evaluated with a specific performance task in mind. In addition, however, a plethora of measures for assessing cohesion and coupling can be found, with each system assessed relative to some variant. This variation can make it more difficult to assess similarities and differences across systems. This article suggests pattern-completion error rate and cost as relatively unbiased alternatives for comparative studies. Inversely, why not use some direct measures of error rate and classification cost (e.g., using holdout) as an `objective function' to guide search through the space of clusterings? This can be expensive. Thus, we use a cheaply computed objective function that is designed with external error rate and cost evaluation in mind; undoubtedly, such an objective function reflects cohesion and coupling.
Of course, we have computed error rate and identified variable frontiers given a simplified performance task: each variable was independently masked and predicted over test observations. This is not an unreasonable generic method for computing error rate, but different domains may suggest different computations, since often many variables are simultaneously unknown and/or an analyst may be interested in a subset of the variables. In addition, we have proposed simplicity (i.e., the number of leaves) and expected classification cost as external validation criteria. Section 5.1 suggests that one of the latter criteria is probably necessary, in addition to error rate, to discriminate `good' and `poor' clusterings as judged by the objective function. In general, desirable realizations of error rate, simplicity, and cost will likely vary with domain and the interpretation tasks of an analyst.
In short, an analyst's task is largely one of making inferences from a clustering, for which there are error-rate and cost components (i.e., what information can an analyst glean from a clustering and how much work is required on the part of the analyst to extract this information). It is probably not the case that we have expressed these components in precisely the way that they are cognitively-implemented in an analyst. Nonetheless, this article and others [Fisher, 1987a; Cheeseman et al., 1988; Anderson & Matessa, 1991] can be viewed as attempts to formally, but tentatively describe an analyst's criteria for cluster evaluation, based on criteria that we might prescribe for an autonomous, artificial agent confronted with much the same task.
JAIR, 4